Что такое вывод Amazon SageMaker?
Amazon SageMaker AI упрощает развертывание моделей машинного обучения, включая базовые модели (FM), для отправки запросов на логические выводы с оптимальным соотношением цены и качества для любых вариантов использования. Можно использовать SageMaker AI для решения любых задач, связанных с выводами: от низких задержек и высокой пропускной способности до длительных логических выводов. SageMaker AI – это полностью управляемый сервис, интегрированный с инструментами MLOps, помогающий вам масштабировать развертывание моделей, сокращать стоимость получения логических выводов, более эффективно управлять моделями в рабочей среде и снижать эксплуатационную нагрузку.
Преимущества SageMaker Inference
Широкий выбор вариантов вывода
Получение логических выводов в режиме реального времени
Бессерверное получение логических выводов
Асинхронные логические выводы
Пакетное преобразование
Масштабируемые и экономичные варианты вывода
Адреса для отдельных моделей
Размещение одной модели в контейнере, размещаемом на выделенных инстансах или в бессерверной среде, обеспечивает низкую задержку и высокую пропускную способность.
Несколько моделей на одном адресе
Для того чтобы повысить эффективность базовых ускорителей и снизить затраты на развертывание до 50 %, несколько моделей необходимо разместить на одном инстансе. Возможность независимого управления политиками масштабирования FM упрощает адаптацию к сценариям использования моделей и оптимизирует затраты, связанные с инфраструктурой.
Конвейеры последовательного получения выводов
Несколько контейнеров совместно используют выделенные инстансы и работают последовательно. Конвейер логических выводов можно использовать для объединения задач предварительной обработки, прогнозирования и последующего анализа данных.
Поддержка большинства фреймворков машинного обучения и серверов моделей
Логический вывод Amazon SageMaker поддерживает встроенные алгоритмы и готовые образы Docker для некоторых наиболее распространенных платформ машинного обучения, таких как TensorFlow, PyTorch, ONNX и XGBoost. Если ни один из готовых образов Docker не отвечает вашим потребностям, вы можете создать собственный контейнер для использования с адресами для нескольких моделей на основе процессора. Логический вывод SageMaker поддерживает большинство серверов популярных моделей, таких как TensorFlow Serving, TorchServe, NVIDIA Triton и сервер AWS для нескольких моделей.
