Gostaria de ser notificado sobre novos conteúdos?
No momento em que adicionamos nosso segundo servidor, os sistemas distribuídos tornaram-se um estilo de vida na Amazon. Quando comecei a trabalhar na Amazon, em 1999, tínhamos um número tão baixo de servidores, que podíamos dar nomes a eles, como “fishy” ou “online-01”. No entanto, mesmo em 1999, a computação distribuída não era fácil. Agora, os desafios com sistemas distribuídos envolvem latência, escalabilidade, compreensão sobre APIs de redes, marshalling e unmarshalling de dados e a complexidade dos algoritmos, como Paxos. Conforme os sistemas aumentam e tornam-se mais distribuídos, os casos de borda que eram teóricos tornaram-se ocorrências regulares.
O desenvolvimento de serviços distribuídos de computação de utilitários, como redes confiáveis de telefone de longa distância, ou serviços da Amazon Web Services (AWS), é complexo. A computação distribuída também é mais estranha e menos intuitiva do que outras formas de computação, devido a dois problemas inter-relacionados. Falhas independentes e não determinismo causam os problemas mais impactantes nos sistemas distribuídos. Além das falhas de computação típicas com as quais a maioria dos engenheiros está acostumado, as falhas em sistemas distribuídos podem ocorrer de várias outras maneiras. E o que é pior: é impossível saber sempre se algo apresentou falha.
Na Biblioteca do criador da Amazon, abordamos como a AWS lida com os problemas complexos de desenvolvimento e operações que surgem com os sistemas distribuídos. Antes de nos aprofundarmos nessas técnicas em outros artigos, é importante analisar os conceitos que contribuem para as razões de a computação distribuída ser, bem, estranha. Primeiro, vamos analisar os tipos de sistemas distribuídos.
Os tipos de sistemas distribuídos
Sistemas de tempo real crítico são estranhos
Em um roteiro das revistinhas do Super-homem, ele encontra um alter ego chamado Bizarro que vive em um planeta (Mundo Bizarro) onde tudo é ao contrário. O Bizarro se parece com o Super-homem, mas na verdade, é do mal. Os sistemas distribuídos de tempo real crítico são assim também. Eles se parecem com a computação comum, mas são diferentes e, francamente, um pouco do mal.
O desenvolvimento de sistemas distribuídos de tempo real crítico é bizarro por um motivo: redes de solicitação/resposta. Nós não estamos falando dos pormenores de TCP/IP, DNS, soquetes ou outros protocolos. Esses assuntos são potencialmente difíceis de entender, mas lembram outros problemas difíceis em computação.
O dificulta os sistemas distribuídos de tempo real crítico é que a rede permite o envio de mensagens de um domínio de falhas a outro. Enviar uma mensagem pode parecer algo inócuo. Na verdade, o envio de mensagens é onde tudo começa a ficar mais complicado que o normal.
Para dar um exemplo simples, veja o trecho de código a seguir de uma implementação do Pac-Man. Com o objetivo de ser executado em uma única máquina, ele não envia mensagens por nenhuma rede.
board.move(pacman, user.joystickDirection())
ghosts = board.findAll(":ghost")
for (ghost in ghosts)
if board.overlaps(pacman, ghost)
user.slayBy(":ghost")
board.remove(pacman)
returnAgora, vamos imaginar o desenvolvimento de uma versão em rede deste código, onde o estado do painel do objeto é mantido em um servidor separado. Todas as chamadas para o objeto do painel, como findAll(), resultam no envio e no recebimento de mensagens entre dois servidores.
Sempre que uma mensagem de solicitação/resposta for enviada entre dois servidores, o mesmo conjunto de oito etapas, no mínimo, devem acontecer sempre. Para compreender o código em rede do Pac-Man, vamos analisar os conceitos básicos de sistema de mensagens de solicitação/reposta.
Sistema de mensagens de solicitação/resposta em uma rede
A ação de ida e volta de solicitação/resposta sempre envolve as mesmas etapas. Como mostra o diagrama a seguir, a máquina do cliente, CLIENTE, envia uma solicitação de MENSAGEM pela rede, REDE, para a máquina do servidor, SERVIDOR, que responde com a mensagem RESPOSTA, também pela rede REDE.
