What is Amazon SageMaker Inference? (Amazon SageMaker Inference とは)
Amazon SageMaker AI を利用すると、基盤モデル (FM) を含む ML モデルをより簡単にデプロイして、どのようなユースケースでも最高のコストパフォーマンスで推論リクエストを実行できます。低レイテンシーで高スループットな推論から長時間実行の推論まで、SageMaker AI はあらゆる推論ニーズに対応できます。SageMaker AI はフルマネージドサービスであり、MLOps ツールと統合されているため、デプロイモデルのスケール、推論コストの削減、本番環境でのモデルの効果的な管理、運用上の負担の軽減が可能になります。
SageMaker Inference の利点
幅広い推論オプション
リアルタイム推論
サーバーレス推論
非同期推論
バッチ変換
スケーラブルで費用対効果の高い推論オプション
単一モデルのエンドポイント
専有インスタンスでホストされるコンテナ上の 1 つのモデル、または低レイテンシーと高スループットを実現するサーバーレスモデル。
単一のエンドポイントに複数のモデルをデプロイする
複数のモデルを同じインスタンスにホストして、基盤となるアクセラレーターをより効果的に活用し、デプロイコストを最大 50% 削減できます。各 FM のスケーリングポリシーを個別に制御できるため、インフラストラクチャコストを最適化しながら、モデルの使用パターンに適応することが容易になります。
シリアル推論パイプライン
複数のコンテナが専有インスタンスを共有し、順番に実行されます。推論パイプラインを使用して、前処理、予測、および後処理のデータサイエンスタスクを組み合わせることができます。
