自動建立機器學習模型
使用 Amazon SageMaker Autopilot
Amazon SageMaker 是一項全受管服務,能讓所有開發人員和資料科學家快速地建置、訓練及部署機器學習 (ML) 模型。
在本教學中,您可以自動建立機器學習模型,無須撰寫任何程式碼! Amazon SageMaker Autopilot 是一種 AutoML 功能,可自動建立最佳的分類和迴歸機器學習模型,同時擁有完整的控制和可見性。
在本教學中,您將了解如何:
- 建立 AWS 帳戶
- 設定 Amazon SageMaker Studio 以存取 Amazon SageMaker Autopilot
- 使用 Amazon SageMaker Studio 下載公用資料集
- 使用 Amazon SageMaker Autopilot 建立訓練實驗
- 探索訓練實驗的不同階段
- 從訓練實驗找出效能最佳的模型並進行部署
- 使用部署的模型進行預測
在本教學中,您將扮演在銀行工作的開發人員角色。公司要求您開發一款機器學習模型,用於預測客戶是否會註冊定期存單 (CD)。該模型將使用行銷資料集進行訓練,其中該資料集包含有關客戶人口統計、對行銷事件的回應以及外部因素的資訊。
| 關於本教學 | |
|---|---|
| 時間 | 10 分鐘 |
| 費用 | 低於 10 USD |
| 使用案例 | Machine Learning |
| 產品 | Amazon SageMaker |
| 對象 | 開發人員 |
| 等級 | 初階 |
| 上次更新日期 | 2020 年 5 月 12 日 |
步驟 1.建立 AWS 帳戶
本研討會的費用低於 10 USD。如需詳細資訊,請參閱 Amazon SageMaker Studio 定價。
步驟 2.設定 Amazon SageMaker Studio
