Crie, treine e implante um modelo de machine learning com o Amazon SageMaker
TUTORIAL
Introdução
Neste tutorial, você aprenderá a usar o Amazon SageMaker para criar, treinar e implantar um modelo de machine learning (ML) usando o algoritmo de ML XGBoost. O Amazon SageMaker é um serviço totalmente gerenciado que fornece a todos os desenvolvedores e cientistas de dados a capacidade de criar, treinar e implantar modelos de ML rapidamente.
Passar modelos ML da conceitualização para a produção pode ser complexo e demorado. Você precisa gerenciar grandes volumes de dados para treinar o modelo, escolher o melhor algoritmo para treiná-lo, gerenciar a capacidade computacional e treiná-la e, depois, implantar o modelo em um ambiente de produção. O Amazon SageMaker reduz essa complexidade, facilitando a criação e implantação de modelos de ML. Depois de escolher os algoritmos e as estruturas de trabalho certas entre as diversas opções disponíveis, o SageMaker gerencia toda a infraestrutura subjacente para treinar o modelo em escala de petabytes e implantá-lo na produção.
Neste tutorial, você assumirá a função de um desenvolvedor de machine learning que trabalha em um banco. Solicitaram que você desenvolva um modelo de machine learning para prever se um cliente se inscreverá para um certificado de depósito (CD).
Neste tutorial, você aprenderá a:
- Criar uma instância de caderno do SageMaker
- Preparar os dados
- Treinar o modelo para aprender com os dados
- Implantar o modelo
- Avaliar a performance do modelo de ML
O modelo será treinado no conjunto de dados de marketing do banco que contém informações sobre as estatísticas populacionais do cliente, respostas a eventos de marketing e fatores externos. Os dados foram rotulados para sua conveniência e uma coluna no conjunto de dados identifica se o cliente está inscrito para um produto oferecido pelo banco. Uma versão deste conjunto de dados está publicamente disponível no repositório de machine learning pré-selecionado pela Universidade da Califórnia, em Irvine.
Os recursos criados e usados neste tutorial estão qualificados para o nível gratuito da AWS. O custo deste workshop é inferior a USD 1.
AWS Experience
Iniciante
Tempo para a conclusão
10 minutos
Custo para a conclusão
Menos de USD 1. Qualificado para o nível gratuito.
Requisitos
- Conta da AWS
- Navegador recomendado: versão mais recente do Chrome ou Firefox
[**] É possível que as contas criadas nas últimas 24 horas ainda não tenham acesso aos serviços necessários para este tutorial.
Serviços usados
Data da última atualização
23 de agosto de 2022
Antes de começar
Você deve ter uma conta da AWS para concluir este tutorial. Caso ainda não tenha uma conta, clique em Cadastre-se na AWS e crie uma nova conta.
Você já tem uma conta?
Faça login na sua conta
Etapa 1: crie uma instância de caderno do Amazon SageMaker
Nesta etapa, você cria a instância do caderno que você usa para baixar e processar os dados. Como parte do processo de criação, você também cria uma função do Identity and Access Management (IAM) que permite ao Amazon SageMaker acessar dados no Amazon Simple Storage Service (Amazon S3).
a. Faça login no console do Amazon SageMaker, e, no canto superior direito, selecione sua região da AWS preferida. Este tutorial usa a região Oeste dos EUA (Oregon).

b. No painel de navegação esquerdo, escolha Instâncias de caderno e clique em Criar instância de caderno.

c. Na página Criar instância de caderno, na caixa Configuração da instância de caderno, preencha os seguintes campos:
- Em Nome da instância de caderno, digite SageMaker-tutorial.
- Para o tipo de instância de caderno, selecione ml.t2.medium.
- Para Inferência elástica, mantenha a seleção padrão como nenhuma.
- Para Identificador de plataforma, mantenha a seleção padrão.

d. Na seção Permissões e criptografia, no perfil do IAM, escolha Criar uma nova função e, na caixa de diálogo Criar um perfil do IAM, selecione Qualquer bucket do S3 e escolha Criar função.
Observação: caso já tenha um bucket que deseja usar, selecione Buckets do S3 específicos e especifique o nome do bucket.