ほとんどの機械学習フレームワークとモデルサーバーをサポート
Amazon SageMaker 推論は、TensorFlow、PyTorch、ONNX、XGBoost などの最も一般的な機械学習フレームワークの組み込みアルゴリズムと事前構築済みの Docker イメージをサポートしています。事前構築済みの Docker イメージがどれもニーズに合わない場合は、CPU ベースのマルチモデルエンドポイントで使用する独自のコンテナを構築できます。SageMaker 推論は、TensorFlow Serving、TorchServe、NVIDIA Triton、AWS マルチモデルサーバーなど、ほとんどの一般的なモデルサーバーをサポートしています。
Amazon SageMaker AI には、モデル並列処理と大規模モデル推論 (LMI) に特化した深層学習コンテナ (DLC)、ライブラリ、ツールが用意されており、基礎モデルのパフォーマンスを向上させるのに役立ちます。これらのオプションを使用すると、基盤モデル (FM) を含むモデルを事実上あらゆるユースケースに迅速にデプロイできます。



低コストで高い推論パフォーマンスを実現
低コストで高い推論パフォーマンスを実現
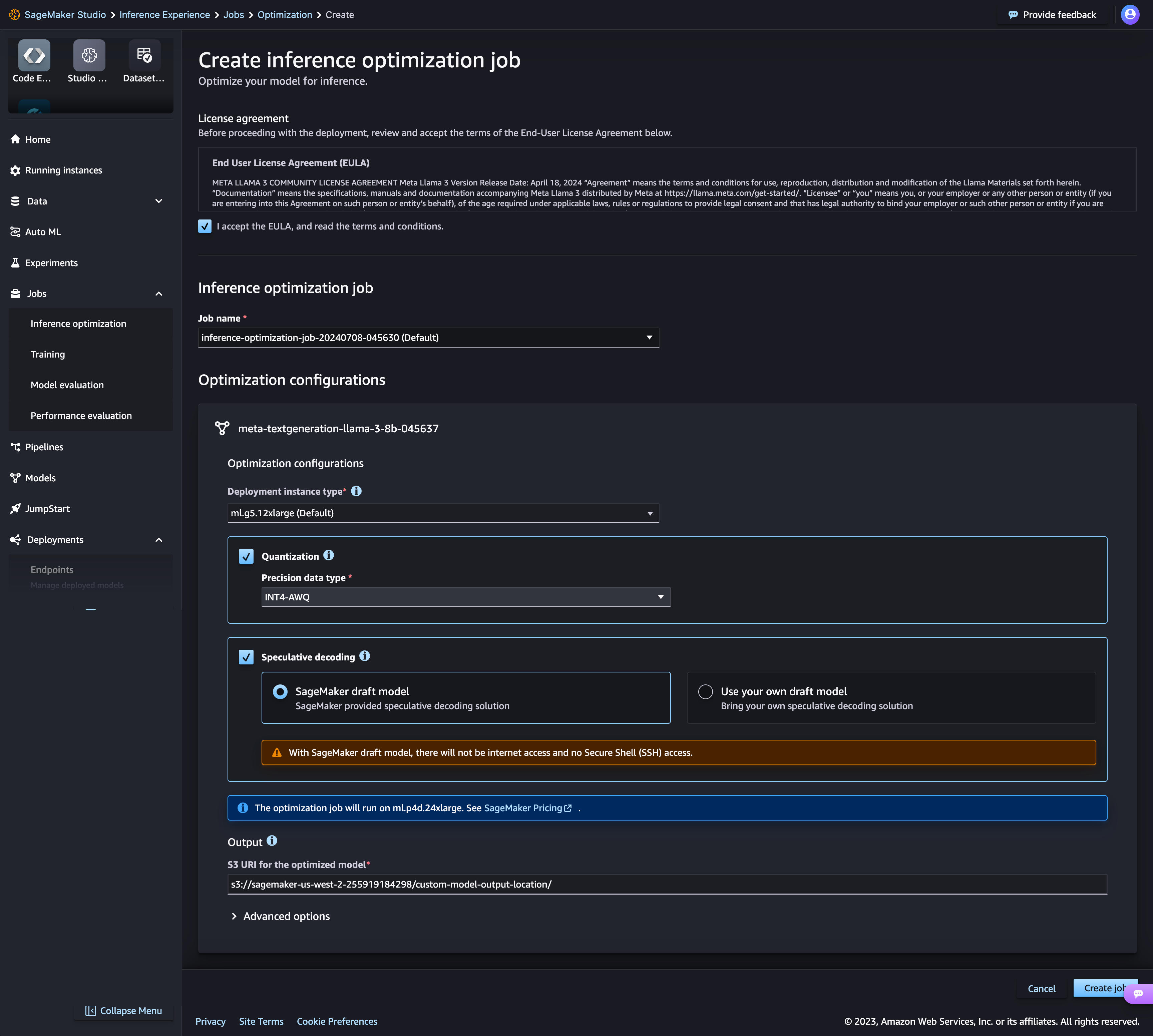
Amazon SageMaker AI の新しい推論最適化ツールキットは、Llama 3、Mistral、Mixtral モデルなどの生成 AI モデルのコストを最大 50% 削減しながら、最大 2 倍のスループットを実現します。