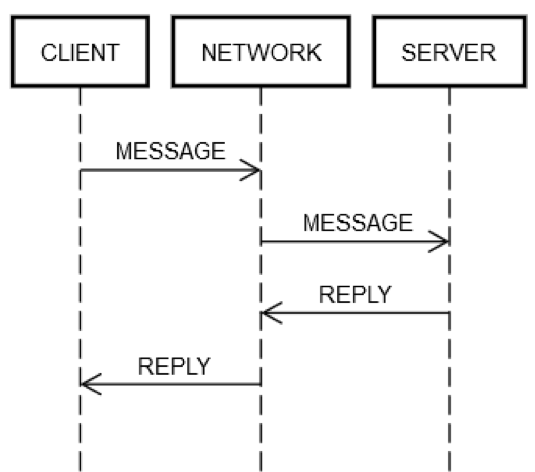
Nos casos vitoriosos em que tudo funciona, acontecem as seguintes etapas:
1. PUBLICAR SOLICITAÇÃO: o CLIENTE coloca a solicitação MENSAGEM na REDE.
2. ENTREGAR SOLICITAÇÃO: o CLIENTE entrega a solicitação MENSAGEM ao SERVIDOR.
3. VALIDAR SOLICITAÇÃO: o SERVIDOR valida a MENSAGEM.
4. ATUALIZAR O ESTADO DO SERVIDOR: o SERVIDOR atualiza seu estado, se necessário, de acordo com a MENSAGEM.
5. PUBLICAR RESPOSTA: o SERVIDOR coloca a resposta (RESPOSTA) na REDE.
6. ENTREGAR A RESPOSTA: a REDE entrega a RESPOSTA ao CLIENTE.
7. VALIDAR A RESPOSTA: o CLIENTE valida a RESPOSTA.
8. ATUALIZAR O ESTADO DO CLIENTE: o CLIENTE atualiza seu estado, de acordo com a RESPOSTA.
São várias etapas para um único ciclo de ida e volta! Ainda assim, essas etapas são a definição da comunicação de solicitação/resposta em uma rede; não há como ignorar alguma delas. Por exemplo, é impossível ignorar a etapa 1. O cliente deve colocar a MENSAGEM na rede (REDE) de alguma forma. Fisicamente, isso quer dizer enviar pacotes via um adaptador de rede, que faz com que sinais elétricos viagem por uma série de routers que compõem a rede entre o CLIENTE e o SERVIDOR. Isso é separado da etapa 2 porque a etapa 2 pode falhar por motivos independentes, como o SERVIDOR de repente sofrer uma queda de energia e ficar impossibilitado de aceitar os pacotes de entrada. A mesma lógica pode ser aplicada às etapas restantes.
Portanto, uma única solicitação/resposta pela rede explode uma coisa (chamando um método) em oito coisas. O pior, como observado em cima, o CLIENTE, SERVIDOR e a REDE podem falhar de modo independente um do outro. O código dos engenheiros deve lidar com a falha de qualquer uma das etapas descritas anteriormente. Isso é raramente a realidade da engenharia típica. Para ver o motivo disso, vamos analisar a seguinte expressão da versão de máquina individual do código.
board.find("pacman")Tecnicamente, existem algumas maneiras estranhas de como este código pode falhar no tempo de execução, mesmo se a implementação de board.find não apresente falhas. Por exemplo, a CPU pode ter um superaquecimento espontâneo no tempo de execução. A alimentação de energia da máquina pode falhar, também de modo espontâneo. O kernel pode entrar em pânico. A memória pode estar esgotada, e algum objeto que board.find tentar criar pode não ser criado. Ou, o disco na máquina em execução pode estar cheio e board.find pode falhar na atualização de algum arquivo de estatística e depois devolver um erro, mesmo que, provavelmente, não devesse acontecer. Um raio gama pode atingir o servidor e inverter um bit na RAM. Mas, a maior parte do tempo, os engenheiros não se preocupam com essas coisas. Por exemplo, os testes de unidade nunca cobrem o cenário “e se a CPU falhar”, e raramente cobrem cenários de falta de memória.