O Amazon SageMaker cria a função AmazonSageMaker-ExecutionRole-***.

e. Mantenha as configurações padrões para as configurações restantes e escolha Criar instância de caderno.
Na seção Instâncias de caderno, a nova instância de caderno SageMaker-Tutorial é exibida com um Status de Pendente. O caderno estará pronto quando o Status for alterado para InService.

Etapa 2: prepare os dados
Nesta etapa, você usa a instância de caderno do Amazon SageMaker para pré-processar os dados necessários para treinar seu modelo de machine learning e, em seguida, fazer o upload dos dados no Amazon S3.
a. Depois que o status da instância do caderno SageMaker-Tutorial mudar para InService, escolha Abrir Jupyter.

b. No Jupyter, escolha Novo e, em seguida, clique em conda_python3.

c. No caderno Jupyter, copie e cole o código a seguir em uma nova célula de código e clique em Executar.
Esse código importa as bibliotecas necessárias e define as variáveis de ambiente de que você precisa para preparar os dados, treinar e implantar o modelo de ML.
# import libraries
import boto3, re, sys, math, json, os, sagemaker, urllib.request
from sagemaker import get_execution_role
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from IPython.display import Image
from IPython.display import display
from time import gmtime, strftime
from sagemaker.predictor import csv_serializer
# Define IAM role
role = get_execution_role()
prefix = 'sagemaker/DEMO-xgboost-dm'
my_region = boto3.session.Session().region_name # set the region of the instance
# this line automatically looks for the XGBoost image URI and builds an XGBoost container.
xgboost_container = sagemaker.image_uris.retrieve("xgboost", my_region, "latest")
print("Success - the MySageMakerInstance is in the " + my_region + " region. You will use the " + xgboost_container + " container for your SageMaker endpoint.")
d. Crie um bucket do S3 para armazenar os dados. Copie e cole o código a seguir na nova célula de código e escolha Executar.
Observação: substitua o bucket_name your-s3-bucket-name por um nome de bucket do S3 exclusivo. Se você não receber uma mensagem de êxito após a execução do código, altere o nome do bucket e tente novamente.
bucket_name = 'your-s3-bucket-name' # <--- CHANGE THIS VARIABLE TO A UNIQUE NAME FOR YOUR BUCKET
s3 = boto3.resource('s3')
try:
if my_region == 'us-east-1':
s3.create_bucket(Bucket=bucket_name)
else:
s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={ 'LocationConstraint': my_region })
print('S3 bucket created successfully')
except Exception as e:
print('S3 error: ',e)
e. Faça o download dos dados para a instância do SageMaker e carregue-os em um quadro de dados. Copie e cole o código a seguir na nova célula de código e escolha Executar.
try:
urllib.request.urlretrieve ("https://d1.awsstatic.com/tmt/build-train-deploy-machine-learning-model-sagemaker/bank_clean.27f01fbbdf43271788427f3682996ae29ceca05d.csv", "bank_clean.csv")
print('Success: downloaded bank_clean.csv.')
except Exception as e:
print('Data load error: ',e)
try:
model_data = pd.read_csv('./bank_clean.csv',index_col=0)
print('Success: Data loaded into dataframe.')
except Exception as e:
print('Data load error: ',e)
f. Embaralhe e divida os dados em dados de treinamento e dados de teste. Copie e cole o código a seguir na nova célula de código e escolha Executar.