例えば、Llama 3-70B モデルを使用すると、ml.p5.48xlarge インスタンスで最大約 2,400 トークン/秒を達成できます (以前は最適化なしで約 1,200 トークン/秒)。投機的デコード、量子化、コンパイルなどのモデル最適化手法を選択したり、複数の手法を組み合わせたりして、それらをモデルに適用し、ベンチマークを実行してその手法が出力の質と推論パフォーマンスに及ぼす影響を評価できるほか、わずか数回クリックするだけでモデルをデプロイすることもできます。
最もパフォーマンスの高いインフラストラクチャにモデルをデプロイするか、サーバーレスに移行するか
Amazon SageMaker AI には、AWS Inferentia に基づく Amazon EC2 Inf1 インスタンス、AWS によって設計および構築された高性能な ML 推論チップ、Amazon EC2 G4dn などの GPU インスタンスなど、さまざまなレベルのコンピューティングとメモリを備えた 70 種類以上のインスタンスタイプが用意されています。または、Amazon SageMaker Serverless Inference を選択すれば、1 エンドポイントあたり数千のモデル、1 秒あたりの数百万のトランザクション (TPS) スループット、10 ミリ秒未満のオーバーヘッドレイテンシーに簡単にスケーリングできます。

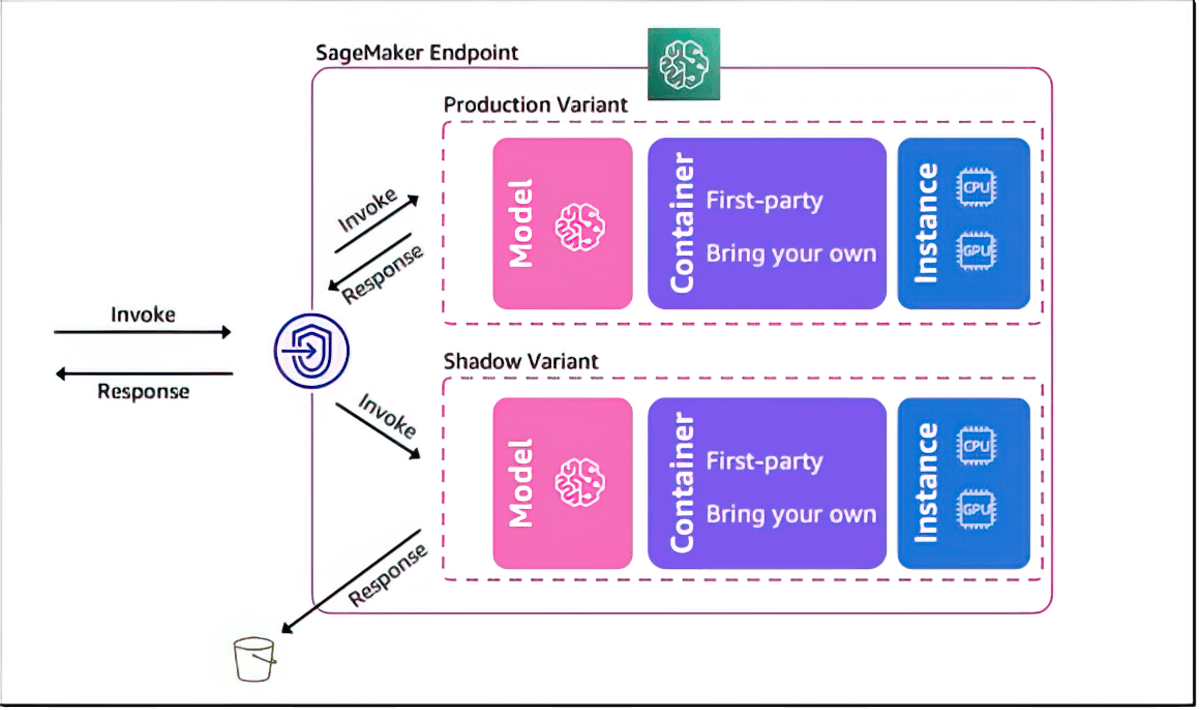
ML モデルのパフォーマンスを検証するためのシャドーテスト