完成下列步驟,即可加入 Amazon SageMaker Studio 存取 to Amazon SageMaker Autopilot。
注意:如需詳細資訊,請參閱 Amazon SageMaker 文件中的開始使用 Amazon SageMaker Studio。
a.登入 Amazon SageMaker 主控台。
注意:在右上角,請確認選取可使用 Amazon SageMaker Studio 的 AWS 區域。如需區域清單,請參閱加入 Amazon SageMaker Studio。


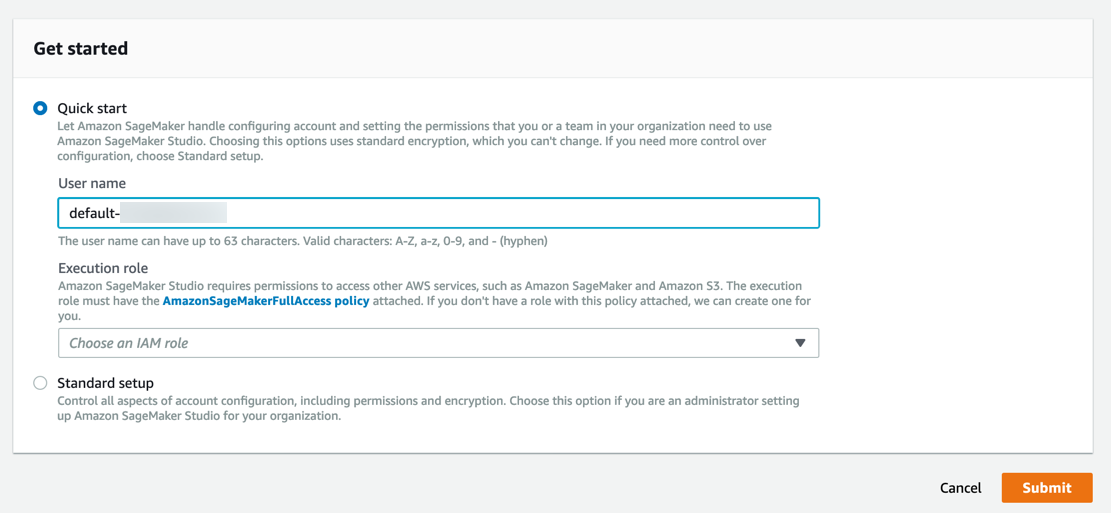
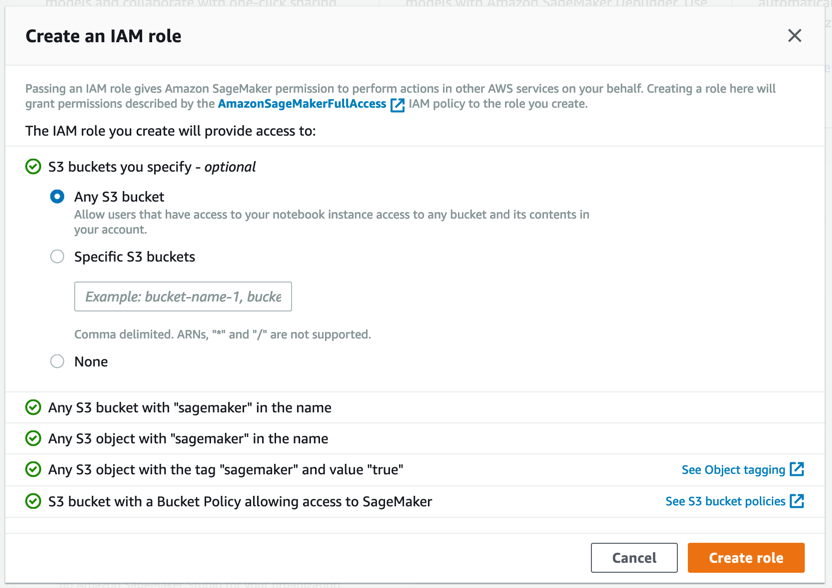
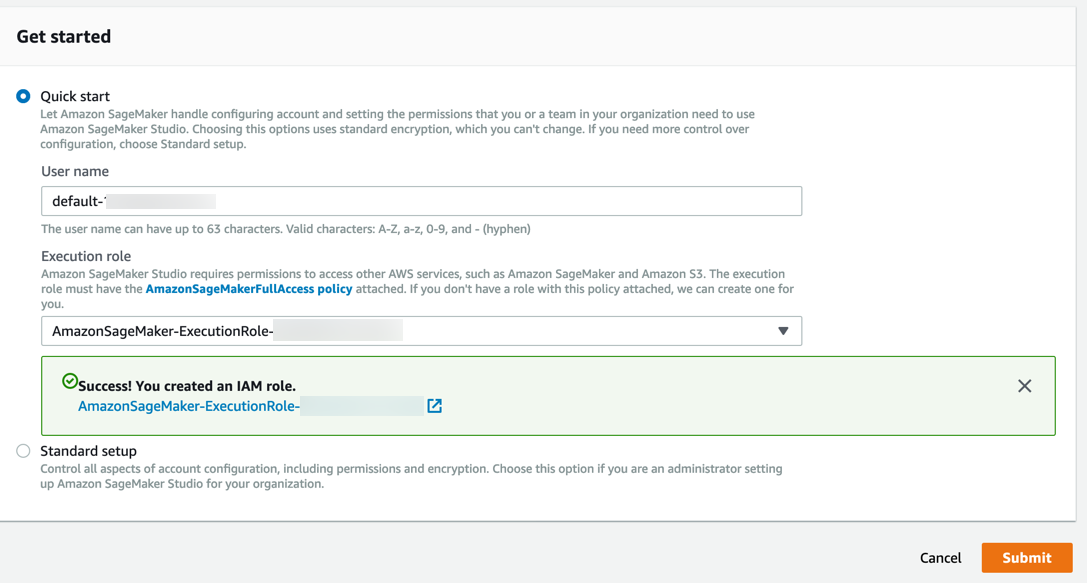
Amazon SageMaker 會建立具備必要許可的角色,並將其指派到您的執行個體。
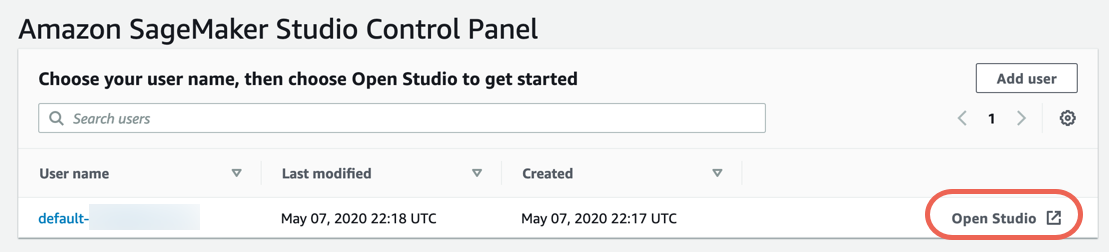
步驟 3.下載資料集
完成下列步驟,下載和探索資料集。
注意:如需詳細資訊,請參閱 Amazon SageMaker 文件中的 Amazon SageMaker Studio 導覽。
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d.複製下列程式碼並將其貼到新的程式碼儲存格,然後選取執行。
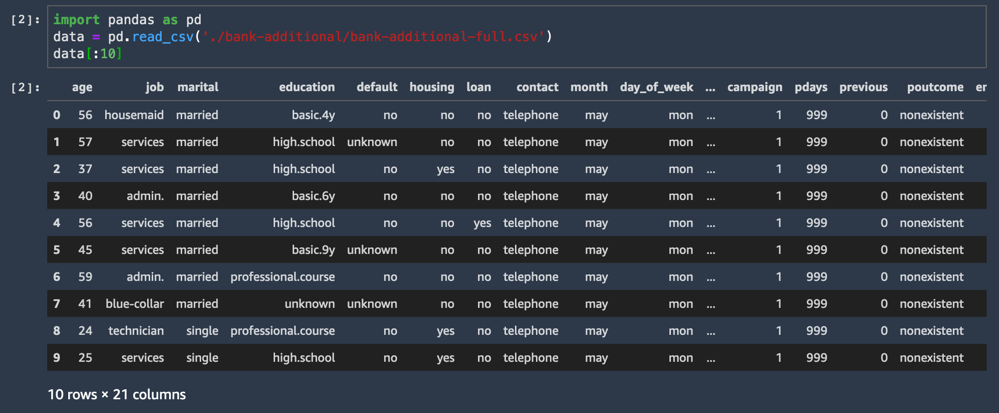
CSV 資料集會載入並顯示前十行。
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]其中一個資料集欄名為 y,代表每個樣本的標籤:這名客戶是否接受提議?
