AWS Compute Blog
Synchronizing Amazon S3 Buckets Using AWS Step Functions

Constantin Gonzalez is a Principal Solutions Architect at AWS
In my free time, I run a small blog that uses Amazon S3 to host static content and Amazon CloudFront to distribute it world-wide. I use a home-grown, static website generator to create and upload my blog content onto S3.
My blog uses two S3 buckets: one for staging and testing, and one for production. As a website owner, I want to update the production bucket with all changes from the staging bucket in a reliable and efficient way, without having to create and populate a new bucket from scratch. Therefore, to synchronize files between these two buckets, I use AWS Lambda and AWS Step Functions.
In this post, I show how you can use Step Functions to build a scalable synchronization engine for S3 buckets and learn some common patterns for designing Step Functions state machines while you do so.
Step Functions overview
Step Functions makes it easy to coordinate the components of distributed applications and microservices using visual workflows. Building applications from individual components that each perform a discrete function lets you scale and change applications quickly.
While this particular example focuses on synchronizing objects between two S3 buckets, it can be generalized to any other use case that involves coordinated processing of any number of objects in S3 buckets, or other, similar data processing patterns.
Bucket replication options
Before I dive into the details on how this particular example works, take a look at some alternatives for copying or replicating data between two Amazon S3 buckets:
- The AWS CLI provides customers with a powerful aws s3 sync command that can synchronize the contents of one bucket with another.
- S3DistCP is a powerful tool for users of Amazon EMR that can efficiently load, save, or copy large amounts of data between S3 buckets and HDFS.
- The S3 cross-region replication functionality enables automatic, asynchronous copying of objects across buckets in different AWS regions.
In this use case, you are looking for a slightly different bucket synchronization solution that:
- Works within the same region
- Is more scalable than a CLI approach running on a single machine
- Doesn’t require managing any servers
- Uses a more finely grained cost model than the hourly based Amazon EMR approach
You need a scalable, serverless, and customizable bucket synchronization utility.
Solution architecture
Your solution needs to do three things:
- Copy all objects from a source bucket into a destination bucket, but leave out objects that are already present, for efficiency.
- Delete all “orphaned” objects from the destination bucket that aren’t present on the source bucket, because you don’t want obsolete objects lying around.
- Keep track of all objects for #1 and #2, regardless of how many objects there are.
In the beginning, you read in the source and destination buckets as parameters and perform basic parameter validation. Then, you operate two separate, independent loops, one for copying missing objects and one for deleting obsolete objects. Each loop is a sequence of Step Functions states that read in chunks of S3 object lists and use the continuation token to decide in a choice state whether to continue the loop or not.
This solution is based on the following architecture that uses Step Functions, Lambda, and two S3 buckets:
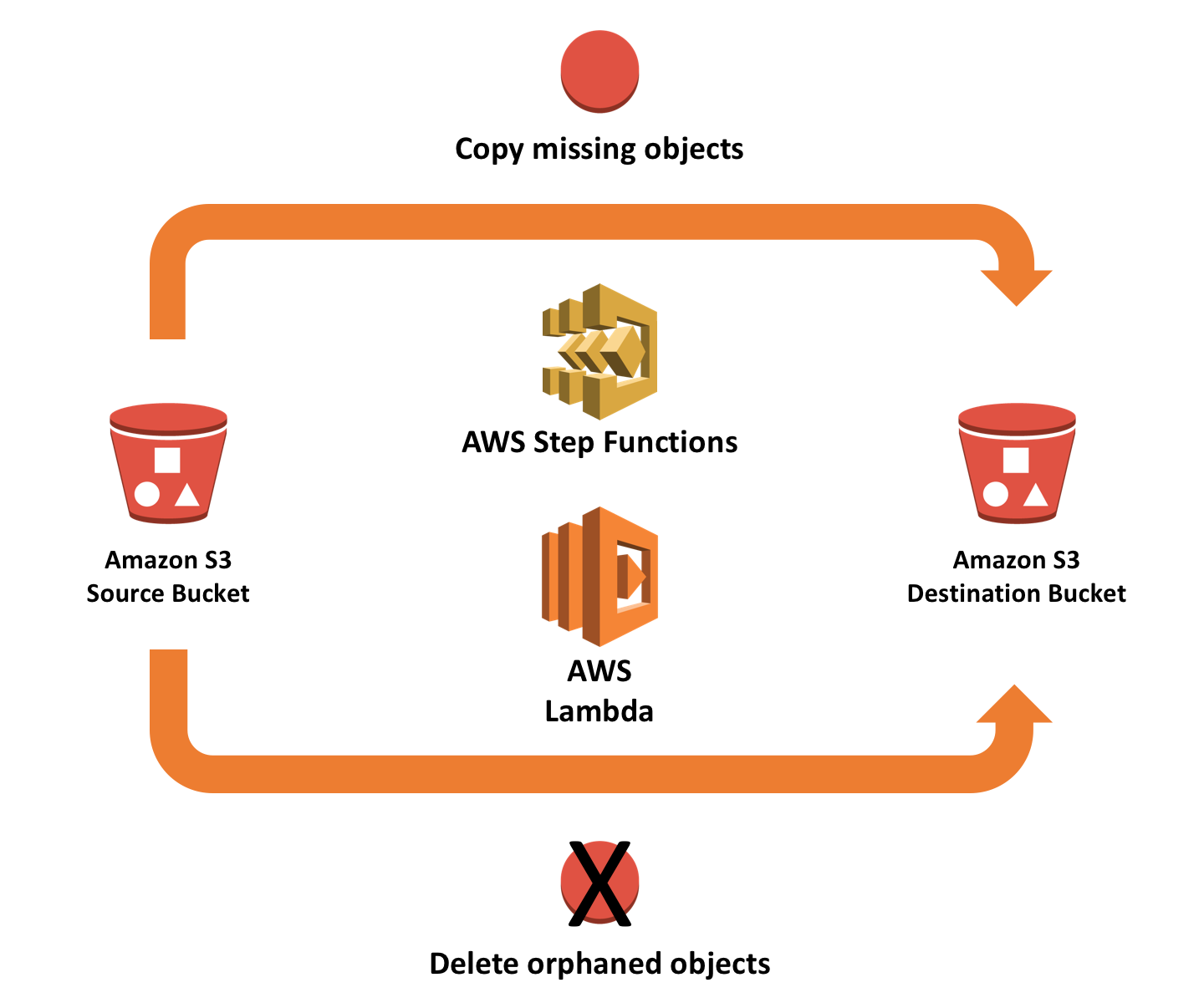
As you can see, this setup involves no servers, just two main building blocks:
- Step Functions manages the overall flow of synchronizing the objects from the source bucket with the destination bucket.
- A set of Lambda functions carry out the individual steps necessary to perform the work, such as validating input, getting lists of objects from source and destination buckets, copying or deleting objects in batches, and so on.
To understand the synchronization flow in more detail, look at the Step Functions state machine diagram for this example.

Walkthrough
Here’s a detailed discussion of how this works.
To follow along, use the code in the sync-buckets-state-machine GitHub repo. The code comes with a ready-to-run deployment script in Python that takes care of all the IAM roles, policies, Lambda functions, and of course the Step Functions state machine deployment using AWS CloudFormation, as well as instructions on how to use it.
Fine print: Use at your own risk
Before I start, here are some disclaimers:
- Educational purposes only.
The following example and code are intended for educational purposes only. Make sure that you customize, test, and review it on your own before using any of this in production.
- S3 object deletion.
In particular, using the code included below may delete objects on S3 in order to perform synchronization. Make sure that you have backups of your data. In particular, consider using the Amazon S3 Versioning feature to protect yourself against unintended data modification or deletion.
Step Functions execution starts with an initial set of parameters that contain the source and destination bucket names in JSON:
{
"source": "my-source-bucket-name",
"destination": "my-destination-bucket-name"
}Armed with this data, Step Functions execution proceeds as follows.
Step 1: Detect the bucket region
First, you need to know the regions where your buckets reside. In this case, take advantage of the Step Functions Parallel state. This allows you to use a Lambda function get_bucket_location.py inside two different, parallel branches of task states:
FindRegionForSourceBucketFindRegionForDestinationBucket
Each task state receives one bucket name as an input parameter, then detects the region corresponding to “their” bucket. The output of these functions is collected in a result array containing one element per parallel function.
Step 2: Combine the parallel states
The output of a parallel state is a list with all the individual branches’ outputs. To combine them into a single structure, use a Lambda function called combine_dicts.py in its own CombineRegionOutputs task state. The function combines the two outputs from step 1 into a single JSON dict that provides you with the necessary region information for each bucket.
Step 3: Validate the input
In this walkthrough, you only support buckets that reside in the same region, so you need to decide if the input is valid or if the user has given you two buckets in different regions. To find out, use a Lambda function called validate_input.py in the ValidateInput task state that tests if the two regions from the previous step are equal. The output is a Boolean.
Step 4: Branch the workflow
Use another type of Step Functions state, a Choice state, which branches into a Failure state if the comparison in step 3 yields false, or proceeds with the remaining steps if the comparison was successful.
Step 5: Execute in parallel
The actual work is happening in another Parallel state. Both branches of this state are very similar to each other and they re-use some of the Lambda function code.
