概觀
在此教學中,了解如何使用 Amazon SageMaker Pipelines、Amazon SageMaker 模型登錄檔和 Amazon SageMaker Clarify 建立和自動化端對端機器學習 (ML) 工作流程。
SageMaker Pipelines 是第一款專門針對 ML 打造的持續整合和持續交付 (CI/CD) 服務。藉助 SageMaker Pipelines,您可以自動化 ML 工作流程的不同步驟,包括資料載入、資料轉換、訓練、調整、評估以及部署。透過 SageMaker 模型登錄檔,您可以在一個中央儲存庫中追蹤模型版本及其中繼資料 (例如使用案例分組以及模型效能指標基準),從而輕鬆根據業務需求選擇適當的部署模型。SageMaker Clarify 可讓您更清楚地了解訓練資料和模型,以便識別和限制偏差,並解釋預測。
在此教學中,您將實作 SageMaker 管道,建置、訓練和部署 XGBoost 二進制分類模型,以預測汽車保險索賠為詐騙的可能性。您將使用綜合產生的汽車保險索賠資料集。原始輸入是兩個保險資料表:一個索賠表和一個客戶表。索賠表有一個名為 fraud (詐騙) 的欄,表明索賠是否為詐騙性。管道將處理原始資料;建立訓練、驗證和測試資料集;建立並評估二進制分類模型。然後,它將使用 SageMaker Clarify 來測試模型偏差和可解釋性,並在最後部署模型以進行推斷。
要完成的內容
在本指南中,您將:
- 建置並執行 SageMaker 管道以自動化端對端 ML 生命週期
- 使用部署的模型產生預測
先決條件
在開始本指南之前,您需要具備:
- AWS 帳戶:如果您還沒有,請按照設定您的 AWS 環境快速入門指南進行操作。
AWS 經驗
完成時間
120 分鐘
完成成本
請參閱 SageMaker 定價以估算本教學的成本。
要求
您必須登入 AWS 帳戶。
使用的服務
Amazon SageMaker Studio、Amazon SageMaker Pipelines、Amazon SageMaker Clarify、Amazon SageMaker 模型登錄檔
上次更新日期
2022 年 6 月 24 日
實作
步驟 1:設定 Amazon SageMaker Studio 網域
每個 AWS 帳戶在每個區域只能擁有一個 SageMaker Studio 網域。如果您在美國東部 (維吉尼亞北部) 區域已有 SageMaker Studio 網域,請按照 SageMaker Studio ML 工作流程設定指南將所需的 AWS IAM 政策連接到您的 SageMaker Studio 帳戶,然後略過步驟 1,並直接進行步驟 2。
如果您沒有現有的 SageMaker Studio 網域,請繼續進行步驟 1 以執行 AWS CloudFormation 範本,該範本將建立 SageMaker Studio 網域,並新增本教學其餘部分所需的許可。
選擇 AWS CloudFormation 堆疊連結。此連結將開啟 AWS CloudFormation 主控台,並建立您的 SageMaker Studio 網域和名為 studio-user 的使用者。它還會向您的 SageMaker Studio 帳戶新增所需的許可。在 CloudFormation 主控台中,確認右上角顯示的 Region (區域) 是 US East (N. Virginia) (美國東部 (維吉尼亞北部))。 Stack name (堆疊名稱) 應為 CFN-SM-IM-Lambda-catalog,且不應變更。 此堆疊大約需要 10 分鐘來建立所有資源。
此堆疊假定您已經在您的帳戶中設定了公有 VPC。如果您沒有公有 VPC,請參閱具有單一公有子網路的 VPC,了解如何建立公有 VPC。

選取 I acknowledge that AWS CloudFormation might create IAM resources (我認知 AWS CloudFormation 可能會建立 IAM 資源),然後選擇 Create stack (建立堆疊)。

在 CloudFormation 窗格中,選擇 Stacks (堆疊)。建立此堆疊約需要 10 分鐘。建立該堆疊後,堆疊狀態從 CREATE_IN_PROGRESS 變更為 CREATE_COMPLETE。

步驟 2:設定 SageMaker Studio 筆記本並參數化管道
在此設定中,您將啟動一個新的 SageMaker Studio 筆記本,並設定與 Amazon Simple Storage Service (Amazon S3) 互動所需的 SageMaker 變數。
在 AWS Console 搜尋列中輸入 SageMaker Studio,然後選擇 SageMaker Studio。 從主控台右上角的 Region (區域) 下拉式清單中選擇 US East (N. Virginia) (美國東部 (維吉尼亞北部))。

對於 Launch app (啟動應用程式),選取 Studio 以開啟 SageMaker Studio 並使用 studio-user 設定檔。

在 SageMaker Studio 導覽列上,選擇 File (檔案)、New (新增)、Notebook (筆記本)。

在 Set up notebook environment (設定筆記本環境) 對話方塊中的 Image (映像) 下,選取 Data Science (資料科學)。將自動選取 Python 3 核心。選擇 Select (選取)。