資料科學家會在這個步驟開始探索資料、建立新的功能等等。使用 Amazon SageMaker Autopilot,您不需要執行任何這些額外的步驟。您只需上傳檔案中使用逗號分隔值的表格式資料 (例如,從試算表或資料庫),然後選擇要預測的目標欄,Autopilot 就會為您建立一個預測模型。
d.複製下列程式碼並將其貼到新的程式碼儲存格,然後選取執行。
這個步驟會將 CSV 資料集上傳到 Amazon S3 儲存貯體。您不需要建立 Amazon S3 儲存貯體;上傳資料時,Amazon SageMaker 會自動在您的帳戶建立預設儲存貯體。
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
您完成了! 程式碼輸出顯示 S3 儲存貯體 URI,如以下範例所示:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csv記住在自己筆記本寫下的 S3 URI。您在下個步驟會用到。

步驟 4.建立 SageMaker Autopilot 實驗
您已在 Amazon S3 下載並分階處理資料集,現在可以建立 Amazon SageMaker Autopilot 實驗。實驗是指與同一個機器學習專案相關的一組處理和訓練工作。
完成下列步驟以建立新的實驗。
注意:如需詳細資訊,請參閱 Amazon SageMaker 文件中的在 SageMaker Studio 中建立 Amazon SageMaker Autopilot 實驗。
a.在 Amazon SageMaker Studio 的左側導覽窗格中,選擇實驗 (圖示用燒瓶表示),然後選擇建立實驗。
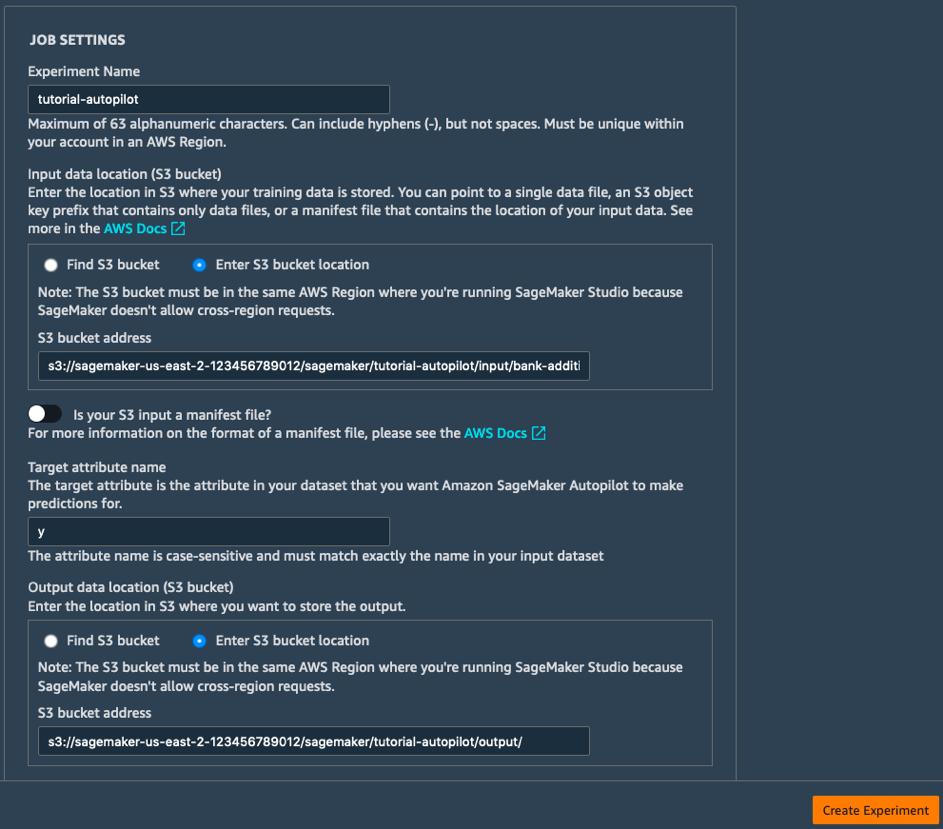
b.填寫任務設定欄位,如下所示:
- 實驗名稱:tutorial-autopilot