Na engenharia típica, estes tipos de falhas ocorrem em uma única máquina; isto é, uma falha de domínio único. Por exemplo, se o método board.find falhar devido a uma falha espontânea de uma CPU, pode-se tranquilamente presumir que toda a máquina vai falhar. Não é possível lidar com esse erro nem conceitualmente. Pressuposições semelhantes podem ser feitas sobre outros tipos de erros listados anteriormente. Você pode tentar escrever testes para outros casos de uso, mas não tem muito sentido para a engenharia típica. Se essas falhas acontecerem, é praticamente certo que todo o resto vai falhar também. Tecnicamente, dizemos que todas as falhas compartilham o mesmo destino. Essa ideia, de mesmo destino, reduz imensamente os modos de falha diferentes com os quais um engenheiro tem que lidar.
Como lidar com modos de falha em sistemas distribuídos de tempo real crítico
Os engenheiros trabalhando em sistemas distribuídos de tempo real crítico devem testar todos os aspectos da falha de rede, pois os servidores e as redes não compartilham o mesmo destino. Diferentemente de um caso de máquina única, se a rede falhar, a máquina do cliente continuará funcionando. Se a máquina remota falhar, a máquina do cliente seguirá funcionando e assim por diante.
Para testar completamente os casos de falha das etapas de solicitação/resposta descritos anteriormente, os engenheiros devem presumir que cada etapa pode apresentar falha. E eles devem garantir que o código (tanto no cliente quanto no servidor) sempre se comporte corretamente diante de tais falhas.
Vamos ver uma ação de ida e volta de solicitação/resposta onde as coisas não estão funcionando:
1. PUBLICAR SOLICITAÇÃO falha: ou a REDE falhou na entrega da mensagem (por exemplo, o router intermediário travou no momento errado), ou o SERVIDOR a rejeitou explicitamente.
2. ENTREGAR SOLICITAÇÃO falha: a REDE entrega com êxito a MENSAGEM para o SERVIDOR, mas o SERVIDOR trava logo após receber a MENSAGEM.
3. VALIDAR SOLICITAÇÃO falha: o SERVIDOR decide que a MENSAGEM é inválida. A causa pode ser praticamente qualquer coisa. Por exemplo, pacotes corrompidos, versões de software incompatíveis, ou erros no cliente ou no servidor.
4. ATUALIZAR ESTADO DO SERVIDOR falha: o SERVIDOR tenta atualizar seu estado, mas isso não funciona.
5. PUBLICAR RESPOSTA falha: independentemente se a tentativa de responder teve êxito ou falhou, o SERVIDOR poderia apresentar falha na publicação da resposta. Por exemplo, a placa de rede poderia travar no momento errado.
6. ENTREGAR RESPOSTA falha: a REDE pode falhar na entrega da RESPOSTA ao CLIENTE conforme indicado antes, mesmo se a REDE estiver funcionando na etapa anterior.
7. VALIDAR RESPOSTA falha: o CLIENTE decide que a RESPOSTA é inválida.
8. ATUALIZAR ESTADO DO CLIENTE falha: o CLIENTE poderia receber a RESPOSTA da mensagem, mas falhar em atualizar seu próprio estado, falhar em entender a mensagem (devido à incompatibilidade), ou falhar por algum outro motivo.
Estes modos de falha são o que torna a computação distribuída tão difícil. Eu os chamo de os oitos modos de falha do apocalipse. Considerando estes modos de falha, vamos analisar a expressão do código do Pac-Man novamente.
board.find("pacman")Esta expressão se amplia para as seguintes atividades no lado do cliente:
1. Publique uma mensagem, como {action: "find", name: "pacman", userId: "8765309"}, na rede, endereçada à máquina do Painel.
2. Se a rede estiver indisponível, ou se a conexão à máquina do Painel for explicitamente recusada, acione um erro. Este caso é especial porque o cliente sabe, por determinismo, que a solicitação não poderia ter sido recebida pela máquina do servidor.
3. Aguarde uma resposta.
4. Se uma resposta nunca for recebida, acione o tempo limite. Nesta etapa, atingir o tempo limite quer dizer que o resultado da solicitação é DESCONHECIDO. Ele pode ter acontecido ou não. O cliente deve lidar com o DESCONHECIDO corretamente.
