Twitter のタイムラインで流れる話題を AWS の AI サービスで分析してみる ~前編
Author : 松尾 将幸
こんにちは。Amazon Web Services Japan でアプリケーションエンジニアをしている松尾です。
私は 10 年ほど前から Twitter を使っているのですが、その間に色々なアカウントをフォローしたり、自分の興味が移りかわってきたこともあり、タイムラインがかなりカオスなことになっています。流れも速いので始めたばかりの頃のように全部の Tweet に目を通すということもできません。
そこで気になったのが、今の自分のタイムラインではどういった話題が多いのか、ポジティブな Tweet とネガティブな Tweet だとどちらが多いのか、ということです。今回、それを調べるためのシステムを AWS のサービスを使って構築してみようと思いました。
内容を簡単に説明しますと、Twitter の API を呼び出してタイムラインの Tweet を断続的に取得し、それを AWS の AI サービスの 1 つである Amazon Comprehend を使って分析し、結果を Amazon QuickSight を使ってグラフ化します。
早速ですが、こちらが完成イメージとなるグラフです。
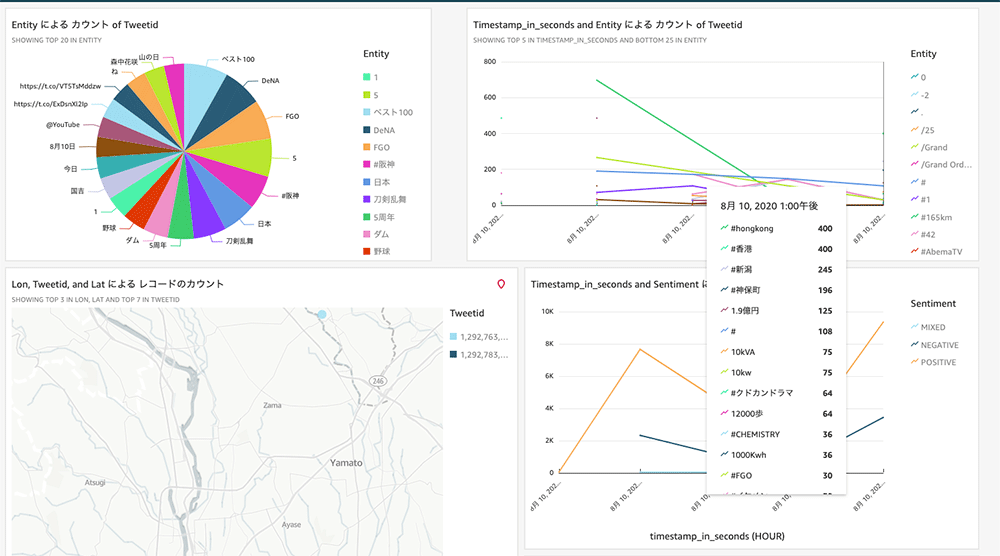
左上の話題をカテゴライズしたグラフを見ると、私のタイムラインは全般的にサブカル系の話題が多めだということが分かります。以前はプロ野球の阪神タイガースファンで、今は DeNA ベイスターズファンということが関係しているのか、「阪神」と「DeNA」の両方のキーワードが登場しています。この中で見覚えのないワードが出てくると、何かあったのかな、と少し好奇心が掻き立てられますね。
また、隠れて見えづらいですが、右下の感情分析グラフを見るとポジティブな内容が多いようです。ネガティブな内容が多ければフォローリストを整理しようかと思っていましたが、そうせずに済みそうです。
このように、タイムラインを分析してみることで、新たな気づきを得たり、自分が望む話題と実際のタイムラインとの解離具合を調べてみることができます。
というわけで、今回はこのタイムライン解析システムの構築方法をご紹介したいと思います。