Os dados de treinamento (70% dos clientes) são usados durante o ciclo de treinamento de modelos. Você usa a otimização baseada em gradiente para refinar de forma iterativa o modelo de parâmetros. A otimização baseada em gradiente é uma forma de encontrar valores de parâmetro de modelo que minimizam o erro de modelos, usando o gradiente da função de perda de modelos.
Os dados de teste (30% de clientes restantes) são usados para avaliar a performance do modelo e medir até que ponto o modelo treinado é generalizado para dados não examinados.
train_data, test_data = np.split(model_data.sample(frac=1, random_state=1729), [int(0.7 * len(model_data))])
print(train_data.shape, test_data.shape)
Etapa 3: treine o modelo de ML
Nesta etapa, você usa seu conjunto de dados de treinamento para treinar o modelo de machine learning.
a. No caderno Jupyter, copie e cole o código a seguir em uma nova célula de código e clique em Executar.
Esse código reformata o cabeçalho e a primeira coluna dos dados de treinamento e, em seguida, carrega os dados do bucket do S3. Essa etapa é necessária para usar o algoritmo XGBoost pré-criado do Amazon SageMaker.
pd.concat([train_data['y_yes'], train_data.drop(['y_no', 'y_yes'], axis=1)], axis=1).to_csv('train.csv', index=False, header=False)
boto3.Session().resource('s3').Bucket(bucket_name).Object(os.path.join(prefix, 'train/train.csv')).upload_file('train.csv')
s3_input_train = sagemaker.inputs.TrainingInput(s3_data='s3://{}/{}/train'.format(bucket_name, prefix), content_type='csv')
b. Configure a sessão do Amazon SageMaker, crie uma instância do modelo XGBoost (um estimador) e defina os hiperparâmetros do modelo. Copie e cole o código a seguir na nova célula de código e escolha Executar.
sess = sagemaker.Session()
xgb = sagemaker.estimator.Estimator(xgboost_container,role, instance_count=1, instance_type='ml.m4.xlarge',output_path='s3://{}/{}/output'.format(bucket_name, prefix),sagemaker_session=sess)
xgb.set_hyperparameters(max_depth=5,eta=0.2,gamma=4,min_child_weight=6,subsample=0.8,silent=0,objective='binary:logistic',num_round=100)
c. Comece o trabalho de treinamento. Copie e cole o código a seguir na nova célula de código e escolha Executar.
Esse código treina o modelo usando a otimização de gradiente em uma instância ml.m4.xlarge. Depois de alguns minutos, você verá os registros de treinamento sendo gerados no caderno Jupyter.
xgb.fit({'train': s3_input_train})
Etapa 4: implante o modelo
Nesta etapa, você implanta o modelo treinado em um endpoint, reformata e carrega os dados CSV, além de executar o modelo para criar previsões.
a. No caderno Jupyter, copie e cole o código a seguir em uma nova célula de código e clique em Executar.
Esse código implanta o modelo em um servidor e cria um endpoint do SageMaker que você pode acessar. Isso poderá levar alguns minutos para ser concluído.
xgb_predictor = xgb.deploy(initial_instance_count=1,instance_type='ml.m4.xlarge')
b. Para prever se os clientes nos dados de teste se inscreveram ou não para o produto bancário, copie o seguinte código na próxima célula de código e selecione Executar.
from sagemaker.serializers import CSVSerializer