筆記本右上角上的核心現在應顯示 Python 3 (Data Science) (Python 3 (資料科學))。

若要匯入所需的程式庫,將以下程式碼複製並貼到筆記本中的儲存格中,然後執行儲存格。
import pandas as pd
import json
import boto3
import pathlib
import io
import sagemaker
from sagemaker.deserializers import CSVDeserializer
from sagemaker.serializers import CSVSerializer
from sagemaker.xgboost.estimator import XGBoost
from sagemaker.sklearn.processing import SKLearnProcessor
from sagemaker.processing import (
ProcessingInput,
ProcessingOutput,
ScriptProcessor
)
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import (
ProcessingStep,
TrainingStep,
CreateModelStep
)
from sagemaker.workflow.check_job_config import CheckJobConfig
from sagemaker.workflow.parameters import (
ParameterInteger,
ParameterFloat,
ParameterString,
ParameterBoolean
)
from sagemaker.workflow.clarify_check_step import (
ModelBiasCheckConfig,
ClarifyCheckStep,
ModelExplainabilityCheckConfig
)
from sagemaker.workflow.step_collections import RegisterModel
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.properties import PropertyFile
from sagemaker.workflow.condition_step import ConditionStep
from sagemaker.workflow.functions import JsonGet
from sagemaker.workflow.lambda_step import (
LambdaStep,
LambdaOutput,
LambdaOutputTypeEnum,
)
from sagemaker.lambda_helper import Lambda
from sagemaker.model_metrics import (
MetricsSource,
ModelMetrics,
FileSource
)
from sagemaker.drift_check_baselines import DriftCheckBaselines
from sagemaker.image_uris import retrieve將以下程式碼區塊複製並貼到儲存格中並執行,以使用 SageMaker 和 AWS 開發套件設定 SageMaker 和 S3 用戶端物件。SageMaker 需要這些物件來執行各種動作,例如部署和叫用端點,以及與 Amazon S3 和 AWS Lambda 互動。該程式碼還設定了儲存原始資料集和經處理資料集與模型成品的 S3 儲存貯體位置。請注意,讀取和寫入儲存貯體是相互獨立的。讀取儲存貯體是名為 sagemaker-sample-files 的公有 S3 儲存貯體,其中包含原始資料集。 寫入儲存貯體是與您名為 sagemaker-<您的區域>-<您的帳戶 ID> 的帳戶關聯的預設 S3 儲存貯體,本教學稍後部分將使用它來儲存經處理的資料集和成品。
# Instantiate AWS services session and client objects
sess = sagemaker.Session()
write_bucket = sess.default_bucket()
write_prefix = "fraud-detect-demo"
region = sess.boto_region_name
s3_client = boto3.client("s3", region_name=region)
sm_client = boto3.client("sagemaker", region_name=region)
sm_runtime_client = boto3.client("sagemaker-runtime")
# Fetch SageMaker execution role
sagemaker_role = sagemaker.get_execution_role()
# S3 locations used for parameterizing the notebook run
read_bucket = "sagemaker-sample-files"
read_prefix = "datasets/tabular/synthetic_automobile_claims"
# S3 location where raw data to be fetched from
raw_data_key = f"s3://{read_bucket}/{read_prefix}"
# S3 location where processed data to be uploaded
processed_data_key = f"{write_prefix}/processed"
# S3 location where train data to be uploaded
train_data_key = f"{write_prefix}/train"
# S3 location where validation data to be uploaded
validation_data_key = f"{write_prefix}/validation"
# S3 location where test data to be uploaded
test_data_key = f"{write_prefix}/test"
# Full S3 paths
claims_data_uri = f"{raw_data_key}/claims.csv"
customers_data_uri = f"{raw_data_key}/customers.csv"
output_data_uri = f"s3://{write_bucket}/{write_prefix}/"
scripts_uri = f"s3://{write_bucket}/{write_prefix}/scripts"
estimator_output_uri = f"s3://{write_bucket}/{write_prefix}/training_jobs"
processing_output_uri = f"s3://{write_bucket}/{write_prefix}/processing_jobs"
model_eval_output_uri = f"s3://{write_bucket}/{write_prefix}/model_eval"
clarify_bias_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/bias_config"
clarify_explainability_config_output_uri = f"s3://{write_bucket}/{write_prefix}/model_monitor/explainability_config"
bias_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/bias"
explainability_report_output_uri = f"s3://{write_bucket}/{write_prefix}/clarify_output/pipeline/explainability"
# Retrieve training image
training_image = retrieve(framework="xgboost", region=region, version="1.3-1")複製並貼上以下程式碼,以設定各種 SageMaker 管道元件 (例如模型和端點) 的名稱,並指定訓練和推論執行個體類型及數量。這些值將用於參數化管道。
# Set names of pipeline objects
pipeline_name = "FraudDetectXGBPipeline"
pipeline_model_name = "fraud-detect-xgb-pipeline"
model_package_group_name = "fraud-detect-xgb-model-group"
base_job_name_prefix = "fraud-detect"
endpoint_config_name = f"{pipeline_model_name}-endpoint-config"
endpoint_name = f"{pipeline_model_name}-endpoint"
# Set data parameters
target_col = "fraud"
# Set instance types and counts
process_instance_type = "ml.c5.xlarge"
train_instance_count = 1
train_instance_type = "ml.m4.xlarge"
predictor_instance_count = 1
predictor_instance_type = "ml.m4.xlarge"
clarify_instance_count = 1
clarify_instance_type = "ml.m4.xlarge"SageMaker Pipelines 支援參數化,允許您在執行時間指定輸入參數,而無需變更管道程式碼。您可以使用 sagemaker.workflow.parameters 模組下提供的模組 (例如 ParameterInteger、ParameterFloat、ParameterString 和 ParameterBoolean) 來指定不同資料類型的管道參數。複製、貼上並執行以下程式碼,以設定多個輸入參數,包括 SageMaker Clarify 組態。
# Set up pipeline input parameters
# Set processing instance type
process_instance_type_param = ParameterString(
name="ProcessingInstanceType",
default_value=process_instance_type,
)
# Set training instance type
train_instance_type_param = ParameterString(
name="TrainingInstanceType",
default_value=train_instance_type,
)
# Set training instance count
train_instance_count_param = ParameterInteger(
name="TrainingInstanceCount",
default_value=train_instance_count
)
# Set deployment instance type
deploy_instance_type_param = ParameterString(
name="DeployInstanceType",
default_value=predictor_instance_type,
)
# Set deployment instance count
deploy_instance_count_param = ParameterInteger(
name="DeployInstanceCount",
default_value=predictor_instance_count
)
# Set Clarify check instance type
clarify_instance_type_param = ParameterString(
name="ClarifyInstanceType",
default_value=clarify_instance_type,
)
# Set model bias check params
skip_check_model_bias_param = ParameterBoolean(
name="SkipModelBiasCheck",
default_value=False
)
register_new_baseline_model_bias_param = ParameterBoolean(
name="RegisterNewModelBiasBaseline",
default_value=False
)
supplied_baseline_constraints_model_bias_param = ParameterString(
name="ModelBiasSuppliedBaselineConstraints",
default_value=""
)
# Set model explainability check params
skip_check_model_explainability_param = ParameterBoolean(
name="SkipModelExplainabilityCheck",
default_value=False
)
register_new_baseline_model_explainability_param = ParameterBoolean(
name="RegisterNewModelExplainabilityBaseline",
default_value=False
)
supplied_baseline_constraints_model_explainability_param = ParameterString(
name="ModelExplainabilitySuppliedBaselineConstraints",
default_value=""
)
# Set model approval param
model_approval_status_param = ParameterString(
name="ModelApprovalStatus", default_value="Approved"
)步驟 3:建置管道元件
