AWS Machine Learning Blog
Customize Amazon SageMaker Studio using Lifecycle Configurations
July 2023: This post was reviewed for accuracy.
Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning (ML) that lets you build, train, debug, deploy, and monitor your ML models. It provides all the tools you need to take your models from experimentation to production while boosting your productivity. You can write code, track experiments, visualize data, and perform debugging and monitoring within a single, integrated visual interface.
We’re excited to announce Lifecycle Configuration for Studio, a new capability that enables developers to automate customization for your Studio development environments.
Lifecycle configurations are shell scripts triggered by Studio lifecycle events, such as starting a new Studio notebook. You can use these shell scripts to automate customization for your Studio environments, such as installing JupyterLab extensions, preloading datasets, and setting up source code repositories.
Previously, customizations to Studio environments were possible, but you needed to reapply them manually every time apps were deleted or recreated. Lifecycle configuration provides a way to automatically and repeatably apply your customizations.
In this post, we show you how to use lifecycle configurations for three common customization use cases:
- Installing custom packages
- Configuring auto-shutdown of inactive notebook apps
- Setting up Git configuration
For more examples, visit the SageMaker Studio Lifecycle Configuration Samples repository on GitHub.
Install custom packages on base kernel images
One common use case for lifecycle configuration is to install custom libraries so they’re available right away whenever you start a new kernel app. Lifecycle configuration allows you to automate this process without the need to build a custom Studio image.
Say that you need to install pyarrow in your notebook environment so that you can work with a Parquet-formatted training dataset for your ML model. Let’s see how to use lifecycle configuration to automate the installation of this dependency in the kernel.
The following is the typical workflow for using lifecycle configuration in your apps:
- Write the script.
- Convert the script to a base64 encoded string.
- Create a lifecycle configuration entity via the AWS Command Line Interface (AWS CLI).
- Associate the lifecycle configuration to a domain or user profile.
- Start the Studio app with the specified lifecycle configuration.
Write the script
The following sample script installs pyarrow using the pip package manager. You can modify this script to install the dependencies you need for your own notebooks:
One helpful practice when creating and debugging your own scripts is to use set -eux, which helps you to see in the logs where a failure occurred. It writes the commands line by line while it’s running, and stops the script right away when there is a failure.
Let’s save the preceding script as a file called install-package.sh.
Convert the script to a base64 encoded string
When creating the lifecycle config, we pass the script contents as a base64 encoded string. This requirement prevents errors due to the encoding of spacing and line breaks. Here’s how you can base64 encode the contents of the file we just created. In a terminal, use the following command:
The base64-encoded script content is now saved in the LCC_CONTENT variable.
Create a lifecycle configuration entity via the AWS CLI
Now we can create the lifecycle configuration entity using the AWS CLI, specifying the base64-encoded content saved in the LCC_CONTENT variable as the lifecycle configuration content.
At this point, you need to determine whether the lifecycle configuration should belong to the JupyterServer or KernelGateway app type:
- JupyterServer – Enables access to the visual interface for Studio
- KernelGateway – Enables access to the code run environment and kernels for your Studio notebooks and terminals
In this case, because we want to customize the kernel environment that the notebook code runs in by installing additional custom packages, we should specify KernelGateway for the lifecycle configuration app type. In the following code, we name the created entity install-pip-package-on-kernel, but you are free to use your own:
After you create the lifecycle configuration, note the lifecycle configuration ARN returned in the response:
Keep in mind that the lifecycle configuration entity is immutable. If you need to update a lifecycle configuration entity, you should instead create a new lifecycle configuration entity, update apps to use the new lifecycle configuration entity, and delete the old lifecycle configuration entity.
Associate the lifecycle configuration to a domain or user profile
Before you can use the lifecycle configuration, you need to associate it with a Studio domain or user profile. The set of lifecycle configurations specified in the domain or user profile settings determines which lifecycle configurations are available for the domain or user profile to use. You can add lifecycle configurations to either existing or new domains and user profiles. Note that lifecycle configurations attached to a domain are inherited by all users of a domain, but those attached to a user are scoped specifically to that user.