と思ったら、すでに AWS Solutions というAWSが提供しているリファレンス実装の中に、似たようなソリューションが提供されていました。せっかくですので、これをベースにして、自分のタイムライン分析用のカスタマイズをしてみます。また、できるだけ手作業で構築することで作り方の理解を深めていきたいと思います。
なお、今回作るシステムでは、自分のタイムラインではなく他人のタイムラインを解析することも可能です。
目次
ご注意
本記事で紹介する AWS サービスを起動する際には、料金がかかります。builders.flash メールメンバー特典の、クラウドレシピ向けクレジットコードプレゼントの入手をお勧めします。
このクラウドレシピ (ハンズオン記事) を無料でお試しいただけます »
毎月提供されるクラウドレシピのアップデート情報とともに、クレジットコードを受け取ることができます。
1. アーキテクチャ
こちらは、今回のシステムのアーキテクチャを示した概要図です。
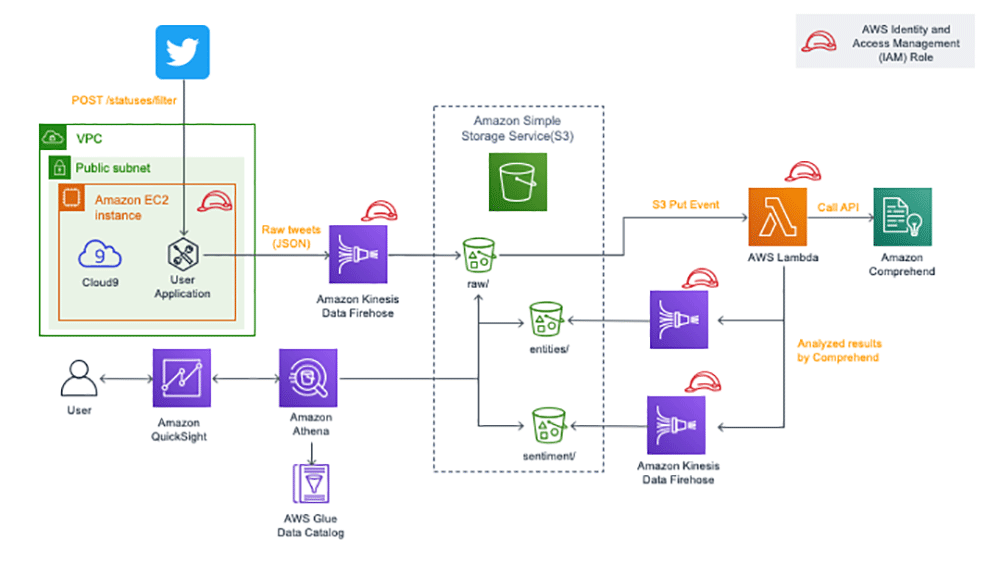
TwitterのAPI (statuses/filter) をからタイムラインの情報をJSON形式で取得し、それをAmazon Kinesis Data Firehose を介して Amazon S3 に格納します。
S3 に JSON ファイルが格納されたタイミングで、AWS Lambda の関数を介してファイルの中身を Comprehend に渡して解析を行います。
解析結果は再び Firehose を介して S3 に格納されます。これら S3 に格納されているファイルに対して、Amazon Athena、及び QuickSight で可視化する、というのが全体の流れです。
また、Twitter API と連携するアプリケーションは Amazon EC2 上のデーモンプロセスとして動かします。この EC2 環境を用意するために、今回は AWS Cloud9 を使っています。
それでは、ここからは構築手順について説明していきます。
2. 前準備 - Twitter の App を作成する
最初に、Twitter の API を実行するためのシークレット情報 (Consumer API keys, AccessToken, AccessTokenSecret) を取得します。
そのためには Twitter の開発者用サイトからTwitter App を作成する必要があります。まずはこちらのサイトを開いてください。
画面右上の Create an app をクリックしてみます。