Amazon SageMaker AI では、ライブ推論リクエストを使用して、現在 SageMaker がデプロイしているモデルに対してパフォーマンスをシャドウテストすることで、新しいモデルを評価できます。シャドウテストは、潜在的な設定エラーやパフォーマンスの問題を、エンドユーザーに影響を与える前に発見するのに役立ちます。ユーザーに影響を与える前に発見するのに役立ちます。SageMaker AI を使えば、何週間もの時間をかけて独自のシャドウテストインフラストラクチャを構築する必要がありません。テスト対象の本番モデルを選択するだけで、SageMaker AI は自動的に新しいモデルをシャドウモードでデプロイし、実稼働モデルで受信した推論要求のコピーをリアルタイムで新しいモデルにルーティングします。
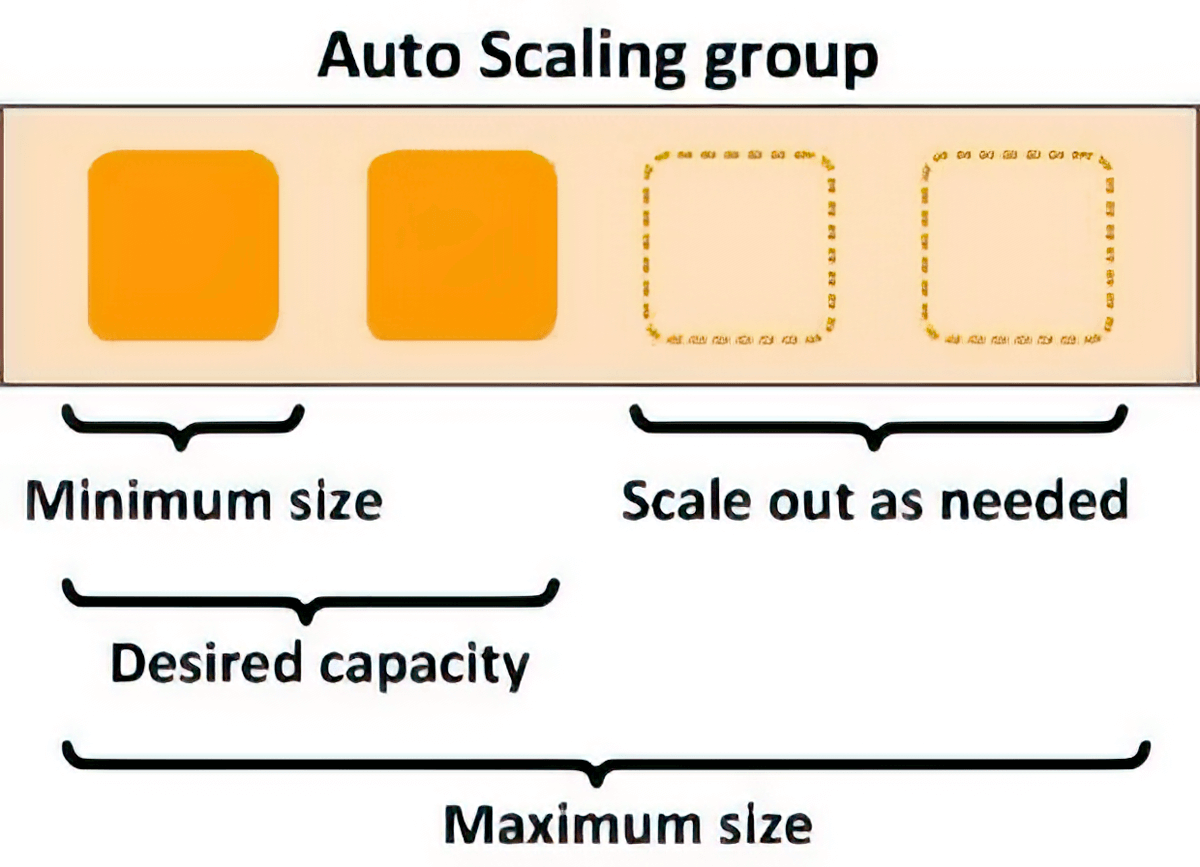
伸縮性を実現する自動スケーリング
スケーリングポリシーを使用すると、基盤となるコンピューティングリソースを自動的にスケーリングして、推論リクエストの変動に対応できます。各 ML モデルのスケーリングポリシーを個別に制御して、モデルの使用状況の変化に簡単に対処できると同時に、インフラストラクチャのコストを最適化できます。
レイテンシーの改善とインテリジェントルーティング
推論リクエストの処理で負荷がかかっているインスタンスにランダムにリクエストをルーティングするのではなく、使用可能なインスタンスに新しい推論リクエストをインテリジェントにルーティングすることで、ML モデルの推論レイテンシーを平均 20% 削減できます。
運用上の負担を軽減し、価値実現までの時間を短縮
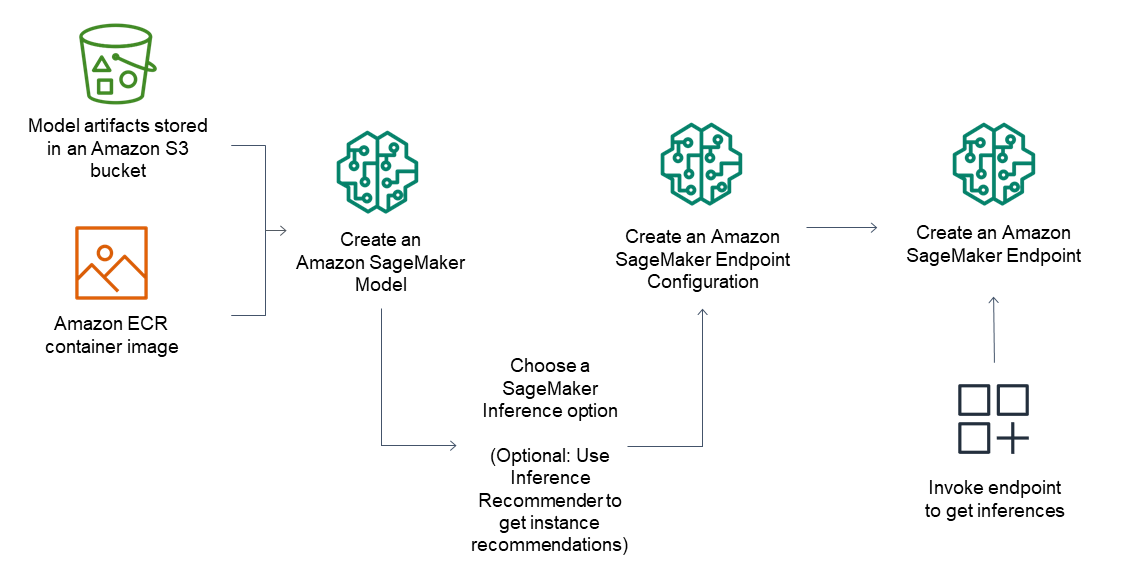
