AWS News Blog
Amazon S3 Update: New Storage Class and General Availability of S3 Select
I’ve got two big pieces of news for anyone who stores and retrieves data in Amazon Simple Storage Service (Amazon S3):
New S3 One Zone-IA Storage Class – This new storage class is 20% less expensive than the existing Standard-IA storage class. It is designed to be used to store data that does not need the extra level of protection provided by geographic redundancy.
General Availability of S3 Select – This unique retrieval option lets you retrieve subsets of data from S3 objects using simple SQL expressions, with the possibility for a 400% performance improvement in the process.
Let’s take a look at both!
S3 One Zone-IA (Infrequent Access) Storage Class
This new storage class stores data in a single AWS Availability Zone and is designed to provide eleven 9’s (99.99999999%) of data durability, just like the other S3 storage classes. Unlike those other classes, it is not designed to be resilient to the physical loss of an AZ due to major event such as an earthquake or a flood, and data could be lost in the unlikely event that an AZ is destroyed. S3 One Zone-IA storage gives you a lower cost option for secondary backups of on-premises data and for data that can be easily re-created. You can also use it as the target of S3 Cross-Region Replication from another AWS region.
You can specify the use of S3 One Zone-IA storage when you upload a new object to S3:
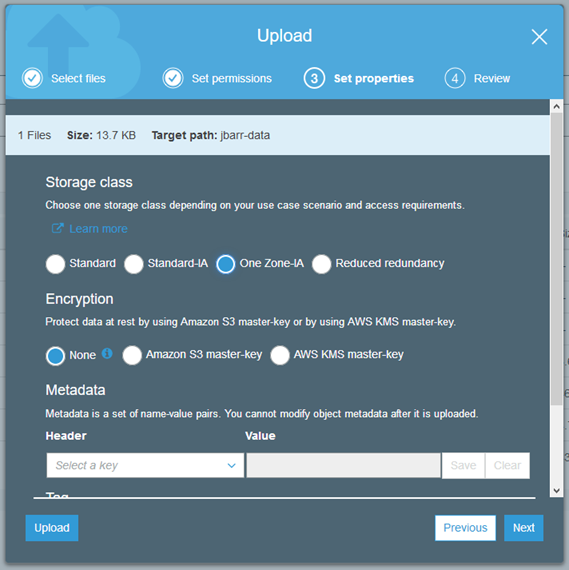
You can also make use of it as part of an S3 lifecycle rule:
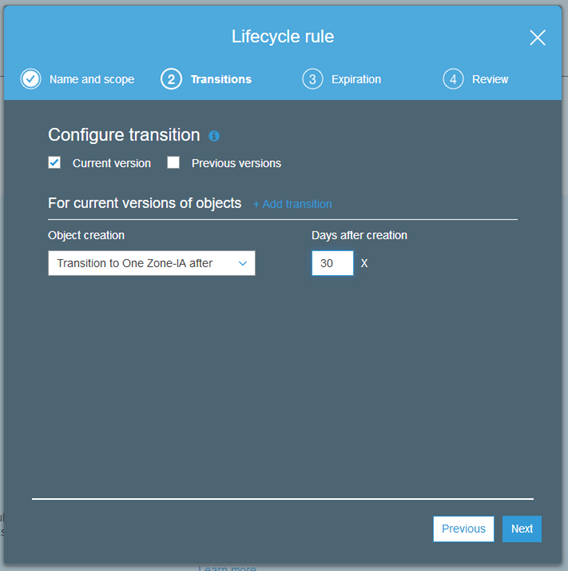
You can set up a lifecycle rule that moves previous versions of an object to S3 One Zone-IA after 30 or more days:
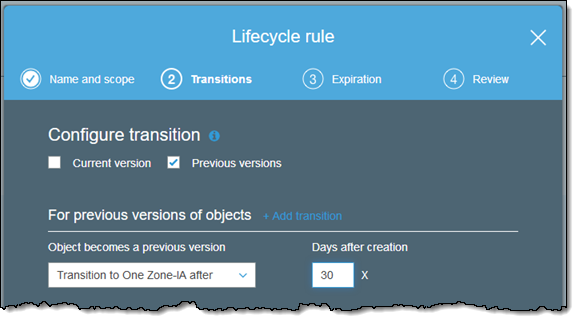
And you can modify the storage class of an existing object:

You can also manage storage classes using the S3 API, CLI, and CloudFormation templates.