管道是一系列步驟,這些步驟可以單獨建置,然後組合在一起形成 ML 工作流程。 下圖顯示了管道的大致步驟。
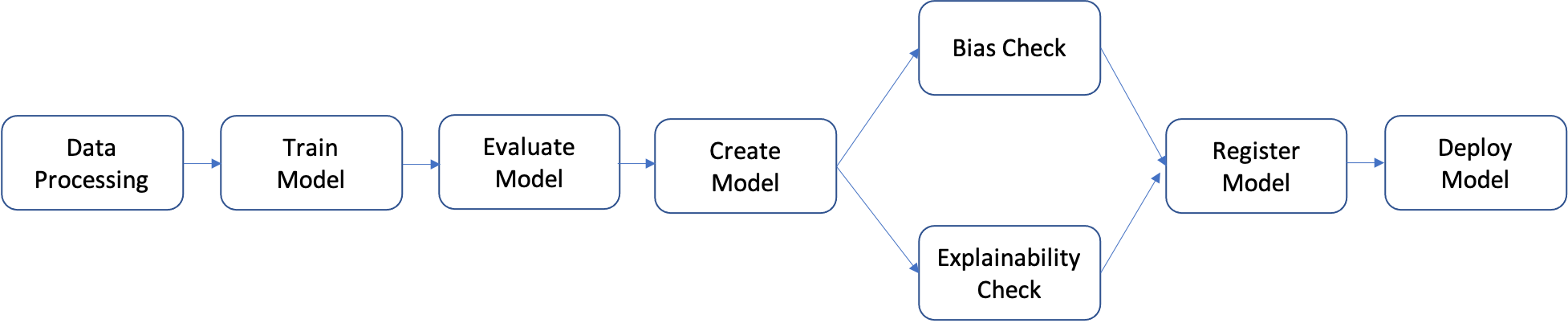
在本教學中,您將透過以下步驟建置管道:
- 資料處理步驟:使用 S3 中的輸入原始資料執行 SageMaker 處理任務,並將訓練、驗證和測試拆分輸出到 S3。
- 訓練步驟:將 S3 中的訓練和驗證資料作為輸入,使用 SageMaker 訓練任務訓練 XGBoost 模型,並將訓練好的模型成品儲存到 S3 中。
- 評估步驟:透過使用 S3 中的測試資料和模型成品作為輸入,執行 SageMaker 處理任務來基於測試資料集評估模型,並將輸出的模型效能評估報告儲存到 S3 中。
- 條件步驟:將模型針對測試資料集的效能與閾值相比較。使用 S3 中的模型效能評估報告作為輸入來執行 SageMaker Pipelines 預定義步驟,並儲存將在模型效能可接受時執行的管道步驟的輸出清單。
- 建立模型步驟:使用 S3 中的模型成品作為輸入執行 SageMaker Pipelines 預定義步驟,並將輸出的 SageMaker 模型儲存到 S3 中。
- 偏差檢查步驟:將 S3 中的訓練資料和模型成品作為輸入,使用 SageMaker Clarify 檢查模型偏差,並將模型偏差報告和基準指標儲存到 S3 中。
- 偏差可解釋性步驟:將 S3 中的訓練資料和模型成品作為輸入,執行 SageMaker Clarify,並將模型可解釋性報告和基準指標儲存到 S3 中。
- 註冊步驟:將模型、偏差和可解釋性基準指標作為輸入,執行 SageMaker Pipelines 預定義步驟,以在 SageMaker 模型登錄檔中註冊模型。
- 部署步驟:將 AWS Lambda 處理常式函數、模型和端點組態作為輸入,執行 SageMaker Pipelines 預定義步驟,從而將模型部署到 SageMaker 即時推論端點。
SageMaker Pipelines 提供很多預定義的步驟類型,例如資料處理步驟、模型訓練步驟、模型調整步驟以及批次轉換步驟。如需詳細資訊,請參閱《Amazon SageMaker 開發人員指南》中的管道步驟。在接下來的步驟中,您將分別設定和定義每個管道步驟,然後透過將管道步驟與輸入參數結合來定義管道本身。
資料處理步驟:在此步驟中,準備一個 Python 指令碼來擷取原始檔案;進行缺失值插補、特徵工程等處理;並策管用於模型建置的訓練、驗證和測試拆分。複製、貼上並執行以下程式碼,以建置處理指令碼。
%%writefile preprocessing.py
import argparse
import pathlib
import boto3
import os
import pandas as pd
import logging
from sklearn.model_selection import train_test_split
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--train-ratio", type=float, default=0.8)
parser.add_argument("--validation-ratio", type=float, default=0.1)
parser.add_argument("--test-ratio", type=float, default=0.1)
args, _ = parser.parse_known_args()
logger.info("Received arguments {}".format(args))
# Set local path prefix in the processing container
local_dir = "/opt/ml/processing"
input_data_path_claims = os.path.join("/opt/ml/processing/claims", "claims.csv")
input_data_path_customers = os.path.join("/opt/ml/processing/customers", "customers.csv")
logger.info("Reading claims data from {}".format(input_data_path_claims))
df_claims = pd.read_csv(input_data_path_claims)
logger.info("Reading customers data from {}".format(input_data_path_customers))
df_customers = pd.read_csv(input_data_path_customers)
logger.debug("Formatting column names.")
# Format column names
df_claims = df_claims.rename({c : c.lower().strip().replace(' ', '_') for c in df_claims.columns}, axis = 1)
df_customers = df_customers.rename({c : c.lower().strip().replace(' ', '_') for c in df_customers.columns}, axis = 1)
logger.debug("Joining datasets.")
# Join datasets
df_data = df_claims.merge(df_customers, on = 'policy_id', how = 'left')
# Drop selected columns not required for model building
df_data = df_data.drop(['customer_zip'], axis = 1)
# Select Ordinal columns
ordinal_cols = ["police_report_available", "policy_liability", "customer_education"]
# Select categorical columns and filling with na
cat_cols_all = list(df_data.select_dtypes('object').columns)
cat_cols = [c for c in cat_cols_all if c not in ordinal_cols]
df_data[cat_cols] = df_data[cat_cols].fillna('na')
logger.debug("One-hot encoding categorical columns.")
# One-hot encoding categorical columns
df_data = pd.get_dummies(df_data, columns = cat_cols)
logger.debug("Encoding ordinal columns.")
# Ordinal encoding
mapping = {
"Yes": "1",
"No": "0"
}
df_data['police_report_available'] = df_data['police_report_available'].map(mapping)
df_data['police_report_available'] = df_data['police_report_available'].astype(float)
mapping = {
"15/30": "0",
"25/50": "1",
"30/60": "2",
"100/200": "3"
}
df_data['policy_liability'] = df_data['policy_liability'].map(mapping)
df_data['policy_liability'] = df_data['policy_liability'].astype(float)
mapping = {
"Below High School": "0",
"High School": "1",
"Associate": "2",
"Bachelor": "3",
"Advanced Degree": "4"
}
df_data['customer_education'] = df_data['customer_education'].map(mapping)
df_data['customer_education'] = df_data['customer_education'].astype(float)
df_processed = df_data.copy()
df_processed.columns = [c.lower() for c in df_data.columns]
df_processed = df_processed.drop(["policy_id", "customer_gender_unkown"], axis=1)
# Split into train, validation, and test sets
train_ratio = args.train_ratio
val_ratio = args.validation_ratio
test_ratio = args.test_ratio
logger.debug("Splitting data into train, validation, and test sets")
y = df_processed['fraud']
X = df_processed.drop(['fraud'], axis = 1)
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=test_ratio, random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=val_ratio, random_state=42)
train_df = pd.concat([y_train, X_train], axis = 1)
val_df = pd.concat([y_val, X_val], axis = 1)
test_df = pd.concat([y_test, X_test], axis = 1)
dataset_df = pd.concat([y, X], axis = 1)
logger.info("Train data shape after preprocessing: {}".format(train_df.shape))
logger.info("Validation data shape after preprocessing: {}".format(val_df.shape))
logger.info("Test data shape after preprocessing: {}".format(test_df.shape))
# Save processed datasets to the local paths in the processing container.
# SageMaker will upload the contents of these paths to S3 bucket
logger.debug("Writing processed datasets to container local path.")
train_output_path = os.path.join(f"{local_dir}/train", "train.csv")
validation_output_path = os.path.join(f"{local_dir}/val", "validation.csv")
test_output_path = os.path.join(f"{local_dir}/test", "test.csv")
full_processed_output_path = os.path.join(f"{local_dir}/full", "dataset.csv")
logger.info("Saving train data to {}".format(train_output_path))
train_df.to_csv(train_output_path, index=False)
logger.info("Saving validation data to {}".format(validation_output_path))
val_df.to_csv(validation_output_path, index=False)
logger.info("Saving test data to {}".format(test_output_path))
test_df.to_csv(test_output_path, index=False)
logger.info("Saving full processed data to {}".format(full_processed_output_path))
dataset_df.to_csv(full_processed_output_path, index=False)
接下來,複製、貼上並執行以下程式碼區塊,以具現化處理器和 SageMaker Pipelines 步驟來執行處理指令碼。由於處理指令碼是使用 Pandas 編寫的,您將使用 SKLearnProcessor。SageMaker Pipelines ProcessingStep 函數採用以下引數:處理器、原始資料集的輸入 S3 位置,以及儲存已處理資料集的輸出 S3 位置。訓練、驗證和測試拆分比例等其他引數透過 job_arguments 引數提供。
from sagemaker.workflow.pipeline_context import PipelineSession
# Upload processing script to S3
s3_client.upload_file(
Filename="preprocessing.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/preprocessing.py"
)
# Define the SKLearnProcessor configuration
sklearn_processor = SKLearnProcessor(
framework_version="0.23-1",
role=sagemaker_role,
instance_count=1,
instance_type=process_instance_type,
base_job_name=f"{base_job_name_prefix}-processing",
)
# Define pipeline processing step
process_step = ProcessingStep(
name="DataProcessing",