5. Se uma resposta tiver sido recebida, determine se foi uma resposta com êxito, uma resposta de erro ou uma resposta incompreensível/corrompida.
6. Se não for um erro, faça o unmarshall da resposta e transforme-a em um objeto que o código possa entender.
7. Se for uma resposta de erro ou incompreensível, acione uma exceção.
8. O quer que resolva a exceção deve determinar se deve repetir a solicitação ou desistir e interromper o jogo.
A expressão também começa após as atividades no lado do servidor:
1. Recebimento da solicitação (isso pode nem chegar a acontecer).
2. Validar a solicitação.
3. Pesquisar o usuário para ver ainda está ativo. (O servidor pode ter desistido do usuário porque não recebeu nenhuma mensagem dele por muito tempo.)
4. Atualizar a tabela keep-alive do usuário, para que o servidor saiba que ele (provavelmente) ainda está lá.
5. Pesquisar a posição do usuário.
6. Publicar uma resposta contendo algo como {xPos: 23, yPos: 92, clock: 23481984134}.
7. Qualquer lógica do servidor adicional deve lidar corretamente com os efeitos futuros do cliente. Por exemplo, a falha no recebimento da mensagem, receber, mas não compreender, receber e travar, ou resolver com êxito.
Em resumo, uma expressão no código normal vira quinze etapas extra no código de sistemas distribuídos de tempo real crítico. A expansão ocorre devido a oito pontos diferentes nos quais cada comunicação de ida e volta entre o cliente e o servidor pode falhar. Qualquer expressão que represente um ciclo de ida e volta na rede, como board.find("pacman"), resulta no que vem a seguir.
(error, reply) = network.send(remote, actionData)
switch error
case POST_FAILED:
// handle case where you know server didn't get it
case RETRYABLE:
// handle case where server got it but reported transient failure
case FATAL:
// handle case where server got it and definitely doesn't like it
case UNKNOWN: // i.e., time out
// handle case where the *only* thing you know is that the server received
// the message; it may have been trying to report SUCCESS, FATAL, or RETRYABLE
case SUCCESS:
if validate(reply)
// do something with reply object
else
// handle case where reply is corrupt/incompatibleA complexidade é inevitável. Se o código não resolver todos os casos corretamente, o serviço eventualmente falhará de modos bizarros. Imagine tentar escrever testes para todos os modos de falha que um sistema de cliente/servidor como o exemplo do Pac-Man poderia encontrar!
Testes dos sistemas distribuídos de tempo real crítico
O teste da versão de uma única máquina do trecho de código do Pac-Mac é comparativamente simples. Crie alguns objetos de Painel diferentes, coloque-os em estados diferentes, crie alguns objetos de Usuário em estados diferentes, e assim por diante. Os engenheiros pensariam com mais afinco sobre as condições de borda, e talvez usariam um teste generativo, ou um fuzzer.
No código do Pac-Man, existem quatro locais onde o objeto de painel é usado. No Pac-Man distribuído, existem quatro pontos no código que têm cinco resultados diferentes possíveis, como ilustrado anteriormente (POST_FAILED, falha da publicação, RETRYABLE, repetição na tentativa, FATAL, erro fatal, UNKNOWN, desconhecido, ou SUCCESS, sucesso). Eles multiplicam o espaço do estado dos testes enormemente. Por exemplo, os engenheiros de sistemas distribuídos de tempo real crítico devem resolver muitas permutações. Digamos que a chamada board.find() apresenta falha com o resultado POST_FAILED. Então, você deve testar o que acontece quando a falha resulta em RETRYABLE, e testar o que acontece quando a falha resulta em FATAL e assim por diante.
Mas mesmo esses testes são insuficientes. No código típico, os engenheiros assumem que se board.find() funciona, a próxima chamada ao painel, board.move(), também vai funcionar. Na engenharia de sistemas distribuídos de tempo real crítico, não há essa garantia. A máquina do servidor poderia falhar de modo independente em qualquer momento. Como resultado, os engenheiros devem escrever testes para todos os cinco casos para cada chamada ao painel. Digamos que um engenheiro crie 10 cenários para testar na versão de máquina única do Pac-Man. Mas na versão dos sistemas distribuídos, eles precisam testar cada um desses cenários 20 vezes. O que quer dizer que a matriz de teste chega a ser de 10 a 200!