Each parallel branch implements a looping pattern across the following steps:
- Use a Pass state to inject either the string value
"source"(InjectSourceBucket) or"destination"(InjectDestinationBucket) into thelistBucketattribute of the state document.The next step uses either the source or the destination bucket, depending on the branch, while executing the same, generic Lambda function. You don’t need two Lambda functions that differ only slightly. This step illustrates how to use Pass states as a way of injecting constant parameters into your state machine and as a way of controlling step behavior while re-using common step execution code. - The next step
UpdateSourceKeyList/UpdateDestinationKeyListlists objects in the given bucket.Remember that the previous step injected either
"source"or"destination"into the state document’slistBucketattribute. This step uses the samelist_bucket.pyLambda function to list objects in an S3 bucket. ThelistBucketattribute of its input decides which bucket to list. In the left branch of the main parallel state, use the list of source objects to work through copying missing objects. The right branch uses the list of destination objects, to check if they have a corresponding object in the source bucket and eliminate any orphaned objects. Orphans don’t have a source object of the same S3 key. - This step performs the actual work. In the left branch, the
CopySourceKeysstep uses thecopy_keys.pyLambda function to go through the list of source objects provided by the previous step, then copies any missing object into the destination bucket. Its sister step in the other branch,DeleteOrphanedKeys, uses its destination bucket key list to test whether each object from the destination bucket has a corresponding source object, then deletes any orphaned objects. - The S3
ListObjectsAPI action is designed to be scalable across many objects in a bucket. Therefore, it returns object lists in chunks of configurable size, along with a continuation token. If the API result has a continuation token, it means that there are more objects in this list. You can work from token to token to continue getting object list chunks, until you get no more continuation tokens.
By breaking down large amounts of work into chunks, you can make sure each chunk is completed within the timeframe allocated for the Lambda function, and within the maximum input/output data size for a Step Functions state.
This approach comes with a slight tradeoff: the more objects you process at one time in a given chunk, the faster you are done. There’s less overhead for managing individual chunks. On the other hand, if you process too many objects within the same chunk, you risk going over time and space limits of the processing Lambda function or the Step Functions state so the work cannot be completed.
In this particular case, use a Lambda function that maximizes the number of objects listed from the S3 bucket that can be stored in the input/output state data. This is currently up to 32,768 bytes, assuming (based on some experimentation) that the execution of the COPY/DELETE requests in the processing states can always complete in time.
A more sophisticated approach would use the Step Functions retry/catch state attributes to account for any time limits encountered and adjust the list size accordingly through some list site adjusting.
Step 6: Test for completion
Because the presence of a continuation token in the S3 ListObjects output signals that you are not done processing all objects yet, use a Choice state to test for its presence. If a continuation token exists, it branches into the UpdateSourceKeyList step, which uses the token to get to the next chunk of objects. If there is no token, you’re done. The state machine then branches into the FinishCopyBranch/FinishDeleteBranch state.
By using Choice states like this, you can create loops exactly like the old times, when you didn’t have for statements and used branches in assembly code instead!
Step 7: Success!
Finally, you’re done, and can step into your final Success state.
Lessons learned
When implementing this use case with Step Functions and Lambda, I learned the following things:
- Sometimes, it is necessary to manipulate the JSON state of a Step Functions state machine with just a few lines of code that hardly seem to warrant their own Lambda function. This is ok, and the cost is actually pretty low given Lambda’s 100 millisecond billing granularity. The upside is that functions like these can be helpful to make the data more palatable for the following steps or for facilitating Choice states. An example here would be the
combine_dicts.pyfunction. - Pass states can be useful beyond debugging and tracing, they can be used to inject arbitrary values into your state JSON and guide generic Lambda functions into doing specific things.
- Choice states are your friend because you can build while-loops with them. This allows you to reliably grind through large amounts of data with the patience of an engine that currently supports execution times of up to 1 year.
Currently, there is an execution history limit of 25,000 events. Each Lambda task state execution takes up 5 events, while each choice state takes 2 events for a total of 7 events per loop. This means you can loop about 3500 times with this state machine. For even more scalability, you can split up work across multiple Step Functions executions through object key sharding or similar approaches.
- It’s not necessary to spend a lot of time coding exception handling within your Lambda functions. You can delegate all exception handling to Step Functions and instead simplify your functions as much as possible.
- Step Functions are great replacements for shell scripts. This could have been a shell script, but then I would have had to worry about where to execute it reliably, how to scale it if it went beyond a few thousand objects, etc. Think of Step Functions and Lambda as tools for scripting at a cloud level, beyond the boundaries of servers or containers. “Serverless” here also means “boundary-less”.
Summary
This approach gives you scalability by breaking down any number of S3 objects into chunks, then using Step Functions to control logic to work through these objects in a scalable, serverless, and fully managed way.
To take a look at the code or tweak it for your own needs, use the code in the sync-buckets-state-machine GitHub repo.
To see more examples, please visit the Step Functions Getting Started page.
Enjoy!