クリックすると拡大します
もし、今までに Twitter App を作成したことが無ければ、開発者アカウントを申請する必要があります。
次のようなポップアップが表示されますので、Apply を押して次に進みます。

クリックすると拡大します
その先の画面で、Tweet データをどのように使うかなどを英語で答える必要がありますが、「自分のタイムラインの Tweet を AWS の AI サービスで解析するために使います」というような内容で回答すれば問題ないかと思います。「twitter developer account 申請」で検索すると参考になるサイトがヒットしますので、それらを見ながら回答すれば大丈夫です。
開発者アカウントの申請が完了していれば Twitter App を作成することができます。

クリックすると拡大します
入力必須項目が 4 つありますので任意の内容を入力してください。入力したら Create ボタンをクリックして作成完了させましょう。

クリックすると拡大します
無事に Twitter App が作成できれば、いよいよ API Key などを取得できます。Keys and tokens のタブを開きます。

クリックすると拡大します
Consumer API keys は最初から生成されています。Access token & access token secret は Generate ボタンをクリックして生成しましょう。
生成された Access Token と Secret が画面に表示されますが、後から見返すことはできませんので、どこかにメモしておきます。
生成が終われば、こちらのような表示になっているはずです。

クリックすると拡大します
3. Step 1 : データストアの構築
ここから AWS 上でシステムの構築を進めていきます。まずは AWS コンソールにアクセスしてください。
なお、以降の説明において、リージョンは バージニア北部(us-east-1) としています。もちろん東京リージョンなど、他のリージョンを使っていただいても構いません。
3-1. Amazon S3 バケットの作成
S3 のコンソール画面を開きます。
ここで、twitter-dashboard-(自分の名前など) という S3 バケットを 1 つ作成します。バケット名は AWS 全体で一意とする必要がありますので、重複しないような名称としてください。
まずは バケットを作成する のボタンをクリックします。

クリックすると拡大します
バケット名を入力し、次へをクリックします。

クリックすると拡大します
デフォルト暗号化 にチェックを入れ、次へ をクリックします。

クリックすると拡大します
ブロックパブリックアクセスはそのまま (全てブロック) として、 次へ をクリックします。

クリックすると拡大します
作成されるバケットの詳細が表示されますので、問題なければ バケットの作成 をクリックします。

クリックすると拡大します
この次の作業のために、バケットの ARN を控えておきます。
作成したバケットにチェックを入れ、 バケット ARNをコピーする をクリックし、どこかに貼り付けておきましょう。

クリックすると拡大します
ARN をメモしたら、次はバケットの中にフォルダを作成します。
フォルダの作成 ボタンをクリックし、以下の 3 つのフォルダを作成しましょう。
| 名前 | 用途 |
|---|---|
| raw | Twitter APIから取得したTweetデータをそのまま格納する |
| sentiment | Comprehendで分析した感情データを格納する |
| entities | Comprehendで分析したエンティティデータを格納する |

クリックすると拡大します

クリックすると拡大します
ここまでで、アーキテクチャのこちらの部分が完成しました。

クリックすると拡大します
3-2. Amazon Kinesis Data Firehose 用の IAM ロールを作成
次に Kinesis Data Firehoses の設定を進めたいのですが、まずは Kinesis Data Firehose に付与する IAM ロールをあらかじめ作成しておきます。
IAM のコンソールを開き、左のメニューから ロール を選択し、 ロールの作成 ボタンをクリックします。

クリックすると拡大します
信頼されたエンティティの種類を選択 画面では、まずサービスの中から Kinesis を選択します。

クリックすると拡大します
すると画面下に ユースケースの選択 が表示されますので、Kinesis Firehose を選択します。その後、次のステップ: アクセス権限 ボタンをクリックして次に進みます。

クリックすると拡大します
次の画面では手作業でポリシーを作成するため、ポリシーの作成 ボタンをクリックします。

クリックすると拡大します
JSON タブ を開き、以下の内容を貼り付け・編集します。
- <バケットの ARN> はメモしておいたものを使います。
- <リージョン (us-east-1 など)> はご自身の環境に合わせて置き換えてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"<バケットのARN>",
"<バケットのARN>/*"
]
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:DescribeLogStreams"
],
"Resource": [
"arn:aws:logs:<リージョン>:<AWSアカウントID>:log-group:/aws/kinesisfirehose/*"
]
}
]
}ポリシーの確認 画面では、名前を TwitterDashboard-Firehose-Policy (任意) と入力して ポリシーの作成 ボタンをクリックします。

クリックすると拡大します
再び IAM ロール作成画面に戻り、リフレッシュボタンをクリックした後に TwitterDashboard-Firehose-Policy を検索し、チェックします。
その後は 次のステップ ボタンをクリックして進みます。タグの画面での入力は任意です。特になければそのまま進んでください。

クリックすると拡大します
再び IAM ロール作成画面に戻り、リフレッシュボタンをクリックした後に TwitterDashboard-Firehose-Policy を検索し、チェックします。
その後は 次のステップ ボタンをクリックして進みます。タグの画面での入力は任意です。特になければそのまま進んでください。

クリックすると拡大します
再び IAM ロール作成画面に戻り、リフレッシュボタンをクリックした後に TwitterDashboard-Firehose-Policy を検索し、チェックします。
その後は 次のステップ ボタンをクリックして進みます。タグの画面での入力は任意です。特になければそのまま進んでください。