processor=sklearn_processor,
inputs=[
ProcessingInput(source=claims_data_uri, destination="/opt/ml/processing/claims"),
ProcessingInput(source=customers_data_uri, destination="/opt/ml/processing/customers")
],
outputs=[
ProcessingOutput(destination=f"{processing_output_uri}/train_data", output_name="train_data", source="/opt/ml/processing/train"),
ProcessingOutput(destination=f"{processing_output_uri}/validation_data", output_name="validation_data", source="/opt/ml/processing/val"),
ProcessingOutput(destination=f"{processing_output_uri}/test_data", output_name="test_data", source="/opt/ml/processing/test"),
ProcessingOutput(destination=f"{processing_output_uri}/processed_data", output_name="processed_data", source="/opt/ml/processing/full")
],
job_arguments=[
"--train-ratio", "0.8",
"--validation-ratio", "0.1",
"--test-ratio", "0.1"
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/preprocessing.py"
)複製、貼上並執行以下程式碼區塊,以準備訓練指令碼。此指令碼封裝了 XGBoost 二進制分類器的訓練邏輯。模型訓練中使用的超參數將在本教學後面的訓練步驟定義中提供。
%%writefile xgboost_train.py
import argparse
import os
import joblib
import json
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Hyperparameters and algorithm parameters are described here
parser.add_argument("--num_round", type=int, default=100)
parser.add_argument("--max_depth", type=int, default=3)
parser.add_argument("--eta", type=float, default=0.2)
parser.add_argument("--subsample", type=float, default=0.9)
parser.add_argument("--colsample_bytree", type=float, default=0.8)
parser.add_argument("--objective", type=str, default="binary:logistic")
parser.add_argument("--eval_metric", type=str, default="auc")
parser.add_argument("--nfold", type=int, default=3)
parser.add_argument("--early_stopping_rounds", type=int, default=3)
# SageMaker specific arguments. Defaults are set in the environment variables
# Set location of input training data
parser.add_argument("--train_data_dir", type=str, default=os.environ.get("SM_CHANNEL_TRAIN"))
# Set location of input validation data
parser.add_argument("--validation_data_dir", type=str, default=os.environ.get("SM_CHANNEL_VALIDATION"))
# Set location where trained model will be stored. Default set by SageMaker, /opt/ml/model
parser.add_argument("--model_dir", type=str, default=os.environ.get("SM_MODEL_DIR"))
# Set location where model artifacts will be stored. Default set by SageMaker, /opt/ml/output/data
parser.add_argument("--output_data_dir", type=str, default=os.environ.get("SM_OUTPUT_DATA_DIR"))
args = parser.parse_args()
data_train = pd.read_csv(f"{args.train_data_dir}/train.csv")
train = data_train.drop("fraud", axis=1)
label_train = pd.DataFrame(data_train["fraud"])
dtrain = xgb.DMatrix(train, label=label_train)
data_validation = pd.read_csv(f"{args.validation_data_dir}/validation.csv")
validation = data_validation.drop("fraud", axis=1)
label_validation = pd.DataFrame(data_validation["fraud"])
dvalidation = xgb.DMatrix(validation, label=label_validation)
# Choose XGBoost model hyperparameters
params = {"max_depth": args.max_depth,
"eta": args.eta,
"objective": args.objective,
"subsample" : args.subsample,
"colsample_bytree":args.colsample_bytree
}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
# Cross-validate train XGBoost model
cv_results = xgb.cv(
params=params,
dtrain=dtrain,
num_boost_round=num_boost_round,
nfold=nfold,
early_stopping_rounds=early_stopping_rounds,
metrics=["auc"],
seed=42,
)
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
train_pred = model.predict(dtrain)
validation_pred = model.predict(dvalidation)
train_auc = roc_auc_score(label_train, train_pred)
validation_auc = roc_auc_score(label_validation, validation_pred)
print(f"[0]#011train-auc:{train_auc:.2f}")
print(f"[0]#011validation-auc:{validation_auc:.2f}")
metrics_data = {"hyperparameters" : params,
"binary_classification_metrics": {"validation:auc": {"value": validation_auc},
"train:auc": {"value": train_auc}
}
}
# Save the evaluation metrics to the location specified by output_data_dir
metrics_location = args.output_data_dir + "/metrics.json"
# Save the trained model to the location specified by model_dir
model_location = args.model_dir + "/xgboost-model"
with open(metrics_location, "w") as f:
json.dump(metrics_data, f)
with open(model_location, "wb") as f:
joblib.dump(model, f)使用 SageMaker XGBoost 估算器和 SageMaker Pipelines TrainingStep 函數設定模型訓練。
# Set XGBoost model hyperparameters
hyperparams = {
"eval_metric" : "auc",
"objective": "binary:logistic",
"num_round": "5",
"max_depth":"5",
"subsample":"0.75",
"colsample_bytree":"0.75",
"eta":"0.5"
}
# Set XGBoost estimator
xgb_estimator = XGBoost(
entry_point="xgboost_train.py",
output_path=estimator_output_uri,
code_location=estimator_output_uri,
hyperparameters=hyperparams,
role=sagemaker_role,
# Fetch instance type and count from pipeline parameters
instance_count=train_instance_count,
instance_type=train_instance_type,
framework_version="1.3-1"
)
# Access the location where the preceding processing step saved train and validation datasets
# Pipeline step properties can give access to outputs which can be used in succeeding steps
s3_input_train = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
s3_input_validation = TrainingInput(
s3_data=process_step.properties.ProcessingOutputConfig.Outputs["validation_data"].S3Output.S3Uri,
content_type="csv",
s3_data_type="S3Prefix"
)
# Set pipeline training step
train_step = TrainingStep(
name="XGBModelTraining",
estimator=xgb_estimator,
inputs={
"train":s3_input_train, # Train channel
"validation": s3_input_validation # Validation channel
}
)複製、貼上並執行以下程式碼區塊,以使用 SageMaker Pipelines CreateModelStep 函數建立 SageMaker 模型。此步驟利用訓練步驟的輸出來打包模型以用於部署。 請注意,執行個體類型引數的值透過您在本教學稍前定義的 SageMaker Pipelines 引數傳遞。
# Create a SageMaker model
model = sagemaker.model.Model(
image_uri=training_image,
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
sagemaker_session=sess,
role=sagemaker_role
)
# Specify model deployment instance type
inputs = sagemaker.inputs.CreateModelInput(instance_type=deploy_instance_type_param)
create_model_step = CreateModelStep(name="FraudDetModel", model=model, inputs=inputs)在 ML 工作流程中,重要的是評估經訓練模型的潛在偏差,並了解輸入資料中的各種特徵如何影響模型預測。SageMaker Pipelines 提供 ClarifyCheckStep 函數,該函數可用於執行三種類型的檢查:資料偏差檢查 (訓練前)、模型偏差檢查 (訓練後) 和模型可解釋性檢查。為了減少執行時間,在本教學中,您將只實作偏差和可解釋性檢查。複製、貼上並執行以下程式碼區塊,以設定 SageMaker Clarify 進行模型偏差檢查。請注意,此步驟透過 properties (屬性) 屬性取得資產,例如訓練資料和上一步中建立的 SageMaker 模型。管道被執行時,這個步驟直到提供輸入的步驟執行完畢才會開始執行。如需詳細資訊,請參閱《Amazon SageMaker 開發人員指南》中的步驟之間的資料相依性。為了管理成本和教學執行時間,將 ModelBiasCheckConfig 函數設定為僅計算一個偏差指標,即 DPPL。如需有關 SageMaker Clarify 中提供的偏差指標的更多資訊,請參閱《Amazon SageMaker 開發人員指南》中的衡量訓練後資料和模型偏差。