- 輸入資料的 S3 位置:前面您寫下的 S3 URI
(例如,s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - 目標屬性名稱:y
- 輸入資料的 S3 位置:s3://sagemaker-us-east-2-[ACCOUNT-NUMBER]/sagemaker/tutorial-autopilot/output
(記得將 [ACCOUNT-NUMBER] 換成自己的帳號)
c.所有其他設定保留預設值,然後選取建立實驗。
成功! 這樣即可開始 Amazon SageMaker Autopilot 實驗! 這個程序會產生模型和統計資料,您可以在實驗進行時即時查看這些資料。實驗完成後,您可以查看試驗、按目標指標排序,然後按滑鼠右鍵來部署模型,以便在其他環境中使用。
步驟 5.探索 SageMaker Autopilot 實驗階段
實驗進行時,您可以學習和探索 SageMaker Autopilot 實驗的各個階段。
本節將提供更多與 SageMaker Autopilot 實驗階段有關的詳細資訊:
- 分析資料
- 功能工程
- 模型調整
注意:如需詳細資訊,請參閱 SageMaker Autopilot 筆記本輸出。
分析資料
分析資料階段可找出需要解決的問題類型 (線性迴歸、二進位分類、多元分類)。接著,產生十個候選管道。管道結合了資料預先處理步驟 (處理遺漏值、設計新功能等),以及模型訓練步驟,該步驟使用 ML 演算法比對問題類型。這個步驟完成後,該任務會進入功能工程階段。
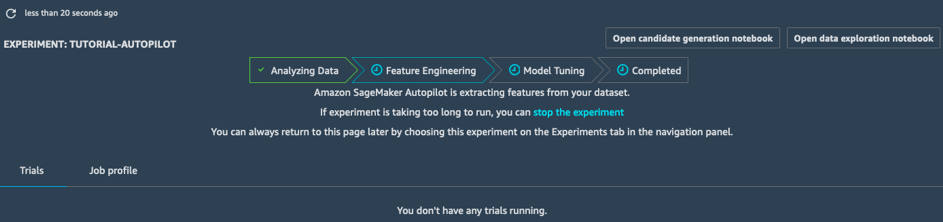
功能工程
在功能工程階段,該實驗會為每個候選管道建立訓練和驗證資料集,將所有成品儲存到 S3 儲存貯體中。在功能工程階段,您可以開啟並檢視兩個自動產生的筆記本:
- 資料探索筆記本包含與資料集相關的資訊和統計資料。
- 候選產成筆記本包含十個管道的定義。事實上,這是可執行的筆記本:您可以完整重建 AutoPilot 任務執行的每個步驟、了解不同模型的建構方式,如有需要甚至可以持續調整這些模型。
有了這兩本筆記本,您可以詳細了解預先處理資料的方式,以及模型的建構和優化方法。這種透明化是 Amazon SageMaker Autopilot 的重要功能。
模型調整
在模型調整階段,SageMaker Autopilot 會針對每個候選管道和其預先處理的資料集啟動超參數優化任務;相關的訓練任務會探索各種超參數值,並迅速聚集到高效能模型。
這個階段完成後,SageMaker Autopilot 任務即完成。您可以在 SageMaker Studio 查看並探索所有任務。
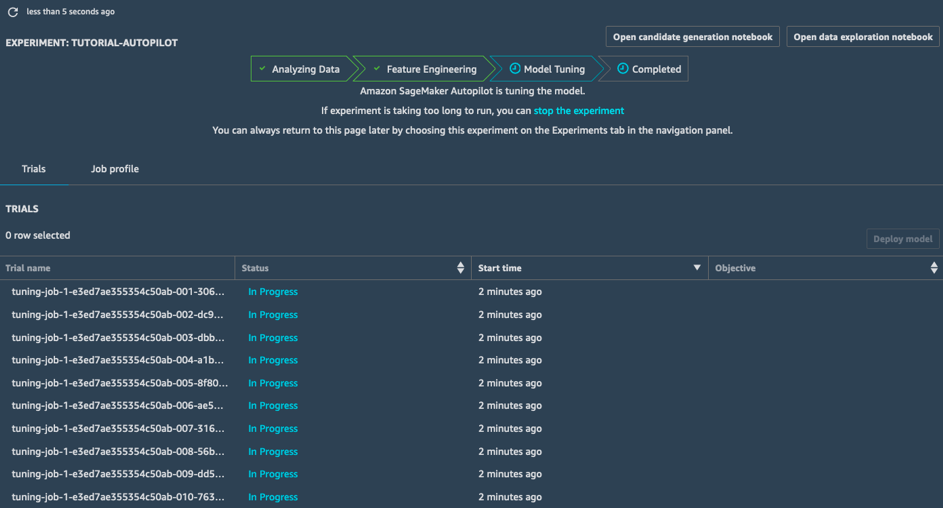
步驟 6.部署最佳模型
a.在實驗的試用清單中,選擇目標旁邊的胡蘿蔔,依降冪排序調整任務。最佳調整任務會以星號標示。
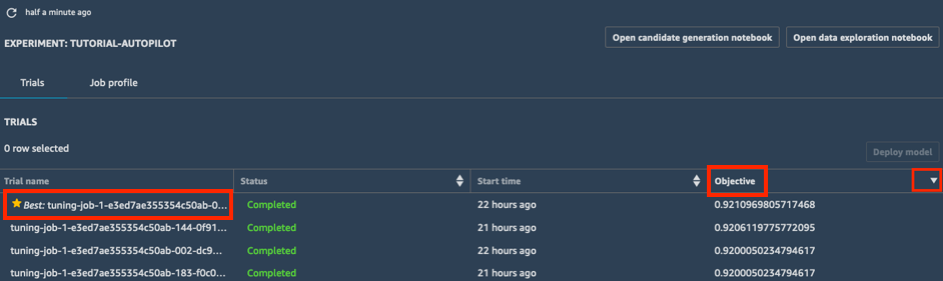
b.選取最佳調整任務 (以星號標示) 並選擇部署模型。
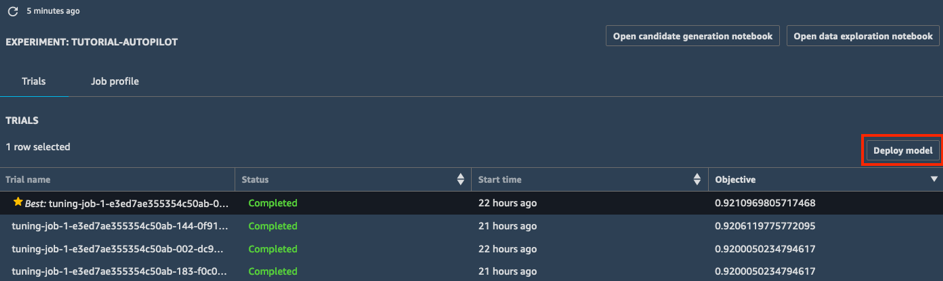
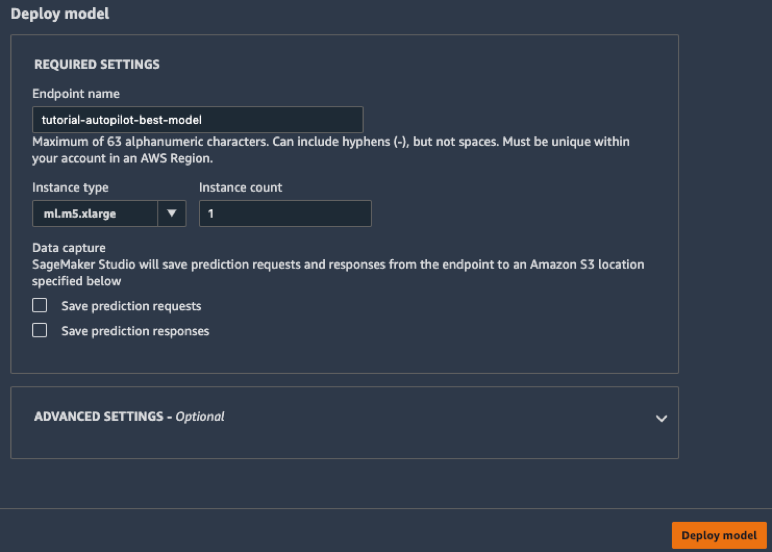
c.在部署模型方塊中,為端點命名 (例如,tutorial-autopilot-best-model) 並保留所有設定為預設值。選擇部署模型。
您的模型會部署至 Amazon SageMaker 管理的 HTTPS 端點。
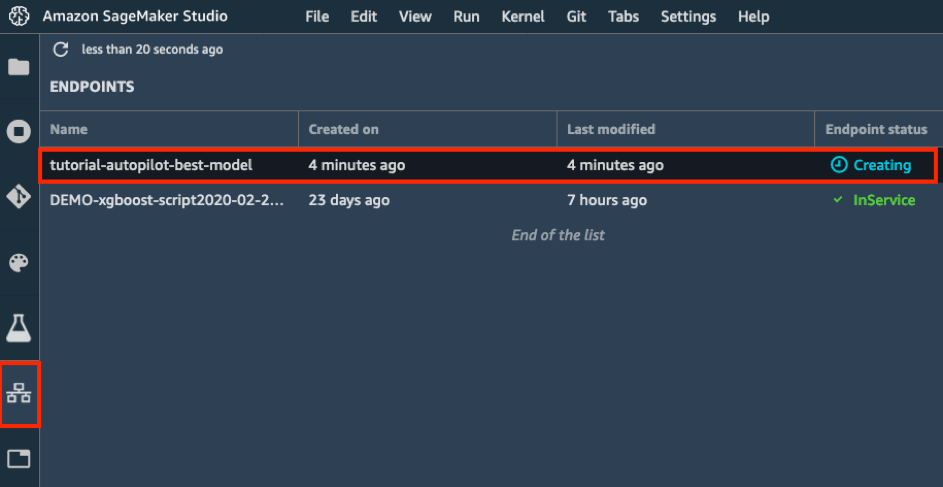
d.在左側工具列中,選擇端點圖示。您可以看到系統正在建立模型,需要花費幾分鐘的時間。當端點狀態為 InService,您即可傳送資料和接收預測!