You can use the AWS CLI to create a user profile that can use our new lifecycle configuration. Because this lifecycle configuration is associated with the KernelGateway app type, we add it to the list of lifecycle config ARNs under KernelGatewayAppSettings. Make sure to replace the domain ID in the following script. You can find your domain ID in the Studio Control Panel under Studio Summary.
Alternatively, you can update an existing user profile to add the lifecycle configuration:
Start the app
After you add the lifecycle configuration to the domain or user, in the Studio user interface, go to the Launcher where you create new notebooks. Next to the image selection option (Select a SageMaker image), you can see the Select a start-up script option.

Choose the script from the available ones for your user or domain on the drop-down menu.
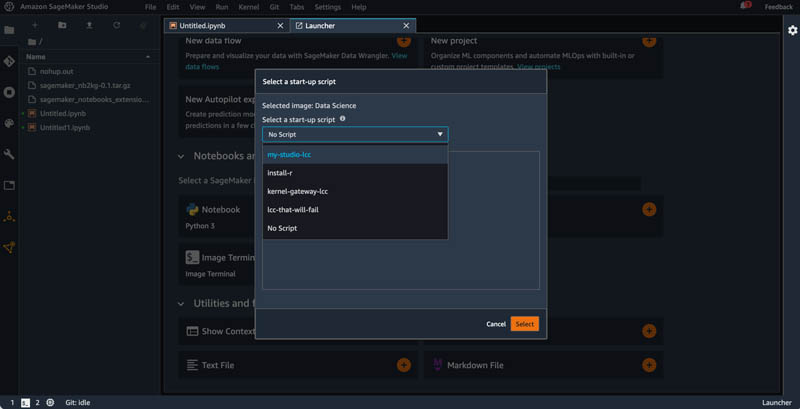
You can verify the contents of the script after you choose it.
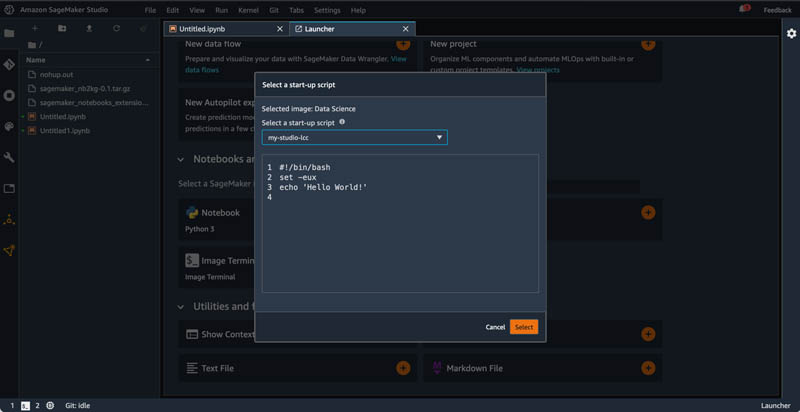
The new notebook now uses the specified script.
Configure auto-shutdown of inactive kernels
Let’s say you’re an administrator for a Studio domain, and want to save costs by having notebook apps shut down automatically after long periods of inactivity. You can create a lifecycle configuration on that installs the Studio auto-shutdown JupyterLab extension by default on users’ JupyterServer apps, so users don’t have to install it manually, and it stays enabled even if the JupyterServer app gets restarted.
See the auto shutdown server extension script from the Studio lifecycle configuration example scripts repository to install the extension.
In addition, the LCC script also creates a bash script that allows users to set an idle timeout called set-time-interval.sh. By default, it is set to 120 minutes of inactivity. If you wish to update the idle timeout, update the TIMEOUT_IN_MINS value in the script before executing.
Because we’re customizing the JupyterServer app by installing a JupyterLab extension, this lifecycle configuration should be associated with the JupyterServer app type when creating the SageMaker entity:
We want to make this the default lifecycle configuration for all users in the domain. We can accomplish this by adding the lifecycle configuration to the default settings of the domain using the DefaultResourceSpec settings. This way, the script runs by default whenever users in the domain log in to Studio for the first time or restart Studio:
For per-user overrides, you can specify a default lifecycle configuration in the user profile, which overrides any specified for the domain.