# Set up common configuration parameters to be used across multiple steps
check_job_config = CheckJobConfig(
role=sagemaker_role,
instance_count=1,
instance_type=clarify_instance_type,
volume_size_in_gb=30,
sagemaker_session=sess,
)
# Set up configuration of data to be used for model bias check
model_bias_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=bias_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_bias_config_output_uri
)
# Set up details of the trained model to be checked for bias
model_config = sagemaker.clarify.ModelConfig(
# Pull model name from model creation step
model_name=create_model_step.properties.ModelName,
instance_count=train_instance_count,
instance_type=train_instance_type
)
# Set up column and categories that are to be checked for bias
model_bias_config = sagemaker.clarify.BiasConfig(
label_values_or_threshold=[0],
facet_name="customer_gender_female",
facet_values_or_threshold=[1]
)
# Set up model predictions configuration to get binary labels from probabilities
model_predictions_config = sagemaker.clarify.ModelPredictedLabelConfig(probability_threshold=0.5)
model_bias_check_config = ModelBiasCheckConfig(
data_config=model_bias_data_config,
data_bias_config=model_bias_config,
model_config=model_config,
model_predicted_label_config=model_predictions_config,
methods=["DPPL"]
)
# Set up pipeline model bias check step
model_bias_check_step = ClarifyCheckStep(
name="ModelBiasCheck",
clarify_check_config=model_bias_check_config,
check_job_config=check_job_config,
skip_check=skip_check_model_bias_param,
register_new_baseline=register_new_baseline_model_bias_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_bias_param
)複製、貼上並執行以下程式碼區塊,以設定模型可解釋性檢查。此步驟提供特徵重要性之類的洞見 (輸入特徵對模型預測的影響程度)。
# Set configuration of data to be used for model explainability check
model_explainability_data_config = sagemaker.clarify.DataConfig(
# Fetch S3 location where processing step saved train data
s3_data_input_path=process_step.properties.ProcessingOutputConfig.Outputs["train_data"].S3Output.S3Uri,
s3_output_path=explainability_report_output_uri,
label=target_col,
dataset_type="text/csv",
s3_analysis_config_output_path=clarify_explainability_config_output_uri
)
# Set SHAP configuration for Clarify to compute global and local SHAP values for feature importance
shap_config = sagemaker.clarify.SHAPConfig(
seed=42,
num_samples=100,
agg_method="mean_abs",
save_local_shap_values=True
)
model_explainability_config = ModelExplainabilityCheckConfig(
data_config=model_explainability_data_config,
model_config=model_config,
explainability_config=shap_config
)
# Set pipeline model explainability check step
model_explainability_step = ClarifyCheckStep(
name="ModelExplainabilityCheck",
clarify_check_config=model_explainability_config,
check_job_config=check_job_config,
skip_check=skip_check_model_explainability_param,
register_new_baseline=register_new_baseline_model_explainability_param,
supplied_baseline_constraints=supplied_baseline_constraints_model_explainability_param
)在生產系統中,並非所有經過訓練的模型都會被部署。通常只部署效能優於所選評估指標閾值的模型。在此步驟中,您將建置 Python 指令碼,以使用接收者操作特徵曲線下面積 (ROC-AUC) 指標針對測試集對模型進行評分。在隨後的步驟中,將根據此指標評估模型的效能,以確定是否應該註冊和部署模型。複製、貼上並執行以下程式碼,以建置評估指令碼來擷取測試資料集並產生 AUC 指標。
%%writefile evaluate.py
import json
import logging
import pathlib
import pickle
import tarfile
import numpy as np
import pandas as pd
import xgboost as xgb
from sklearn.metrics import roc_auc_score
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler())
if __name__ == "__main__":
model_path = "/opt/ml/processing/model/model.tar.gz"
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
logger.debug("Loading xgboost model.")
# The name of the file should match how the model was saved in the training script
model = pickle.load(open("xgboost-model", "rb"))
logger.debug("Reading test data.")
test_local_path = "/opt/ml/processing/test/test.csv"
df_test = pd.read_csv(test_local_path)
# Extract test set target column
y_test = df_test.iloc[:, 0].values
cols_when_train = model.feature_names
# Extract test set feature columns
X = df_test[cols_when_train].copy()
X_test = xgb.DMatrix(X)
logger.info("Generating predictions for test data.")
pred = model.predict(X_test)
# Calculate model evaluation score
logger.debug("Calculating ROC-AUC score.")
auc = roc_auc_score(y_test, pred)
metric_dict = {
"classification_metrics": {"roc_auc": {"value": auc}}
}
# Save model evaluation metrics
output_dir = "/opt/ml/processing/evaluation"
pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True)
logger.info("Writing evaluation report with ROC-AUC: %f", auc)
evaluation_path = f"{output_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(metric_dict))接下來,複製、貼上並執行以下程式碼區塊,以具現化處理器和 SageMaker Pipelines 步驟來執行評估指令碼。若要處理該自訂指令碼,您可以使用 ScriptProcessor。SageMaker Pipelines ProcessingStep 函數採用以下引數:處理器、測試資料集的 S3 輸入位置、模型成品和儲存評估結果的輸出位置。此外,還提供引數 property_files。您可以使用屬性檔案儲存來自處理步驟輸出的資訊,在本例中,該輸出是一個包含模型效能指標的 json 檔案。這對於確定什麼時候應該執行條件步驟特別有用,這一點會在本教學的稍後部分有所涉獵。
# Upload model evaluation script to S3
s3_client.upload_file(
Filename="evaluate.py", Bucket=write_bucket, Key=f"{write_prefix}/scripts/evaluate.py"
)
eval_processor = ScriptProcessor(
image_uri=training_image,
command=["python3"],
instance_type=predictor_instance_type,
instance_count=predictor_instance_count,
base_job_name=f"{base_job_name_prefix}-model-eval",
sagemaker_session=sess,
role=sagemaker_role,
)
evaluation_report = PropertyFile(
name="FraudDetEvaluationReport",
output_name="evaluation",
path="evaluation.json",
)
# Set model evaluation step
evaluation_step = ProcessingStep(
name="XGBModelEvaluate",
processor=eval_processor,
inputs=[
ProcessingInput(
# Fetch S3 location where train step saved model artifacts
source=train_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/model",
),
ProcessingInput(
# Fetch S3 location where processing step saved test data
source=process_step.properties.ProcessingOutputConfig.Outputs["test_data"].S3Output.S3Uri,
destination="/opt/ml/processing/test",
),
],
outputs=[
ProcessingOutput(destination=f"{model_eval_output_uri}", output_name="evaluation", source="/opt/ml/processing/evaluation"),
],
code=f"s3://{write_bucket}/{write_prefix}/scripts/evaluate.py",
property_files=[evaluation_report],
)藉助 SageMaker 模型登錄檔,您可以對模型進行編目、管理模型版本,以及選擇性地將模型部署到生產環境中。複製、貼上並執行以下程式碼區塊,以設定模型登錄檔步驟。model_metrics 和 drift_check_baselines 這兩個參數包含在教學稍前部分由 ClarifyCheckStep 函數計算得到的基準指標。您還可以提供自己的自訂基準指標。這些參數的目的是提供一種設定與模型相關聯基準的方法,以便在漂移檢查和模型監控任務中使用。每次執行管道時,您都可以選擇使用新計算的基準來更新這些參數。
# Fetch baseline constraints to record in model registry
model_metrics = ModelMetrics(
bias_post_training=MetricsSource(
s3_uri=model_bias_check_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