Mas ainda tem mais. O engenheiro pode também ser o proprietário do código do servidor também. Qualquer que seja a combinação de erros do lado do cliente, da rede e dos servidores, eles devem testar para que o cliente e o servidor não fiquem em um estado corrompido. O código do servidor pode ter a seguinte aparência.
handleFind(channel, message)
if !validate(message)
channel.send(INVALID_MESSAGE)
return
if !userThrottle.ok(message.user())
channel.send(RETRYABLE_ERROR)
return
location = database.lookup(message.user())
if location.error()
channel.send(USER_NOT_FOUND)
return
else
channel.send(SUCCESS, location)
handleMove(...)
...
handleFindAll(...)
...
handleRemove(...)
...Estas são quatro funções do lado do servidor a serem testadas. Vamos pressupor que cada função, em uma única máquina, tenha cinco testes cada. Já são 20 testes. Como os clientes enviam várias mensagens ao mesmo servidor, os testes devem simular sequências de solicitações diferentes para garantir que o servidor permaneça robusto. Exemplos de solicitações incluem find, move, remove e findAll.
Digamos que uma construção tenha 10 cenários diferentes com uma média de três chamadas em cada cenário. Já são mais 30 testes. Mas um cenário também precisa testar casos de falha. Para cada um desses testes, é necessário simular o que acontece se o cliente receber qualquer um dos quatro tipos de falha (POST_FAILED, RETRYABLE, FATAL e UNKNOWN) e depois chamar o servidor de novo com uma solicitação inválida. Por exemplo, um cliente pode chamar find com êxito, mas às vezes receber UNKNOWN de volta quando chamar move. Ele pode, depois, chamar find novamente, por outro motivo. O servidor resolverá este caso corretamente? Provavelmente sim, mas você só saberá se testar. Então, assim como no código do lado do cliente, a matriz de teste no lado do servidor é bastante complexa.
Como lidar com unknowns sem detalhes
É alucinante pensar em todas as permutações de falhas que um sistema distribuído pode encontrar, especialmente no caso de várias solicitações. Uma forma que descobrimos para lidar melhor com a engenharia distribuída é desconfiar de tudo. Cada linha do código, a menos que ela não possa causar comunicação com a rede, pode fazer algo diferente do esperado.
Talvez a coisa mais difícil de lidar é o tipo de erro UNKNOWN descrito na seção anterior. O cliente nem sempre sabe se a solicitação teve êxito. Talvez ela tenha realmente movido o Pac-Man (ou em um serviço bancário, retirado dinheiro da conta do usuário), ou talvez não. Como os engenheiros resolvem coisas desse tipo? É difícil porque engenheiros são humanos, e humanos tentem a repudiar a incerteza. Humanos estão acostumados a olhar para o código como a seguir.
bool isEven(number)
switch number % 2
case 0
return true
case 1
return falseOs humanos entendem este código porque ele tem a aparência correspondente ao que ele faz. Os humanos têm dificuldade com a versão distribuída do código, que distribui alguns dos trabalhos a um serviço.
bool distributedIsEven(number)
switch mathServer.mod(number, 2)
case 0
return true
case 1
return false
case UNKNOWN
return WHAT_THE_FARG?É quase impossível para um humano descobrir como lidar com o UNKNOWN da forma correta. O que o UNKNOWN realmente significa? Eles devem repetir o código? Se sim, quantas vezes? Quanto tempo devem esperar entre as tentativas? Fica ainda pior quando o código tem efeitos colaterais. Dentro de um aplicativo de orçamento em execução em uma única máquina, retirar dinheiro de uma conta é fácil, como mostra o próximo exemplo.
class Teller
bool doWithdraw(account, amount)
switch account.withdraw(amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return falseNo entanto, a versão distribuída do aplicativo é estranha por causa do UNKNOWN.
class DistributedTeller
bool doWithdraw(account, amount)
switch this.accountService.withdraw(account, amount)
case SUCCESS
return true
case INSUFFICIENT_FUNDS
return false
case UNKNOWN
return WHAT_THE_FARG?Descobrir como lidar com o tipo de erro UNKNOWN é um dos motivos por que, na engenharia distribuída, as coisas nem sempre são o que parecem.