Set up Git configuration
Developers often store their code or notebooks in version-controlled Git repositories to collaborate with others. Typically, this requires developers to configure user information or credentials in their development environment.
For example, before making any Git commits from your Studio environment, you want to configure the email and user name that is associated with commits. Typically, the commands look like the following code:
To have these settings persisted every time the Jupyter Server restarts, you can use the following script (set-git-config) from the example scripts repository (make sure you modify it to add your own user name and email) as a JupyterServer lifecycle configuration script for your user profile.
Another frequent use case is set up Git credentials for authentication to remote repositories. Although you can use the AWS Identity and Access Management (IAM) execution role used by Studio to automatically authenticate to AWS CodeCommit repositories, developers may also need to manually set up a password or developer token to connect to other repository sources such as GitHub.
The following script (set-git-credentials) from the example scripts repository shows you how to set up a workflow that retrieves a password or developer token from AWS Secrets Manager directly when authenticating to your remote repository. Storing passwords and tokens in Secrets Manager eliminates the need to store any sensitive information on the Amazon Elastic File System (Amazon EFS) storage instance backing your Studio domain. Make sure that you modify the script with your own user name, secret name and key, and Region.
Similar to the previous example, to set up the lifecycle configuration, you complete the following steps:
- Base64 encode the script.
- Create a lifecycle configuration entity. For git configuration scripts, use
JupyterServeras the app type. - Attach it to the Studio entity that you want to make the lifecycle configuration available for use with. Because these scripts set up user-specific credentials, attach these at the user profile level.
When you specify a default lifecycle configuration in the user profile, it overrides any default JupyterServer lifecycle configuration specified at the domain level. See the following code:
Conclusion
In this post, we highlighted three use cases that represent common automation tasks for developers and data scientists, but you can find more examples of what you can do with lifecycle configurations in the public repository of notebook lifecycle configuration scripts.
You can start using lifecycle configuration for Studio today, in all Regions where Studio is available.
For more information, see the following resources:
- Amazon SageMaker Studio lifecycle configuration documentation
- Amazon SageMaker Studio
- Repository of example lifecycle configuration scripts
About the Authors
 Andrew Ang is a Deep Learning Architect at the Amazon ML Solutions Lab, where he helps AWS customers identify and build AI/ML solutions to address their business problems.
Andrew Ang is a Deep Learning Architect at the Amazon ML Solutions Lab, where he helps AWS customers identify and build AI/ML solutions to address their business problems.
 Sumit Thakur is a Senior Product Manager for Amazon Machine Learning where he loves working on products that make it easy for customers to get started with machine learning on cloud. In his spare time, he likes connecting with nature and watching sci-fi TV series.
Sumit Thakur is a Senior Product Manager for Amazon Machine Learning where he loves working on products that make it easy for customers to get started with machine learning on cloud. In his spare time, he likes connecting with nature and watching sci-fi TV series.
 Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
Ram Vegiraju is a ML Architect with the SageMaker Service team. He focuses on helping customers build and optimize their AI/ML solutions on Amazon SageMaker. In his spare time, he loves traveling and writing.
 Rama Thamman is a Software Development Manager with the AI Platforms team, leading the ML Migrations team.
Rama Thamman is a Software Development Manager with the AI Platforms team, leading the ML Migrations team.
 Raghu Ramesha is an ML Solution Architect in AWS SageMaker SA Team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is an ML Solution Architect in AWS SageMaker SA Team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
 Durga Sury is an ML Solution Architect at AWS SageMaker SA Team. Before AWS, she enabled non-profit and government agencies derive insights from their data to improve education outcomes. At AWS, she focuses on Natural Language Processing and MLOps.
Durga Sury is an ML Solution Architect at AWS SageMaker SA Team. Before AWS, she enabled non-profit and government agencies derive insights from their data to improve education outcomes. At AWS, she focuses on Natural Language Processing and MLOps.