explainability=MetricsSource(
s3_uri=model_explainability_step.properties.CalculatedBaselineConstraints,
content_type="application/json"
),
)
# Fetch baselines to record in model registry for drift check
drift_check_baselines = DriftCheckBaselines(
bias_post_training_constraints=MetricsSource(
s3_uri=model_bias_check_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_constraints=MetricsSource(
s3_uri=model_explainability_step.properties.BaselineUsedForDriftCheckConstraints,
content_type="application/json",
),
explainability_config_file=FileSource(
s3_uri=model_explainability_config.monitoring_analysis_config_uri,
content_type="application/json",
),
)
# Define register model step
register_step = RegisterModel(
name="XGBRegisterModel",
estimator=xgb_estimator,
# Fetching S3 location where train step saved model artifacts
model_data=train_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["text/csv"],
response_types=["text/csv"],
inference_instances=[predictor_instance_type],
transform_instances=[predictor_instance_type],
model_package_group_name=model_package_group_name,
approval_status=model_approval_status_param,
# Registering baselines metrics that can be used for model monitoring
model_metrics=model_metrics,
drift_check_baselines=drift_check_baselines
)使用 Amazon SageMaker 時,您可以透過幾種方式部署已註冊的模型進行推論。在此步驟中,您將使用 LambdaStep 函數部署模型。雖然您通常應該使用 SageMaker 專案部署遵循 CI/CD 最佳實務的可靠模型,但在某些情況下,使用 LambdaStep 在服務於低流量的開發、測試和內部端點部署輕量級模型是有意義的。LambdaStep 函數提供與 AWS Lambda 的原生整合,因此您可以在管道中實現自訂邏輯,而無需佈建或管理伺服器。在 SageMaker Pipelines 的內容中,LambdaStep 允許您向管道新增 AWS Lambda 函數,以支援任意運算操作,特別是持續時間較短的輕量級操作。請記住,在 SageMaker Pipelines LambdaStep 中,Lambda 函數的最大執行時間限制為 10 分鐘,可修改的逾時預設為 2 分鐘。
您有兩種方式可將 LambdaStep 新增到管道中。首先,您可以提供使用 AWS Cloud Development Kit (AWS CDK)、AWS 管理主控台或其他方式建立的現有 Lambda 函數的 ARN。其次,高級的 SageMaker Python 開發套件具有一個 Lambda 助手便利類別,您可以使用它與定義管道的其他程式碼建立一個新的 Lambda 函數。在本教學中,您將使用第二種方法。 複製、貼上並執行以下程式碼,以定義 Lambda 處理常式函數。這是一個自訂 Python 指令碼,它包含模型屬性 (比如模型名稱),並部署到即時端點。
%%writefile lambda_deployer.py
"""
Lambda function creates an endpoint configuration and deploys a model to real-time endpoint.
Required parameters for deployment are retrieved from the event object
"""
import json
import boto3
def lambda_handler(event, context):
sm_client = boto3.client("sagemaker")
# Details of the model created in the Pipeline CreateModelStep
model_name = event["model_name"]
model_package_arn = event["model_package_arn"]
endpoint_config_name = event["endpoint_config_name"]
endpoint_name = event["endpoint_name"]
role = event["role"]
instance_type = event["instance_type"]
instance_count = event["instance_count"]
primary_container = {"ModelPackageName": model_package_arn}
# Create model
model = sm_client.create_model(
ModelName=model_name,
PrimaryContainer=primary_container,
ExecutionRoleArn=role
)
# Create endpoint configuration
create_endpoint_config_response = sm_client.create_endpoint_config(
EndpointConfigName=endpoint_config_name,
ProductionVariants=[
{
"VariantName": "Alltraffic",
"ModelName": model_name,
"InitialInstanceCount": instance_count,
"InstanceType": instance_type,
"InitialVariantWeight": 1
}
]
)
# Create endpoint
create_endpoint_response = sm_client.create_endpoint(
EndpointName=endpoint_name,
EndpointConfigName=endpoint_config_name
)複製、貼上並執行以下程式碼區塊,以建立 LambdaStep。模型、端點名稱和部署執行個體類型和數量等所有引數都使用 inputs 引數提供。
# The function name must contain sagemaker
function_name = "sagemaker-fraud-det-demo-lambda-step"
# Define Lambda helper class can be used to create the Lambda function required in the Lambda step
func = Lambda(
function_name=function_name,
execution_role_arn=sagemaker_role,
script="lambda_deployer.py",
handler="lambda_deployer.lambda_handler",
timeout=600,
memory_size=10240,
)
# The inputs used in the lambda handler are passed through the inputs argument in the
# LambdaStep and retrieved via the `event` object within the `lambda_handler` function
lambda_deploy_step = LambdaStep(
name="LambdaStepRealTimeDeploy",
lambda_func=func,
inputs={
"model_name": pipeline_model_name,
"endpoint_config_name": endpoint_config_name,
"endpoint_name": endpoint_name,
"model_package_arn": register_step.steps[0].properties.ModelPackageArn,
"role": sagemaker_role,
"instance_type": deploy_instance_type_param,
"instance_count": deploy_instance_count_param
}
)在此步驟中,您使用 ConditionStep 根據曲線下面積 (AUC) 指標來評估當前模型的效能。只有當效能大於或等於閾值 AUC (這裏的選擇為 0.7) 時,管道才會執行偏差和可解釋性檢查,註冊模型,並部署它。像這樣的條件步驟有助於選擇最佳模型,並將其部署到生產環境中。複製、貼上並執行以下程式碼以定義條件步驟。
# Evaluate model performance on test set
cond_gte = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step_name=evaluation_step.name,
property_file=evaluation_report,
json_path="classification_metrics.roc_auc.value",
),
right=0.7, # Threshold to compare model performance against
)
condition_step = ConditionStep(
name="CheckFraudDetXGBEvaluation",
conditions=[cond_gte],
if_steps=[create_model_step, model_bias_check_step, model_explainability_step, register_step, lambda_deploy_step],
else_steps=[]
)步驟 4:建置並執行管道
定義所有的元件步驟後,您可以將它們組合到一個 SageMaker Pipelines 物件中。您不需要指定執行順序,因為 SageMaker Pipelines 會根據步驟之間的相依性自動推斷執行順序。
複製、貼上並執行以下程式碼區塊以設定管道。管道定義採用您在步驟 2 中定義的所有參數和元件步驟清單。建立模型、偏差和可解釋性檢查、模型註冊和 lambda 部署等步驟沒有在管道定義中列出,因為它們不會執行,除非條件步驟的評估結果為 true。如果條件步驟為 true,則後續步驟將根據指定的輸入和輸出按順序執行。
# Create the Pipeline with all component steps and parameters
pipeline = Pipeline(
name=pipeline_name,
parameters=[process_instance_type_param,
train_instance_type_param,
train_instance_count_param,
deploy_instance_type_param,
deploy_instance_count_param,
clarify_instance_type_param,
skip_check_model_bias_param,
register_new_baseline_model_bias_param,
supplied_baseline_constraints_model_bias_param,
skip_check_model_explainability_param,
register_new_baseline_model_explainability_param,
supplied_baseline_constraints_model_explainability_param,
model_approval_status_param],
steps=[
process_step,
train_step,
evaluation_step,
condition_step
],
sagemaker_session=sess
)在筆記本的儲存格中複製、貼上並執行以下程式碼。如果管道已存在,則程式碼將更新管道。如果管道不存在,則將建立一個新管道。忽略任何 SageMaker 開發套件警告,如 "No finished training job found associated with this estimator.Please make sure this estimator is only used for building workflow config." (未找到與此估算器關聯的已完成訓練任務。請確認此估算器僅用於建置工作流程設定。)
# Create a new or update existing Pipeline
pipeline.upsert(role_arn=sagemaker_role)
# Full Pipeline description
pipeline_definition = json.loads(pipeline.describe()['PipelineDefinition'])
pipeline_definitionSageMaker 將用有向非循環圖 (DAG) 編碼管道,其中每個節點都表示一個步驟,且節點之間的連線表示相依性。若要從 SageMaker Studio 介面檢查管道 DAG,請在左側面板上選取 SageMaker Resources (SageMaker 資源) 標籤,從下拉式清單中選取 Pipelines (管道),然後選取 FraudDetectXGBPipeline、Graph (圖表)。可以看到,您建立的管道步驟由圖中的節點表示,節點之間的連線由 SageMaker 根據步驟定義中提供的輸入和輸出推斷。