The S3 One Zone-IA storage class can be used in all public AWS regions. As I noted earlier, pricing is 20% lower than for the S3 Standard-IA storage class (see the S3 Pricing page for more info). There’s a 30 day minimum retention period, and a 128 KB minimum object size.
General Availability of S3 Select
Randall wrote a detailed introduction to S3 Select last year and showed you how you can use it to retrieve selected data from within S3 objects. During the preview we added support for server-side encryption and the ability to run queries from the S3 Console.
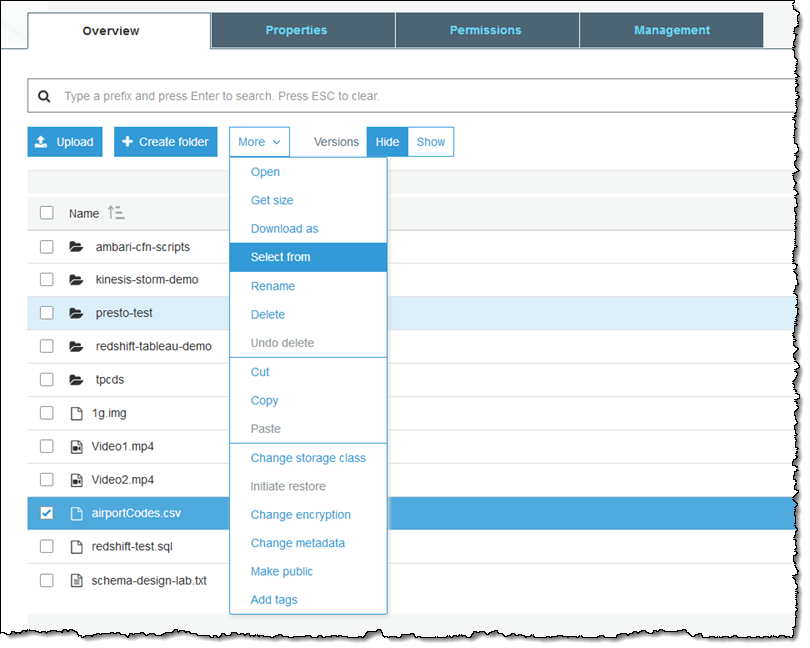
I used a CSV file of airport codes to exercise the new console functionality:
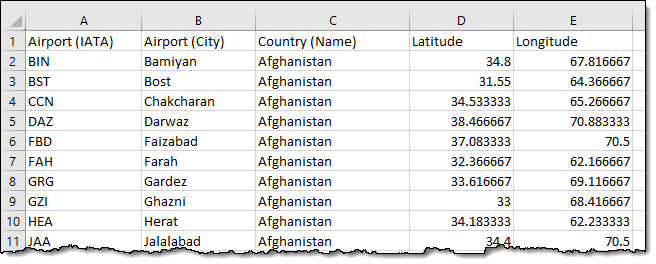