クリックすると拡大します
3-3. Amazon Kinesis Data Firehose の構築
次は、3 つの S3 バケット内フォルダと接続する 3 つの配信ストリームを、Kinesis Data Firehose を使って構築していきます。
まず Kinesis のコンソールを開きます。

クリックすると拡大します
トップ画面右側の 今すぐ始める の中で Kinesis Data Firehose を選択し、配信ストリームを作成 のボタンをクリックします。

クリックすると拡大します
作成画面に遷移しますので、Delivery stream name に Twitter-Dashboard-Raw (任意) と入力して Next ボタンをクリックします。

クリックすると拡大します
作成画面に遷移しますので、Delivery stream name に Twitter-Dashboard-Raw (任意) と入力して Next ボタンをクリックします。

クリックすると拡大します
その下の S3 bucket では Step 3-1. で作成したバケットを選択し、 S3 Prefix には raw/ を入力してください。最後のスラッシュは重要ですので忘れないようにしてください。
それが終わったら Next ボタンをクリックして進みます。

クリックすると拡大します
Configure settings の画面では S3 buffer conditions の Buffer interval を 60 に変更しておきます。

クリックすると拡大します
画面下の Permissions では Choose existing IAM role をチェックし、前の項で作成しておいた TwitterDashboard-Firehose を選択します。
選択したら Next ボタンをクリックして進みます。

クリックすると拡大します
最後の Review の画面は、問題なければ Create delivery stream ボタンをクリックし、ストリームを作成します。

クリックすると拡大します
作成が完了したら配信ストリーム一覧の画面に遷移します。
しばらくは作ったばかりのストリームの Status 欄が Creating になっていますが、少し待つと Active に変わります。

クリックすると拡大します
ここまでと同じ手順で、次の 2 つの配信ストリームも作成します。
S3 Prefix が、それぞれ sentiment/ 、entities/ に変わる以外は全く同じ内容で問題ありません。
- Twitter-Dashboard-Sentiment
- Twitter-Dashboard-Entities
Twitter-Dashboard-Raw の ARN は、この先のステップで必要になりますので、控えておきます。

クリックすると拡大します
ここまでの作業で、こちらの部分まで完成しました。

クリックすると拡大します
3-4. AWS Secrets Manager に機密情報を設定
ここからはデータストアのメインとなる、データ取得アプリケーションを作成していきます。
まずは AWS Secrets Manager に Twitter App のシークレット情報を登録します。
こうしておくことで、アプリケーションから Secrets Manager の API を呼び出すと機密情報を取得することができ、ソースコードにアクセストークンなどをハードコーディングしなくても良くなります。
早速 Secrets Manager のコンソールに移動しましょう。

クリックすると拡大します
新しいシークレットを保存する のボタンをクリックします。

クリックすると拡大します
シークレットの種類を選択 では その他のシークレット を選びます。

クリックすると拡大します
そのまま シークレットキー/値 に以下の 4 種類の Twitter シークレット値を入力します。
| キー名 | 内容 (前準備で控えていた値を入れます) |
|---|---|
| ConsumerApiKey | Twitter AppのAPI key |
| ConsumerApiSecret | Twitter AppのAPI secret key |
| AccessToken | Twitter AppのAccess token |
| AccessTokenSecret | Twitter AppのAccess token secret |
入力が終わったら 次へ ボタンをクリックして進みます。

クリックすると拡大します
シークレットの名前 に TwitterAPI-Secrets と入力し、次へ ボタンをクリックします。

クリックすると拡大します
自動ローテーション はデフォルトのままで 次へ をクリックし、最後のレビューの画面で 保存 をクリックします。問題なければ保存に成功し、以下の表示になります。
また、作成したシークレットの ARN は次の作業で必要になりますので、手元に控えておきます。

クリックすると拡大します
3--5. アプリケーションの実行基盤を準備 (VPC 編)
シークレットの登録ができたら、アプリケーションの実行基盤を用意して、その上でアプリケーションを動かすための作業に取り掛かります。
今回は EC2 インスタンスを一台起動し、その上でデーモンプロセスを動かし、Twitter の filter API から断続的に Tweet 情報を取り込む形にします。それに先駆けて VPC と IAM ロールの準備が必要になりますが、ここは楽をするために CloudFormation で構築してみたいと思います。
CloudFormation のコンソールにアクセスしてみましょう。
コンソール画面では スタックの作成 を押して作成画面に進みます。