ИИ Amazon SageMaker предлагает специализированные контейнеры глубокого обучения, библиотеки и инструменты для параллелизма моделей и логического вывода больших моделей, которые помогут повысить производительность базовых моделей. С помощью этих опций можно быстро развертывать модели (включая базовые), практически для любого сценария использования.



Высокая производительность логических выводов при низких затратах
Высокая производительность логических выводов при низких затратах
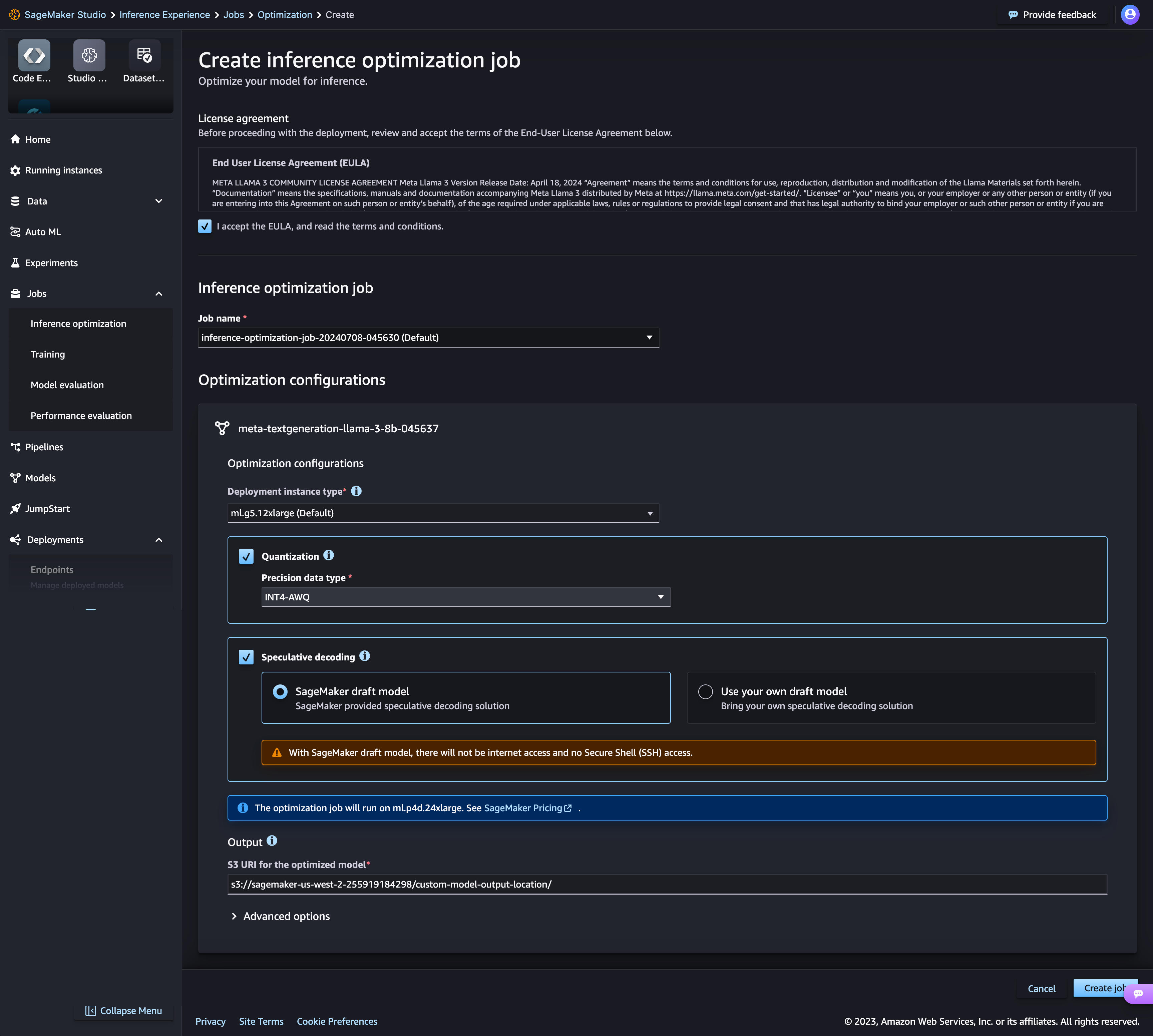
Новый набор инструментов для оптимизации логических выводов в Amazon SageMaker AI обеспечивает двукратное увеличение пропускной способности при снижении затрат приблизительно на 50 % для моделей на основе генеративного искусственного интеллекта (Llama 3, Mistral и Mixtral). Например, в модели Llama 3-70B можно получить до 2400 токенов в секунду на инстансе ml.p5.48xlarge по сравнению с 1200 токенами до оптимизации. Можно выбрать разные методы оптимизации модели или комбинировать их использование. Например, доступны методы спекулятивного декодирования, квантования и компиляции. Примените их к своим моделям и запустите оценочное тестирование, чтобы сравнить влияние методов на качество итоговых потоков и производительность логических выводов, а затем разверните модель буквально за несколько минут.
Развертывайте модели в самой высокопроизводительной инфраструктуре или переходите на бессерверное решение
Amazon SageMaker AI включает более 70 типов инстансов с различными уровнями вычислительных ресурсов и памяти, включая инстансы Amazon EC2 Inf1 на базе AWS Inferentia, высокопроизводительные чипы логических выводов машинного обучения, разработанные и созданные AWS, и инстансы с графическими процессорами, такие как Amazon EC2 G4dn. Кроме того, вы можете выбрать Бессерверный вывод Amazon SageMaker, что обеспечит возможности простого масштабирования до тысяч моделей на адрес, пропускную способность в миллионы транзакций в секунду (TPS) и задержку менее 10 миллисекунд.