執行以下程式碼陳述式來執行管道。在此步驟中,管道執行參數作為引數提供。轉至左側面板上的 SageMaker Resources (SageMaker 資源) 標籤,從下拉式清單中選取 Pipelines (管道),然後選取 FraudDetectXGBPipeline、Executions (執行)。管道的當前執行被列出。
# Execute Pipeline
start_response = pipeline.start(parameters=dict(
SkipModelBiasCheck=True,
RegisterNewModelBiasBaseline=True,
SkipModelExplainabilityCheck=True,
RegisterNewModelExplainabilityBaseline=True)
)
若要檢視管道執行,選擇 Status (狀態) 標籤。在所有步驟成功執行後,圖表中的節點會變為綠色。

在 SageMaker Studio 介面中,選取左側面板中的 SageMaker Resources (SageMaker 資源),然後從下拉式清單中選取 Model registry (模型登錄檔)。註冊的模型會列在左側面板的 Model group name (模型群組名稱) 下。選取模型群組名稱以顯示模型版本的清單。每次執行管道時,如果模型版本滿足評估的條件閾值,新模型版本便會新增到註冊表中。選擇一個模型版本以查看詳細資訊,例如模型端點和模型可解釋性報告。

步驟 5:透過叫用端點來測試管道
在此教學中,該模型的得分高於所選擇的 0.7 AUC 的閾值。因此,條件步驟會註冊模型並將其部署到即時推論端點中。
在 SageMaker Studio 介面上,選取左側窗格中的 SageMaker Resources (SageMaker 資源) 標籤,再選取 Endpoints (端點),並等到 fraud-detect-xgb-pipeline-endpoint 的狀態變為 InService (服務中)。