test_data_array = test_data.drop(['y_no', 'y_yes'], axis=1).values #load the data into an array
xgb_predictor.serializer = CSVSerializer() # set the serializer type
predictions = xgb_predictor.predict(test_data_array).decode('utf-8') # predict!
predictions_array = np.fromstring(predictions[1:], sep=',') # and turn the prediction into an array
print(predictions_array.shape)
Etapa 5: avalie a performance do modelo
Nesta etapa, você avalia a performance e a precisão do modelo de machine learning.
No caderno Jupyter, copie e cole o código a seguir em uma nova célula de código e clique em Executar.
Esse código compara os valores reais e previstos em uma tabela chamada matriz de confusão.
Com base na previsão, você poderá concluir que previu a inscrição de um cliente para um certificado de depósito com precisão de 90% para os clientes nos dados de teste, com uma precisão de 65% (278/429) para os inscritos e 90% (10.785/11.928) para os não inscritos.
cm = pd.crosstab(index=test_data['y_yes'], columns=np.round(predictions_array), rownames=['Observed'], colnames=['Predicted'])
tn = cm.iloc[0,0]; fn = cm.iloc[1,0]; tp = cm.iloc[1,1]; fp = cm.iloc[0,1]; p = (tp+tn)/(tp+tn+fp+fn)*100
print("\n{0:<20}{1:<4.1f}%\n".format("Overall Classification Rate: ", p))
print("{0:<15}{1:<15}{2:>8}".format("Predicted", "No Purchase", "Purchase"))
print("Observed")
print("{0:<15}{1:<2.0f}% ({2:<}){3:>6.0f}% ({4:<})".format("No Purchase", tn/(tn+fn)*100,tn, fp/(tp+fp)*100, fp))
print("{0:<16}{1:<1.0f}% ({2:<}){3:>7.0f}% ({4:<}) \n".format("Purchase", fn/(tn+fn)*100,fn, tp/(tp+fp)*100, tp))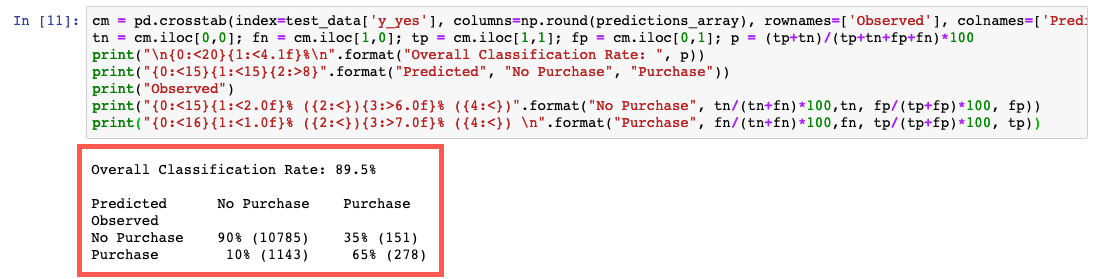
Etapa 6: limpeza
Nesta etapa, você encerra os recursos que você usou neste laboratório.
Importante: é recomendável encerrar os recursos que não estão em uso, pois isso reduz custos. Se os recursos não forem encerrados, sua conta será cobrada.
a. Excluir o endpoint: no caderno Jupyter, copie e cole o seguinte código e clique em Executar.
xgb_predictor.delete_endpoint(delete_endpoint_config=True)b. Exclua os artefatos de treinamento e o bucket do S3: no caderno Jupyter, copie e cole o código a seguir e clique em Executar.
bucket_to_delete = boto3.resource('s3').Bucket(bucket_name)
bucket_to_delete.objects.all().delete()c. Exclua o caderno do SageMaker: pare e exclua o caderno do SageMaker.
- Abra o console do SageMaker.
- Em Cadernos, escolha Instâncias de caderno.
- Escolha a instância do caderno que você criou para este tutorial e, em seguida, escolha Ações, Interromper. A instância de caderno leva vários minutos para ser interrompida. Quando o Status mudar para Interrompido, passe para a próxima etapa.
- Escolha Ações e, em seguida, Excluir.
- Escolha Excluir.
Conclusão
Você aprendeu como usar o Amazon SageMaker para preparar, treinar, implantar e avaliar um modelo de machine learning. O Amazon SageMaker facilita a criação de modelos de ML, fornecendo tudo de que você precisa para se conectar com rapidez aos dados de treinamento e selecionar o melhor algoritmo e estrutura para a sua aplicação, gerenciando toda a infraestrutura subjacente para treinar modelos em escala de petabytes.
Próximas etapas
Agora que você preparou, treinou, implantou e avaliou um modelo de machine learning, você pode aproveitar o que aprendeu explorando outros recursos do Amazon SageMaker.