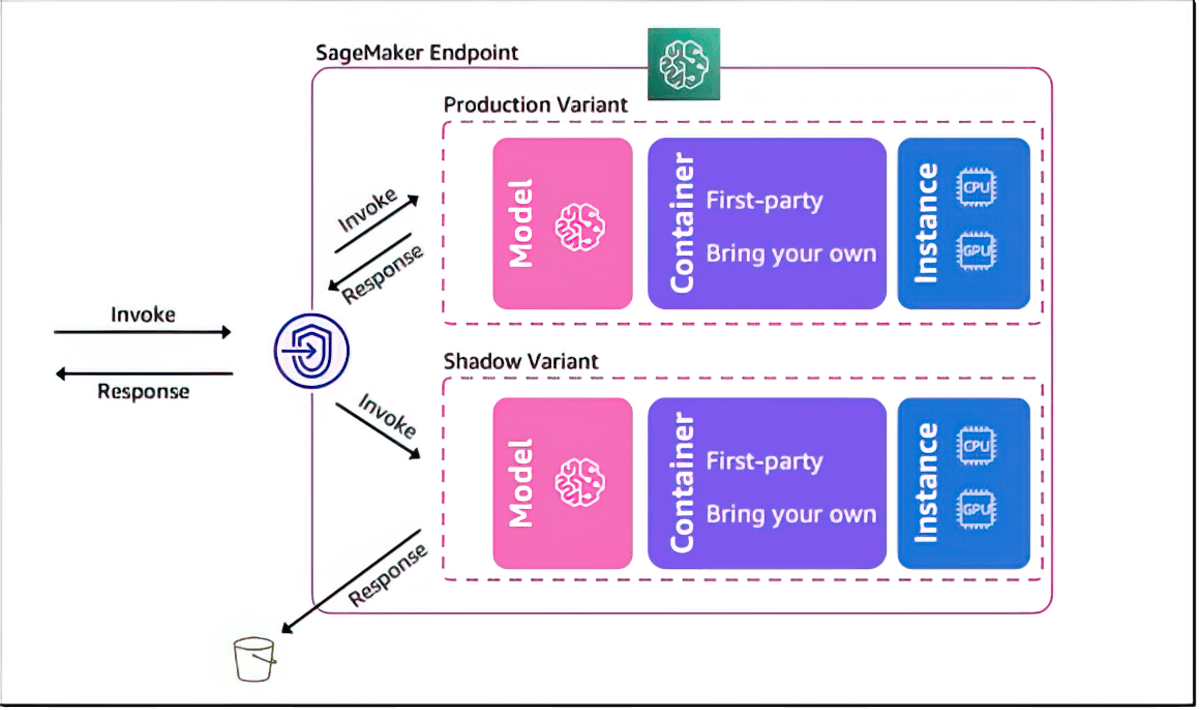
Теневой тест для оценки производительности моделей машинного обучения
Amazon SageMaker AI помогает оценить новую модель путем теневого тестирования ее производительности по сравнению с текущей развернутой моделью SageMaker с помощью запросов выводов в режиме реального времени. Теневое тестирование помогает выявить потенциальные ошибки конфигурации и проблемы с производительностью до того, как они повлияют на конечных пользователей. Благодаря SageMaker AI вам не нужно тратить недели на создание собственной инфраструктуры теневого тестирования. Просто выберите рабочую модель, которую хотите протестировать, и SageMaker AI автоматически выполнит развертывание новой модели в теневом режиме, а также направит копии запросов выводов, полученных рабочей моделью, в новую модель в режиме реального времени.