Hordas dos sistemas distribuídos de tempo real crítico
Os oito modos de falha do apocalipse podem acontecer em qualquer nível de abstração dentro de um sistema distribuído. O exemplo anterior era limitado a uma única máquina do cliente, uma rede e uma máquina do servidor. Mesmo neste cenário simplista, a matriz do estado de falha era bastante complexa. Os sistemas distribuídos reais têm matrizes de estado de falha mais complicadas do que o exemplo da máquina única do cliente. Os sistemas distribuídos reais consistem de várias máquinas que podem ser visualizadas em vários níveis de abstração:
1. Máquinas individuais
2. Grupos de máquinas
3. Grupos de grupos de máquinas
4. E assim por diante (possivelmente)
Por exemplo, um serviço com base na AWS pode agrupar máquinas dedicadas a resolver recursos que estejam em uma zona de disponibilidade específica. Também pode haver dois ou mais grupos de máquinas que lidem com outras duas zonas de disponibilidade. Então, aqueles grupos podem ser agrupados ao grupo da Região da AWS. E esse grupo da Região pode se comunicar (de maneira lógica) com outros grupos de Região. Infelizmente, até mesmo neste nível mais alto, mais lógico, todos os problemas são aplicáveis.
Vamos assumir que um serviço tenha agrupada alguns servidores em um único grupo lógico, o GRUPO1. O GRUPO1 pode, às vezes, mandar mensagens a outro grupo de servidores, o GRUPO2. Isso é um exemplo de engenharia distribuída recursiva. Todos os mesmos modos de falha de redes descritos anteriormente podem ocorrer aqui. Digamos que o GRUPO1 deseja enviar uma solicitação ao GRUPO2. Como mostra o diagrama a seguir, as interações de solicitação/resposta entre as duas máquinas são como aquelas da máquina única discutida anteriormente.
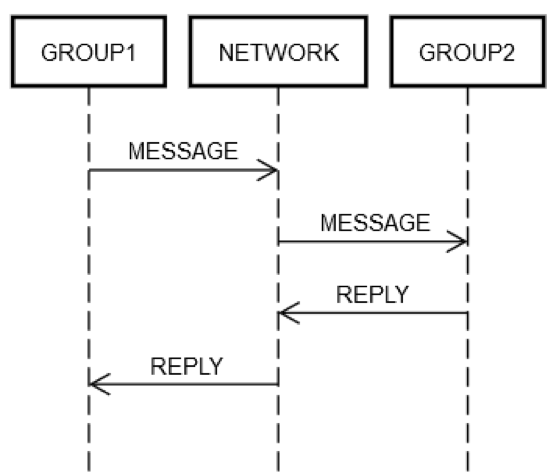
De um jeito ou de outro, alguma máquina dentro do GRUPO1 deve colocar uma mensagem na rede, REDE, endereçada (de maneira lógica) ao GRUPO2. Algumas máquinas dentro do GRUPO2 devem processar a solicitação, e assim por diante. O fato de que o GRUPO1 e o GRUPO2 são compostos por grupos de máquinas não altera os conceitos fundamentais. O GRUPO1, GRUPO2 e a REDE ainda podem ter falhas independentes entre si.
No entanto, esta é apenas a visualização no nível de grupo. Há também a interação no nível máquina-para-máquina dentro de cada grupo. Por exemplo, o GRUPO2 pode ser estruturado como mostra o diagrama a seguir.