フルマネージドモデルのホスティングと管理
Amazon SageMaker AI は、完全マネージド型サービスとして、インスタンスのセットアップと管理、ソフトウェアバージョンの互換性、バージョンへのパッチ適用を行います。また、アラートの監視と受信に使用できるエンドポイントのメトリクスとログも組み込まれています。
MLOps 機能との組み込み統合
SageMaker Pipelines (ワークフローのオートメーションとオーケストレーション)、SageMaker Projects (ML の CI/CD)、SageMaker Feature Store (特徴量の管理)、SageMaker Model Registry (リネージを追跡し、自動化された承認ワークフローをサポートするモデルとアーティファクトのカタログ)、SageMaker Clarify (バイアスの検出)、SageMaker Model Monitor (モデルとコンセプトのドリフト検出) など、Amazon SageMaker AI のモデルデプロイ機能は、MLOps 機能とネイティブに統合されます。その結果、1 つのモデルをデプロイする場合でも、数万のモデルをデプロイする場合でも、SageMaker AI は ML モデルのデプロイ、スケーリング、管理による運用上のオーバーヘッドを軽減し、より早く本番環境に移行できるようにします。
お客様



SageMaker Inference のリソース
最新情報
Total results: 431
- 日付 (新しい順)
-
2025/01/30
-
2024/12/11
-
2024/12/06
-
2024/12/06
-
2024/12/04