Doorman
インスピレーション
当社では多くの人がリモート、あるいは複数の場所にあるオフィスで働いています。そのため、ある人が今アクティブ/連絡可能かどうか、その人がどの場所にいるのかを判断するのが非常に難しい場合があります。ステータスをアクティブに変更するのを忘れる場合もあります。複数の地域やタイムゾーンにも対応する必要があります。
また当社では、自分がどこにいるか (在宅勤務かオフィスか、オフィスならばどのオフィスか) を知らせるために Slack のパーソナルステータスメッセージを使用しています。
そこで DeepLens の登場です。どこのオフィスでも、オフィスに入れば自分のことが認識され、Slack でアクティブとマークされるようになり、どのオフィスにいるかがステータスに設定されるようにすれば非常に便利ではないでしょうか。
機能
- オフィスに入室する人を検知する
- 人物の検出を試行する
- 誰なのかが特定されると、Slack に「Welcome @svdgraaf!」という歓迎メッセージが表示される
- 誰なのかが特定できない場合は、Slack で「Who is this?」と質問され、 どのユーザーかを選択できる
- 認識対象にしない人物の場合 (クライアントや Slack を使用しないユーザーなど)、「ignore」を選択でき、画像は S3 から削除される
- その後、その情報が Rekognition API に保存される
次回その人物が特定されると Slack チャネルに注記される
未実装の機能:
- その人物を Slack でアクティブとして表示する
- Slack でその人物のステータスを設定する
- Polly で発話させる (デバイスでまだ動作させられていない)
作成者: Sander van de Graaf


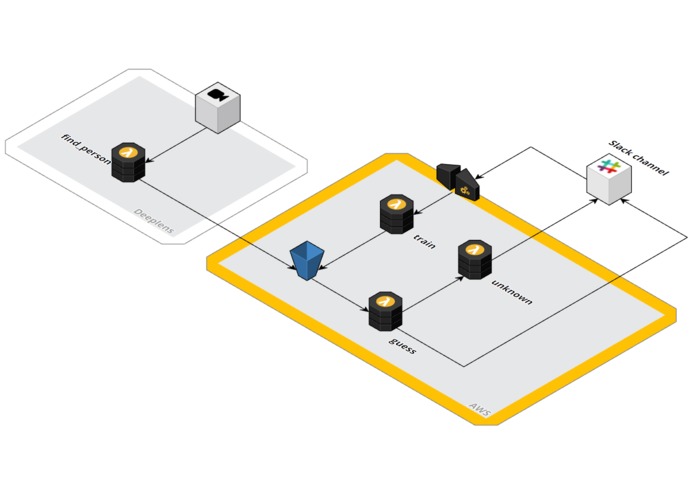
構築方法
サーバーレスを使用して構築しました。Lambda 関数のデプロイが非常に簡単でした。独自のモデル構築に挑戦しましたが失敗しました (EC2 インスタンスのトレーニングコストも心配でした)。最終的には、カスタムモデルではなく deeplens-object-detection モデルを使用することにし、「人物」オブジェクトのチェックをオンにしました。
仕組み: DeepLens によって、入室してきたオブジェクトが検出されます。人物が検出された場合は、その部分のスナップショットが作成され、S3 にアップロードされます。これにより guess 関数がトリガーされ、人物の認識が試行されます。既知の人物であれば、Slack API がコールされます。未知の人物の場合も、Slack がコールされます。利用者はチャネルの中で未知の人物を特定のユーザーへ関連付けるようトレーニングでき、画像のトレーニングのために API Gateway が呼び出されます。
上の画像スライド内のアーキテクチャ図をご覧ください。
課題
DeepLens: うまく動作していると思っていたら、翌日にはうまくいかないということがありました。Ubuntu の自動更新機能は途中まではうまく動作していました。また、DeepLens で同時に複数の Lambda 関数を実行できるとわかるまでにいくらか時間がかかりました。衝撃的な発見でした。
プライバシーの問題 (時間の設定とコントロール): テストから外してほしいと要請してきた同僚がいました。その気持ちはよくわかります。幸い、これは単なる PoC で、お遊び的なものでしたが、この種のテクノロジーに伴うプライバシーの不安について意義深い会話や議論を行うきっかけになりました。最終的には、08:00~10:00 のみ検出を実行するようタイマーを設定しました。
Slack API (非常に短いタイムアウト): Slack API では数ミリ秒以内の応答が必要であり、そうでなければ動作しないということを苦労して学びました。すべてを正しく動作させるために、もう一度非同期的にコールする方法に落ち着きました。
Polly: MP3 の生成準備はできていて、ローカルでの再生はうまくいっています。これを DeepLens で再生する方法がまだわかりません。
成果
もちろん、成功したことです。 サーバーを動作させることなく、すべての Lambda 関数が相互にトリガーしてその役目を果たしていくのを見るのは実にクールな体験です。ほんとうにすばらしいと思います。
学んだこと
- Greengrass
- Slack API
- OpenCV
- Polly
次のステップ
S3 アップロードの非同期化: 現在、S3 アップロードはブロックしています。同じ人物の画像が大量にアップロードされることがないので、それ自体は問題ありません。しかし、一時的にストリームを滞らせてしまいます。今構想しているのは、ファイルをどこかのローカル (一時) フォルダに書き込み、別の Lambda 関数でそれらをアップロードさせることです。または、デバイスで直接顔を検出できればもっとよいでしょう。
複数回トリガーの防止: 人がカメラの前をゆっくり通過したり、数分以内に戻っていったりした場合には、Slack に複数の投稿が表示されます。ある人物が最後に検出された日付と時刻を Dynamo に保存し、一定時間内に同じ人が検出された場合には Slack に投稿しないという機能を追加するつもりです。
デバイスでの顔検出: これをデバイスで直接動作させられるようにするだけの時間が自分にあればと思います。
Slack アプリケーションの公開: 現状では、この統合を動作させるためには独自の開発版 Slack アプリケーションをセットアップすることが必要です。自分のアプリケーションを公開し、適切なアプリケーションをポイントできればすばらしいでしょう。
Amazon Polly の追加: これまでも Polly API に取り組み、MP3 の生成は動作させられましたが、現在のところ MP3 を DeepLens で再生する方法が見つかっていません。発話者なら複数用意できます。
人をアクティブとしてマークする: 現在のところ、Slack API 経由では、ユーザー本人からの明示的な許可なしにその人をアクティブとしてマークすることが許可されていません。同僚への強制はしたくないので、この機能はまだ追加されていません。
人物のステータスのマーク:上記同様、エンドユーザーが個別に承認する必要があります。現在のオフィスの場所をステータス内でマークできれば便利だと思います。
使用したもの:
Python
DeepLens
Rekognition
サーバーレス
Polly