Amazon Web Services 한국 블로그
NVIDIA Tesla V100 GPU 지원 Amazon EC2 P3 인스턴스 타입 정식 출시
AWS는 고객 요청에따라 기술 변화에 맞는 EC2 인스턴스 타입을 지속적으로 추가해 왔습니다. 2006년 m1.small을 시작으로, 컴퓨팅 최적화, 메모리 최적화 혹은 스토리지 및 I/O 등에 최적화된 인스턴스 타입 등 많은 고객 선택 옵션을 제공하고 있습니다.
새로운 P3 인스턴스 타입 출시
오늘 AWS의 4개의 리전에 차세대 GPU 기반 EC2 인스턴스를 출시합니다. 최대 8개의 NVIDIA Tesla V100 GPU로 구동되는 P3 인스턴스는 고성능 컴퓨팅 작업을 요하는 기계 학습, 딥러닝, 전산 유체 역학, 전산 금융, 지진 분석, 분자 모델링 및 유전체 분석 작업 등의 부하를 처리할 수 있게 설계되었습니다.
P3 인스턴스는 최대 2.7GHz로 실행되는 맞춤형 Intel Xeon E5-2686v4 프로세서를 사용합니다. 세 가지 크기 (모든 VPC 전용 및 EBS 전용)로 사용할 수 있습니다.
| 모델 | NVIDIA Tesla V100 GPUs | GPU 메모리 |
NVIDIA NVLink | vCPUs | 주메모리 | 네트워크대역폭 | EBS 대역폭 |
| p3.2xlarge | 1 | 16 GiB | n/a | 8 | 61 GiB | Up to 10 Gbps | 1.5 Gbps |
| p3.8xlarge | 4 | 64 GiB | 200 GBps | 32 | 244 GiB | 10 Gbps | 7 Gbps |
| p3.16xlarge | 8 | 128 GiB | 300 GBps | 64 | 488 GiB | 25 Gbps | 14 Gbps |
각 NVIDIA GPU는 5,120개의 CUDA 코어와 640개의 Tensor 코어로 구성되어 있으며 최대 125 TFLOPS의 혼합 부동 소수 정밀도, 15.7 TFLOPS의 단일 부동 소수점 정밀도 및 7.8 TFLOPS의 복수 부동 소수점 정밀도를 지원합니다. 8xlarge 및 16xlarge 사이즈에는 각 GPU가 최대 300GBps의 데이터 속도로 실행되는 NVIDIA NVLink 2.0을 통해 서로 연결됩니다. 이를 통해 GPU는 중간 결과 및 기타 데이터를 CPU 또는 PCI-Express 패브릭을 통해 이동하지 않고 고속으로 교환할 수 있습니다.
텐서코어(Tensor Core) 소개
NVIDIA 블로그에 따르면, Tensor 코어는 딥러닝 신경망 학습 및 추론을 가속화하도록 설계되었습니다. 각 코어는 한 쌍의 4×4 반 정밀도 (FP16이라고도 함) 행렬을 빠르고 효율적으로 연산해서 얻은 4×4 행렬을 다른 반 또는 단일 정밀도 (FP32) 행렬에 더한 다음, 절반 또는 단일 정밀도 형식의 4×4 행렬 NVIDIA 블로그 게시물의 다이어그램은 다음과 같습니다.
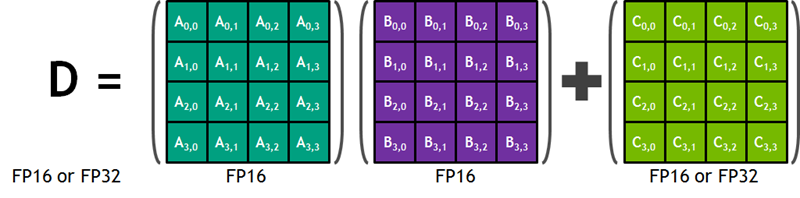
이 작업은 딥러닝 네트워크를 위한 학습 과정에서 가장 먼저 실행하는 것으로, 오늘날의 NVIDIA GPU 하드웨어가 매우 구체적인 시장 요구를 해결하기 위해 특별한 방법으로 구축되었는지 보여주는 훌륭한 예입니다. 텐서 코어 성능의 혼합 정밀도 한정자(mixed-precision qualifier)는 16비트 및 32비트 부동 소수점 값의 조합으로 작업하기에 충분히 유연하다는 것을 의미합니다.
정식 출시
NVIDIA Tesla V100 GPU 및 Tensor 코어를 최대한 활용하려면 CUDA 9 및 cuDNN7을 사용해야합니다. 이 드라이버와 라이브러리는 이미 최신 버전의 Windows AMI에 추가되었으며, 11 월 7 일에 출시예정인 업데이트 된 Amazon Linux AMI에 포함될 예정입니다. 새로운 패키지는 기존 Amazon Linux AMI에 설치하려는 경우 이미 레포지터리에서 사용할 수 있습니다.
최신 AWS Deep Learning AMI에는 Apache MXNet, Caffe2 및 Tensorflow (각각 NVIDIA Tesla V100 GPU 지원)의 최신 버전이 사전 설치되어 있으며 Microsoft Cognitive Toolkit과 같은 다른 기계 학습 프레임 워크로 P3 인스턴스를 지원하도록 업데이트됩니다. 이 프레임 워크가 NVIDIA Tesla V100 GPU에 대한 지원을 출시하면, PyTorch를 사용할 수 있습니다. 또한 NGC 용 NVIDIA Volta Deep Learning AMI를 사용할 수도 있습니다.
P3 인스턴스는 On-Demand, Spot, Reserved Instance 및 Dedicated Host 양식의 미국 동부 (버지니아 북부), 미국 서부 (오레곤), EU (아일랜드) 및 아시아 태평양 지역 (도쿄) 지역에서 사용할 수 있습니다. 더 자세한 사항은 P3 인스턴스 소개 페이지를 참고하세요!
— Jeff;
이 글은 New – Amazon EC2 Instances with Up to 8 NVIDIA Tesla V100 GPUs (P3)의 한국어 편집본입니다. Amazon 인공 지능에 대한 좀 더 자세한 사항은 아래 한국어 발표 자료 및 동영상을 참고하시기 바랍니다.

자세히 알아보기