This file contains listings for over 9100 airports, so it makes for useful test data but it definitely does not test the limits of S3 Select in any way. I select the file, open the More menu, and choose Select from:
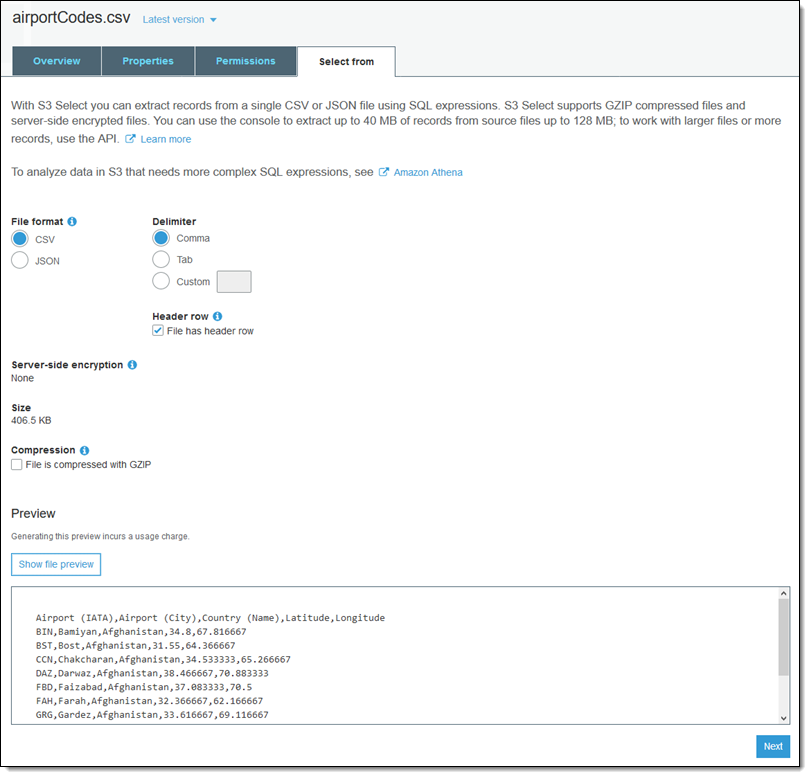
The console sets the file format and compression according to the file name and the encryption status. I set delimiter and click Show file preview to verify that my settings are correct. Then I click Next to proceed:
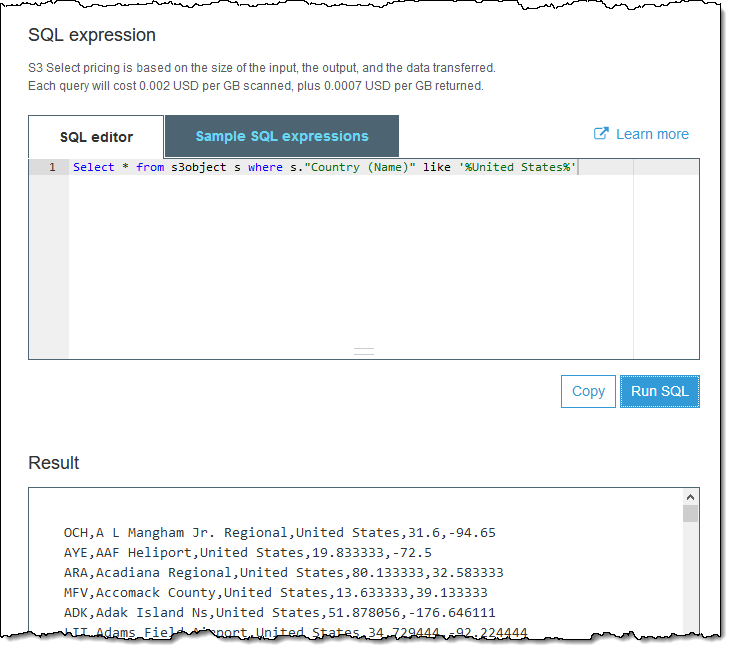
I type SQL expressions in the SQL editor and click Run SQL to issue the query:
Or:
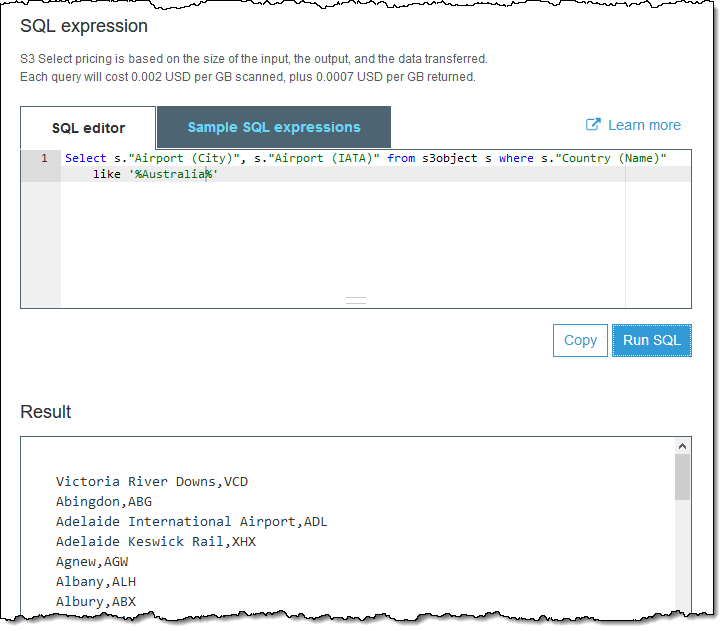
I can also issue queries from the AWS SDKs. I initiate the select operation:
And then I process the stream of results:
S3 Select is available in all public regions and you can start using it today. Pricing is based on the amount of data scanned and the amount of data returned.
— Jeff;