クリックすると拡大します
テンプレートの準備完了 と テンプレートファイルのアップロード をチェックし、サンプルソースコードの deployment/template.yaml をアップロードします。

クリックすると拡大します
アップロードができたら、次へ を押して先に進みます。スタックの名前 は Twitter-Dashboard-VPC(任意) としておきます。
パラメータの TweetFirehoseStreamArn に Firehose で配信ストリームを作成した時に控えた ARN を、TwitterAPISecretsArn には Secrets Manager でシークレットを作成した時に控えた ARN をそれぞれ入力します。
入力が終わったら 次へ を押して進みます。

クリックすると拡大します
スタックオプションの設定 画面はデフォルトのままで 次へ を押して進みます。
レビュー の画面で問題なければ、 「AWS CloudFormation によって IAM リソースが作成される場合があることを承認します。」 に忘れずにチェックを入れて、スタックの作成 を押します。

クリックすると拡大します
スタックのステータスが CREATE_IN_PROGRESS となりますので、これが CREATE_COMPLETE になるまで待ちます。

クリックすると拡大します
これで VPC と IAM ロールが作成されました。
作成されたリソースの詳細は リソース タブを開くことで確認できます。
3-6. アプリケーションの実行基盤を準備 (EC2 編)
次は EC2 インスタンスを構築します。
EC2 コンソールから 1 台作成して SSH 接続しても良いのですが、アプリケーションのコーディングを簡単に行うために、Cloud9 を使って EC2 インスタンス作成と開発環境の整備をまとめて実施してしまいます。
まず Cloud9 のコンソールに移動して Create environment のボタンを押して先に進みます。

クリックすると拡大します
Name は Twitter-Dashboard-Server としておき、Next Step のボタンを押します。

クリックすると拡大します
Configure settings の画面では Network settings (advanced) をクリックして開きます。

クリックすると拡大します
ここで先ほど CloudFormation で作成した VPC、およびサブネットを選択し、Next Step で進みます。
作成された VPC が分からない場合は、CloudFormation のコンソールを別のタブで開き、作成したスタックのリソースタブを見ると、VPC の物理 ID が記載されていますので参照してください。

クリックすると拡大します
確認画面に遷移しますので、そのまま Create Environment ボタンを押して Cloud9 環境を作成します。

クリックすると拡大します
確認画面に遷移しますので、そのまま Create Environment ボタンを押して Cloud9 環境を作成します。

クリックすると拡大します
画面操作が可能になったら Cloud9 の基盤となっている EC2 も起動していますので、EC2 のコンソール画面に移動します。

クリックすると拡大します
実行中のインスタンス や左メニューの インスタンス などをクリックしてインスタンスの一覧画面に移動します。
作成された EC2 インスタンスがありますので、チェックを入れて アクション > インスタンスの設定 > IAM ロールの割り当て・置換 を選びます。

クリックすると拡大します
IAM ロールに CloudFormation で作成したものを選択して 適用 を押します。成功したら 閉じる を押して戻ります。

クリックすると拡大します
これで EC2 の準備は完了です。
3-7. Twitter からデータを収集するアプリケーションを作成
先ほど立ち上げた Cloud9 を使って、アプリケーションコードを書き、デーモンプロセスとして動かします。
まずは Cloud9 の画面に戻ります。
それから左のファイルツリーでマウスを右クリックしてメニューを開き、New File を選択します。

