¿Qué le pareció este contenido?
Creación de aplicaciones de IA generativa para su startup
Los recientes avances de la IA generativa suben el nivel de las herramientas que pueden ayudar a las startups a construir, escalar e innovar de forma rápida. Esta adopción y democratización generalizadas del machine learning (ML), en especial con la arquitectura de redes neuronales transformadoras, es un punto de inflexión emocionante en la tecnología. Con las herramientas adecuadas, las startups pueden crear nuevas ideas o dar un giro a sus productos existentes para aprovechar las ventajas de la IA generativa para sus clientes.
¿Está listo para crear una aplicación de IA generativa para su startup? Primero, repasemos los conceptos, las ideas principales y los enfoques comunes para crear aplicaciones de IA generativa.
¿Qué son las aplicaciones de IA generativa?
Las aplicaciones de IA generativa son programas que se basan en un tipo de IA que pueden crear nuevos contenidos e ideas, como conversaciones, historias, imágenes, videos, código y música. Al igual que todas las aplicaciones de IA, las aplicaciones de IA generativa funcionan con modelos de ML que se entrenan con anterioridad con grandes cantidades de datos y, por lo general, se denominan modelos fundacionales (FM).
Un ejemplo de aplicación de IA generativa es Amazon CodeWhisperer, un complemento de programación de IA que ayuda a los desarrolladores a crear aplicaciones de forma más rápida y segura al proporcionar sugerencias de código de líneas completas y funciones completas en su entorno de desarrollo integrado (IDE). CodeWhisperer se entrenó con miles de millones de líneas de código y puede generar sugerencias de código que van desde fragmentos hasta funciones completas al instante, basándose en sus comentarios y en el código existente. Las startups pueden utilizar los créditos de AWS Activate con el nivel profesional de CodeWhisperer o empezar con el nivel individual, que es de uso gratuito.
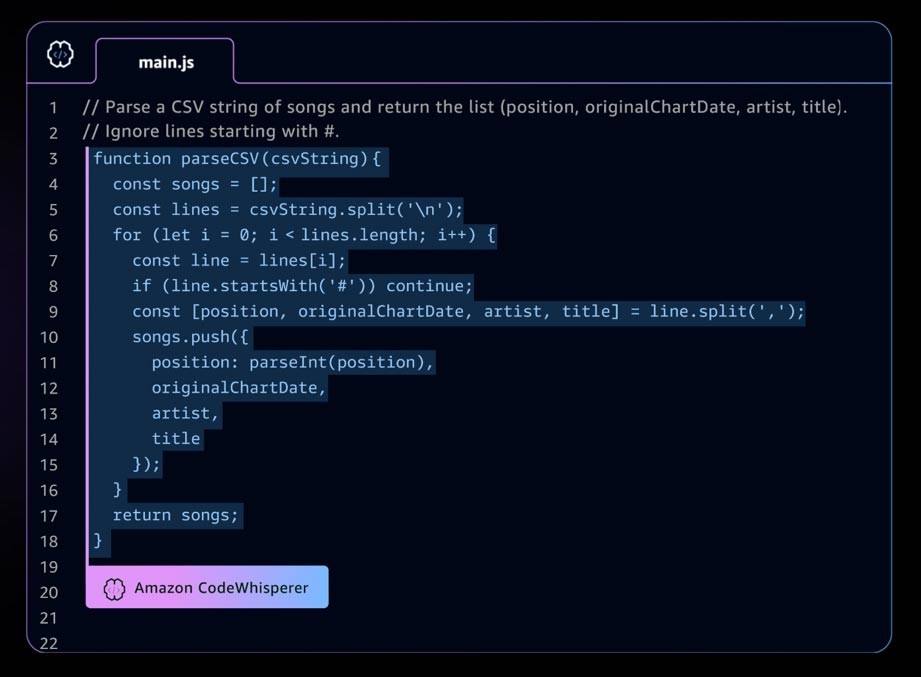
El panorama de desarrollo acelerado de la IA generativa
Se produce un crecimiento acelerado en las startups de IA generativa y también en las startups que crean herramientas para simplificar la adopción de la IA generativa. Herramientas como LangChain, un marco de código abierto para desarrollar aplicaciones basadas en modelos del lenguaje, hacen que la IA generativa sea más accesible para una gama más amplia de organizaciones, lo que permitirá una adopción más rápida. Estas herramientas también incluyen la ingeniería de las indicaciones, la ampliación de los servicios (como la integración de herramientas o bases de datos vectoriales), la supervisión de modelos, la medición de la calidad de los modelos, las barreras de protección, la anotación de datos, el aprendizaje reforzado a partir de la retroalimentación humana (RLHF) y muchas más.