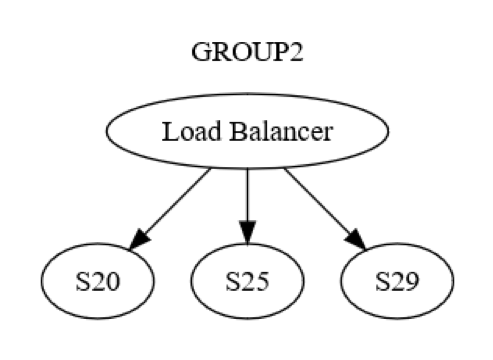
Primeiro, uma mensagem é enviada ao GRUPO2, via load balancer, para uma máquina (possivelmente S20) dentro do grupo. Os designers do sistema sabem que o S20 pode falhar durante a fase UPDATE STATE. Como resultado, o S20 pode precisar passar a mensagem para pelo menos uma outra máquina, para qualquer um de seus pares ou para uma máquina em um grupo diferente. Como o S20 faz isso? Ele envia uma mensagem de solicitação/resposta para, digamos, o S25, como mostra o diagrama a seguir.
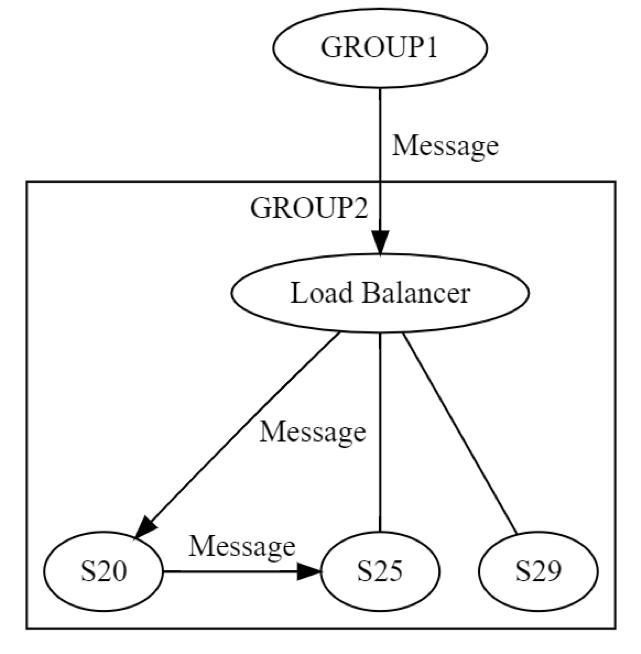
Assim, o S20 está executando o sistema de rede de maneira recursiva. Novamente, todas as oito falhas podem ocorrer, de modo independente. A engenharia distribuída está ocorrendo duas vezes, em vez de uma. A mensagem do GRUPO1 para o GRUPO2, no nível lógico, pode falhar de todas as oito maneiras. Aquela mensagem resulta em outra mensagem, que pode falhar por si só, de modo independente, de todos os oito jeitos discutidos. O teste neste cenário envolveria, pelo menos, o seguinte:
• Um teste para todos os oitos jeitos como o sistema de mensagens do GRUPO1 para o GRUPO2 pode falhar.
• Um teste para todos os oitos jeitos como o sistema de mensagens no nível do servidor S20 a S25 pode falhar.
O exemplo de sistema de mensagens de solicitação/resposta mostra por que os testes de sistemas distribuídos continuam sendo um problema particularmente complicado, mesmo depois de 20 anos de experiência com eles. Os testes são um desafio devido à vastidão de casos de borda, mas é especialmente importante nestes sistemas. Os erros podem demorar para aparecer depois que os sistemas estiverem implantados. E os erros podem ter um impacto amplo e imprevisível a um sistema e aos sistemas adjacentes.
Erros distribuídos muitas vezes são latentes
Se uma falha acontecerá eventualmente, uma suposição comum é que é melhor ocorrer logo do que mais tarde. Por exemplo, é melhor descobrir logo um problema de escalabilidade em um serviço, que exige cerca de seis meses de conserto, pelo menos seis meses antes que o serviço atinja essa escala. Do mesmo modo, é melhor encontrar erros antes que eles afetem a produção. Se os erros afetarem a produção, é melhor encontrá-los logo, antes que afetem os clientes, ou que causem efeitos adversos.
Os erros distribuídos, quer dizer, aqueles que resultam de falha de lidar com todas as permutações dos oito modos de falha do apocalipse, com frequência são graves. Exemplos ao longo do tempo são frequentes em grandes sistemas distribuídos, desde em sistemas de telecomunicações até em sistemas principais de internet. Não somente essas interrupções generalizadas são caras, mas também podem ser causadas por erros que foram implantados na produção, alguns meses antes. A partir daí, leva um tempo para acionar a combinação de cenários que realmente faz com que os erros ocorram (e se espalhem para todo o sistema).