步驟 7.使用模型預測
現在已經部署模型,您可以預測資料集的前 2,000 個樣本。若要這麼做,請使用 boto3 SDK 中的 invoke_endpoint API。在此過程中,您將運算重要的機器學習指標:正確性、準確性、召回率和 F1 分數。
按照這些步驟使用模型進行預測。
注意:如需詳細資訊,請參閱使用 Amazon SageMaker 實驗管理機器學習。
在 Jupyter 筆記本中,複製並貼上以下程式碼,然後選擇執行。
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
您應會看到以下輸出。
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
此輸出是一個進度指示器,顯示已預測的樣本數量!
步驟 8.清理
在此步驟,您將終止在此實驗室中使用的資源。
重要:終止非使用中的資源可降低成本,這是最佳實務。未終止資源將使您的帳戶產生費用。
刪除您的端點:在 Jupyter 筆記本中,複製並貼上以下程式碼,然後選擇執行。
sess.delete_endpoint(endpoint_name=ep_name)如果要清理所有訓練成品 (模型、預先處理的資料集等),請複製以下程式碼並將其貼到您的程式碼儲存格中,然後選擇執行。
注意:記得將 [ACCOUNT-NUMBER] 換成您的帳號。
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/建議的後續步驟
進行 Amazon SageMaker Studio 導覽
進一步了解 Amazon SageMaker Autopilot
如需進一步了解,請閱讀部落格文章或參閱 Autopilot 影片系列。