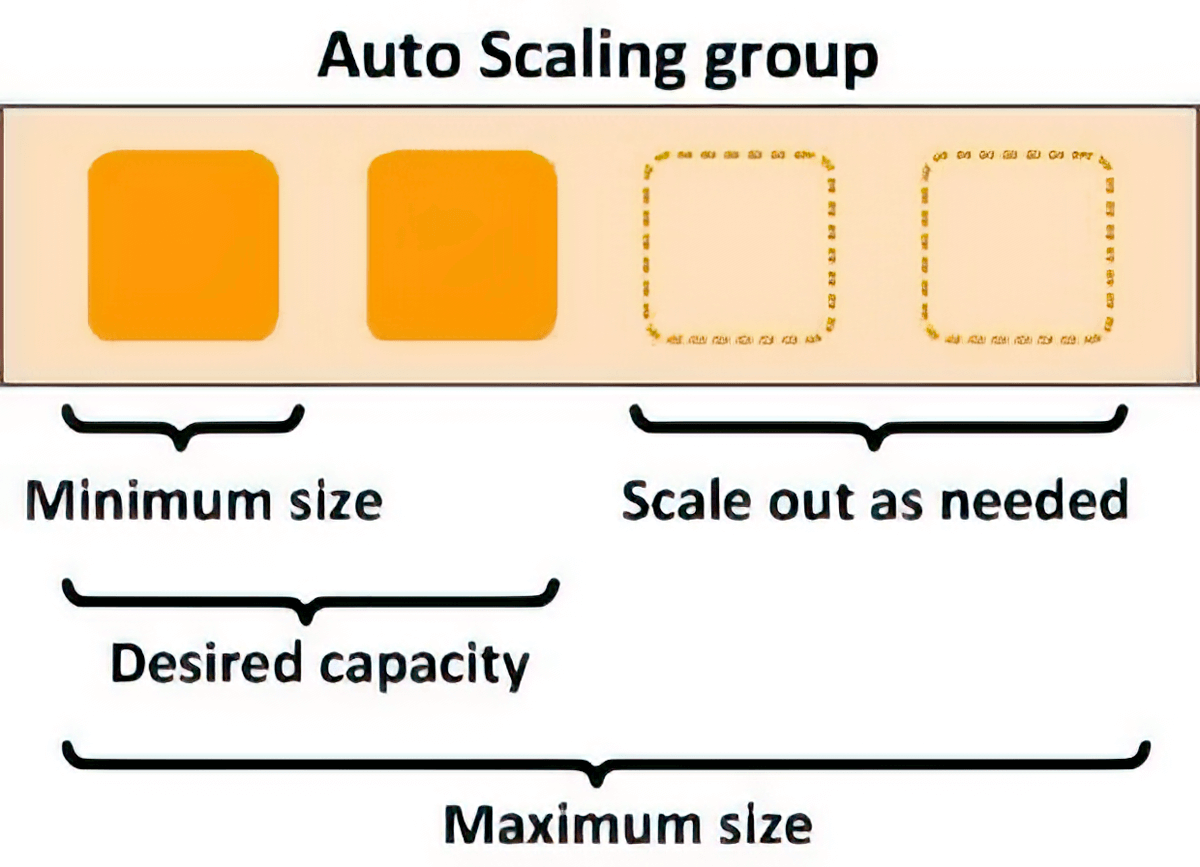
Автоматическое масштабирование для повышения эластичности
Политики масштабирования можно использовать для автоматического масштабирования базовых вычислительных ресурсов в соответствии с колебаниями запросов на выводы. Вы можете управлять политиками масштабирования для каждой модели машинного обучения отдельно, что помогает упростить обработку изменений в использовании модели, а также оптимизировать затраты на инфраструктуру.