Erros distribuídos se espalham de modo epidêmico
Deixe-me descrever outro problema que é fundamental para os erros distribuídos:
1. Erros distribuídos necessariamente envolvem o uso da rede.
2. Portanto, os erros distribuídos são mais propensos a se espalhar para outras máquinas (ou grupos de máquinas), porque, por definição, eles já envolvem a única coisa que vincula as máquinas.
A Amazon já vivenciou esses erros distribuídos também. Um exemplo antigo, mas relevante, é a falha geral do site www.amazon.com. A falha foi causada por uma falha em um único servidor dentro do serviço de catálogo remoto quando o disco estava cheio.
Devido a uma resolução incorreta dessa condição de erro, o servidor de catálogo remoto começou a devolver respostas vazias a todas as solicitações recebidas. Também começou a devolvê-las muito rápido, pois é mais rápido devolver nada do que alguma coisa (pelo menos neste caso). Enquanto isso, o load balancer entre o site e o serviço de catálogo remoto não percebeu que todas as respostas eram zero. Mas, ele percebeu que elas estavam saindo mais rápido do que em todos os outros servidores de catálogo remoto. Então, ele enviou um alto volume de tráfego de www.amazon.com para o único servidor de catálogo remoto cujo disco estava cheio. Com efeito, todo o site parou porque um servidor remoto não podia exibir nenhuma informação de produto.
Descobrimos este servidor com erro logo e o removemos do serviço para restaurar o site. Depois, acompanhamos nosso processo usual para determinar a causa raiz e identificar os problemas para evitar que a situação se repetisse. Compartilhamos estas lições na Amazon para ajudar a prevenir que outros sistemas tivessem o mesmo problema. Além de aprender as lições específicas sobre o modo de falha, este incidente serviu como um ótimo exemplo de como os modos de falha se propagam rapidamente e de modo imprevisível em sistemas distribuídos.
Resumo dos problemas em sistemas distribuídos
Em resumo, a engenharia de sistemas distribuídos é difícil porque:
• Os engenheiros não conseguem combinar condições de erros. Em vez disso, eles devem considerar as diversas permutações de falhas. A maioria dos erros ocorre a qualquer momento, independentemente de (e, por isso, possivelmente em combinação) qualquer outra condição de erro.
• O resultado de qualquer operação de rede pode ser UNKNOWN, e no caso, a solicitação pode ter tido êxito ou não, pode ter sido recebida, mas não processada.
• Os problemas distribuídos ocorrem em todos os níveis lógicos de um sistema distribuído, não apenas nas máquinas físicas de níveis inferiores.
• Os problemas distribuídos pioram em níveis mais altos do sistema, devido à recursão.
• Os erros distribuídos, com frequência aparecem muito tempo depois de terem sido implantados em um sistema.
• Os erros distribuídos podem se espalhar em um sistema inteiro.
• Muitos dos problemas citados se originam das leis da física de redes, que são imutáveis.
Só porque a computação distribuída é difícil (e estranha) não quer dizer que não existam maneiras de resolver esses problemas. Na Biblioteca do criador da Amazon, nos aprofundamos em como a AWS gerencia os sistemas distribuídos. Esperamos que você considere valiosas as lições que vimos hoje conforme desenvolve para seus clientes.
Sobre o autor

Jacob Gabrielson é um engenheiro-chefe sênior na Amazon Web Services. Ele trabalha na Amazon há 17 anos, principalmente nas plataformas internas de microsserviços. Durante os último 8 anos, ele trabalhou no EC2 e no ECS, incluindo sistemas de implantação de software, serviços de plano de controle, Spot Market, Lightsail e, mais recentemente, contêineres. Jacob é apaixonado por programação de sistemas, linguagens de programação e computação distribuída. O comportamento bimodal do sistema, principalmente em condições de falha, é o que mais o desagrada. Ele é formado em Ciência da Computação pela Universidade de Washington em Seattle.