Learn about Lake Formation
Managing and scaling data access is complex and time consuming. Learn how AWS Lake Formation can help you centrally manage and scale fine-grained data access permissions and share data with confidence within and outside your organization.
Benefits of Lake Formation
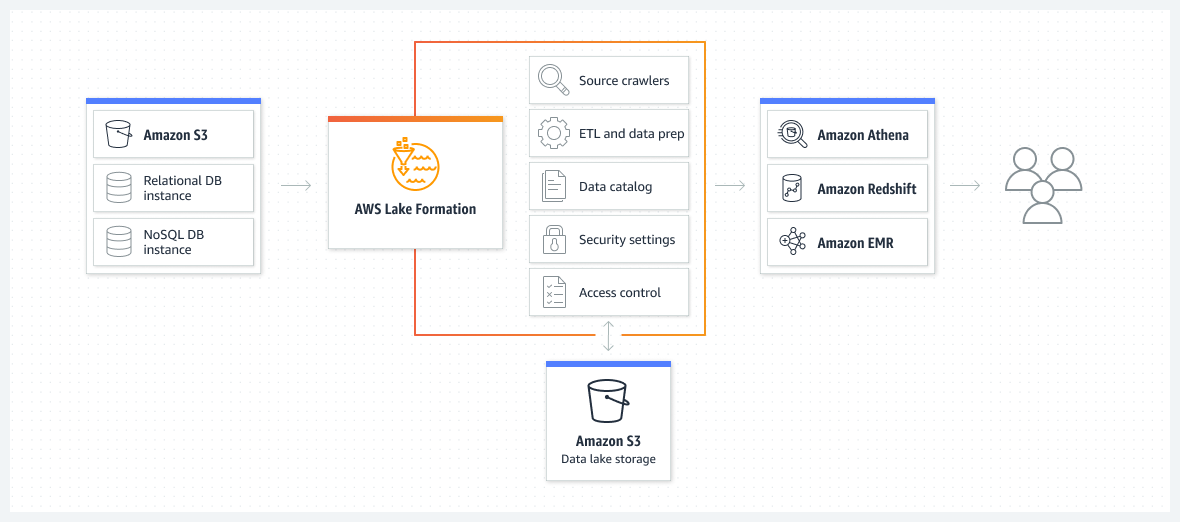
How it works
AWS Lake Formation centralizes permissions management of your data and makes it easier to share across your organization and externally.
Use cases
Manage permissions using familiar database-like features
Centralize permissions management for data resources, including databases and tables, from one place in the AWS Glue Data Catalog.
Govern and help secure your data at scale
Scale permissions across your users by setting attributes on data and applying attribute permissions.
Simplify data sharing inside and outside your organization
Encourage innovation by allowing users to quickly find, appropriately access, and share data with confidence in accordance with your goals and policies.
Monitor access and improve compliance with auditing
Proactively address data challenges and protect your business with comprehensive data-access auditing.