Уменьшение задержек и интеллектуальная маршрутизация
Вы можете сократить задержку получения логического вывода для моделей машинного обучения за счет интеллектуальной маршрутизации новых запросов выводов в доступные инстансы вместо случайной маршрутизации запросов в инстансы, которые уже заняты обработкой других запросов, что позволяет снизить задержку получения выводов в среднем на 20 %.
Снижение эксплуатационной нагрузки и быстрая окупаемость
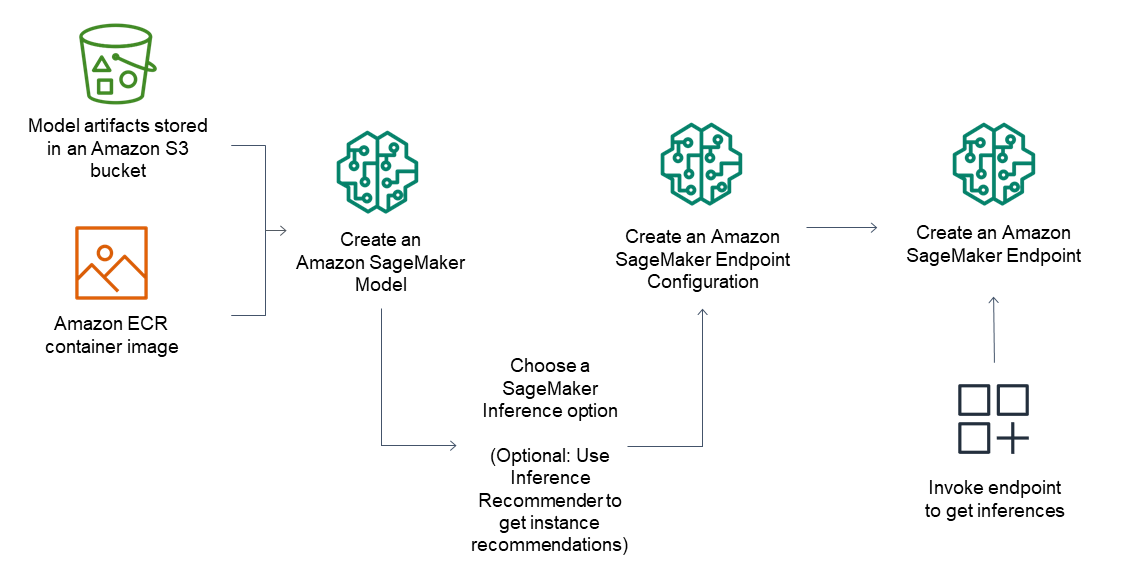
Полностью управляемый хостинг и управление моделями
Amazon SageMaker AI – полностью управляемый сервис для настройки инстансов, совместимостей с версиями ПО, а также исправлений версий и управления ими. Он также предоставляет встроенные метрики и журналы для адресов, которые можно использовать для мониторинга и получения оповещений.
Встроенная интеграция с функциями MLOps
Функции развертывания модели Amazon SageMaker AI интегрированы в MLOps, включая конвейеры SageMaker (автоматизация и оркестрация рабочих процессов), проекты SageMaker (CI/CD для машинного обучения), хранилище функций SageMaker (управление функциями), реестр моделей SageMaker (каталог моделей и артефактов для отслеживания происхождения и поддержки автоматизированных рабочих процессов утверждения), SageMaker Clarify (обнаружение смещений) и монитор модели SageMaker (обнаружение отклонений концепции и модели). В конечном итоге, независимо от того, развертываете ли вы одну модель или десятки тысяч, SageMaker AI помогает снизить эксплуатационные издержки, связанные с развертыванием, масштабированием и управлением моделями машинного обучения, а также ускорить их внедрение в рабочую среду.
Клиенты



Ресурсы для SageMaker Inference
Что нового?
Total results: 37
- По дате (от новых к старым)
-
30.01.2025
-
11.12.2024
-
06.12.2024
-
06.12.2024
-
04.12.2024