クリックすると拡大します
新しいファイルが作られますので、twitter_reader.js という名前にします。

クリックすると拡大します
作成したファイルをダブルクリックして開きます。その中に、以下のコードを書いてください。
<ユーザ名> は自分の Twitter アカウント名、もしくは分析してみたい別のアカウント名に置き換えてください。
サンプルコードの source/twitter_reader.js にも同じ内容を書いていますので、そちらをアップロードしていただいても大丈夫です。
const AWS = require('aws-sdk');
const Twitter = require('twitter-lite');
/////////////////// 環境設定 ///////////////////////
const twitterUserName = "<ユーザ名>"; // タイムラインを取得したいTwitterユーザ名
const region = "us-east-1"; // 利用しているリージョン
const deliveryStreamName = "Twitter-Dashboard-Raw";
const secretName = "TwitterAPISecrets";
////////////////////////////////////////////////////
const firehose = new AWS.Firehose({apiVersion: '2015-08-04', region: region });
const secretsManager = new AWS.SecretsManager({ region: region });
async function getSecrets() {
const data = await secretsManager.getSecretValue({SecretId: secretName}).promise();
return JSON.parse(data.SecretString);
}
async function putRecordToFirehose(tweet) {
const recordParams = {
DeliveryStreamName: deliveryStreamName,
Record: {
Data: JSON.stringify(tweet) +'\n'
}
};
await firehose.putRecord(recordParams).promise();
}
async function main() {
try{
const secrets = await getSecrets();
const twitter = new Twitter({
consumer_key: secrets.ConsumerApiKey,
consumer_secret: secrets.ConsumerApiSecret,
access_token_key: secrets.AccessToken,
access_token_secret: secrets.AccessTokenSecret
});
// Twitterのfilter APIでタイムラインの情報を取得するため、
// まず、twitterUserNameで指定したユーザがフォローしているユーザのID一覧を取得しています。
const followIds = await twitter.get("friends/ids", {screen_name: twitterUserName, count: 5000});
// Tweetを断続的に取得します。取得に成功した場合は"data"に書いた処理が実行されます。
twitter.stream("statuses/filter", { follow: followIds.ids.join(",") })
.on("start", _ => console.log("start"))
.on("data", putRecordToFirehose)
.on("error", error => console.log("error", error))
.on("end", _ => console.log("end"));
} catch (e) {
console.log(e);
}
}
main();書き終わったら、Cloud9 の画面下部にあるターミナルをフォーカスし、コマンドを打ち込んでいきます。

クリックすると拡大します
ライブラリをインストールするため、以下のコマンドを実行してください。
$ npm init # 質問は全てEnterで飛ばしても大丈夫です。
$ npm i aws-sdk
$ npm i twitter-lite次にアプリケーションをデーモンとして動かす準備をします。
/etc/init/twitter_reader.conf を Vim などのエディタでオープンし、以下の内容を貼り付けてください。
サンプルコードの source/twitter_reader.conf をアップロードし、mv コマンドなどで置いても大丈夫です。
start on (runlevel [345] and started network)
stop on (runlevel [!345] or stopping network)
respawn
exec /usr/bin/node /home/ec2-user/environment/twitter_reader.js次に以下のコマンドを実行します。最後のコマンドで start/running と表示されていれば問題ありません。
$ sudo su -
# initctl reload-configuration
# initctl list | grep twitter
twitter-reader stop/waiting
# initctl start twitter-reader
twitter-reader start/running, process 5949 # プロセスIDは環境で変わります。
# initctl list | grep twitter
twitter-reader start/running, process 5949これで Twitter API からリアルタイムで流れてくる TweetをFirehose に流し込むデーモンが起動しました。
ちなみに、プロセス ID に対して kill コマンドを実行しても、自動で再起動して動き始めます。
また、今回は Cloud9 環境をそのままサーバーとして使っていますが、Cloud9 は未使用だと EC2 を Stop させる仕様になっているため、それを無効化しておきます。
画面左上の雲のアイコンをクリックして Preferences を選択し、EC2 Instance > Stop my environment を Never に設定します。

クリックすると拡大します
このあと数分待てば、図のように S3 バケットの raw フォルダの中にどんどんファイルが作られていくはずです。
もし何も作られないようであれば、CloudWatch のログや、ここまでの手順を再確認してください。

クリックすると拡大します
このあと数分待てば、図のように S3 バケットの raw フォルダの中にどんどんファイルが作られていくはずです。
もし何も作られないようであれば、CloudWatch のログや、ここまでの手順を再確認してください。

クリックすると拡大します
筆者プロフィール

松尾 将幸 (まつお まさゆき)
アマゾン ウェブ サービス ジャパン合同会社
アプリケーションエンジニア
SIer で働く SE として IT 業界入りし、人材サービス会社やメガベンチャーの内製エンジニアを経て 2019 年に AWS に入社。
入社してからはプロトタイピング ソリューションアーキテクトとしてお客様のクラウド利用促進に従事。その後、社内異動制度を使って再びソフトウェアエンジニア職に。
趣味はランニングとアニメ、漫画を見ること。野球も好き。(DeNA ベイスターズファン)
さらに最新記事・デベロッパー向けイベントを検索
AWS を無料でお試しいただけます