當 Endpoint status (端點狀態) 變為 InService (服務中) 後,複製、貼上並執行以下程式碼,以叫用端點並執行樣本推論。程式碼將返回測試資料集中前五個樣本的模型預測。
# Fetch test data to run predictions with the endpoint
test_df = pd.read_csv(f"{processing_output_uri}/test_data/test.csv")
# Create SageMaker Predictor from the deployed endpoint
predictor = sagemaker.predictor.Predictor(endpoint_name,
sagemaker_session=sess,
serializer=CSVSerializer(),
deserializer=CSVDeserializer()
)
# Test endpoint with payload of 5 samples
payload = test_df.drop(["fraud"], axis=1).iloc[:5]
result = predictor.predict(payload.values)
prediction_df = pd.DataFrame()
prediction_df["Prediction"] = result
prediction_df["Label"] = test_df["fraud"].iloc[:5].values
prediction_df步驟 6:清除資源
最佳實務是刪除不再使用的資源,以免產生意外費用。
複製並貼上以下程式碼區塊,以刪除您在本教學中建立的 Lambda 函數、模型、端點組態、端點和管道。
# Delete the Lambda function
func.delete()
# Delete the endpoint
sm_client.delete_endpoint(EndpointName=endpoint_name)
# Delete the EndpointConfig
sm_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
# Delete the model
sm_client.delete_model(ModelName=pipeline_model_name)
# Delete the pipeline
sm_client.delete_pipeline(PipelineName=pipeline_name)若要刪除 S3 儲存貯體,請執行以下操作:
- 開啟 Amazon S3 主控台。在導覽列上,選擇 Buckets (儲存貯體)、sagemaker-<您的區域>-<您的帳戶 ID>,然後選取 fraud-detect-demo 旁邊的核取方塊。然後選擇 Delete (刪除)。
- 在 Delete objects (刪除物件) 對話方塊中,確認您已選取要刪除的物件,然後將 permanently delete (永久刪除) 輸入到 Permanently delete objects (永久刪除物件) 確認方塊。
- 當此操作完成且儲存貯體為空時,您可以透過再次執行相同程序來刪除儲存貯體 sagemaker-<您的區域>-<您的帳戶 ID>。

本教學中用於執行筆記本映像的資料科學核心將不斷產生費用,直到您停止核心或執行以下步驟刪除應用程式。 如需詳細資訊,請參閱《Amazon SageMaker 開發人員指南》中的關閉資源。
若要刪除 SageMaker Studio 應用程式,請執行以下操作:在 SageMaker Studio 主控台中,選擇 studio-user,然後透過選擇 Delete app (刪除應用程式程式) 來刪除 Apps (應用程式) 下列出的所有應用程式。等待片刻直到 Status (狀態) 變更為 Deleted (已刪除)。

如果您在步驟 1 中使用了現有的 SageMaker Studio 網域,請略過步驟 6 的其餘部分並直接進入「結論」部分。
如果您在步驟 1 中執行 CloudFormation 範本來建立新的 SageMaker Studio 網域,請繼續執行下列步驟以刪除由 CloudFormation 範本建立的網域、使用者和資源。
若要開啟 CloudFormation 主控台,請在 AWS Console 搜尋列中輸入 CloudFormation,然後從搜尋結果中選擇 CloudFormation。

在 CloudFormation 窗格中,選擇 Stacks (堆疊)。從狀態下拉式清單中,選取 Active (作用中)。在 Stack name (堆疊名稱) 下,選擇 CFN-SM-IM-Lambda-catalog 開啟堆疊詳細資訊頁面。

在 CFN-SM-IM-Lambda-catalog 堆疊詳細資訊頁面上,選擇 Delete (刪除) 以刪除在步驟 1 中建立的堆疊及資源。

結論
恭喜您! 您已完成自動化機器學習工作流程教學。
您成功地使用 Amazon SageMaker Pipelines 自動化了從資料處理、模型訓練、模型評估、偏差和可解釋性檢查到條件模型註冊和部署的端對端 ML 工作流程。最後,您使用 SageMaker 開發套件將模型部署到了即時推論端點,並使用樣本承載對其進行了測試。
您可以按照下面的「後續步驟」部分繼續使用 Amazon SageMaker 進行機器學習之旅。