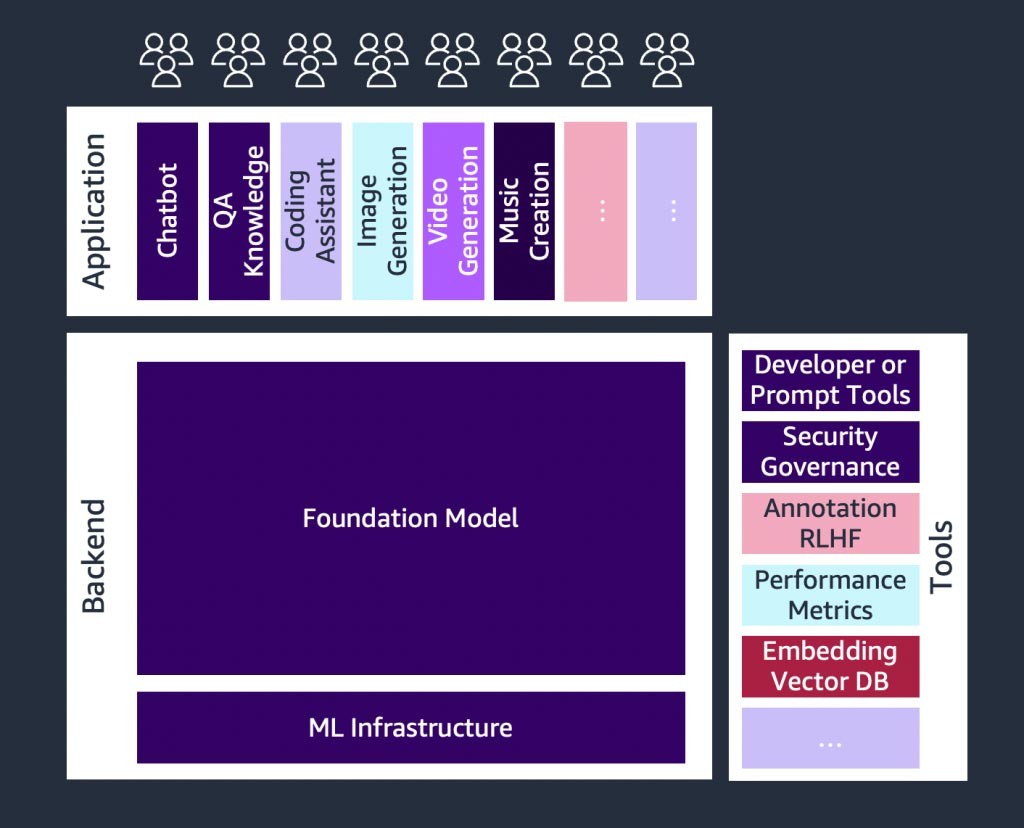
Introducción a los modelos fundacionales
En el caso de una aplicación o herramienta de IA generativa, el núcleo es el modelo fundacional. Los modelos fundacionales son una clase de modelos potentes de machine learning que se diferencian por su capacidad para entrenarse con anterioridad con grandes cantidades de datos para realizar una amplia gama de tareas posteriores. Estas tareas incluyen la generación de texto, el resumen, la extracción de información, las preguntas y respuestas y los chatbots. Por el contrario, los modelos de ML tradicionales están entrenados para realizar una tarea específica a partir de un conjunto de datos.
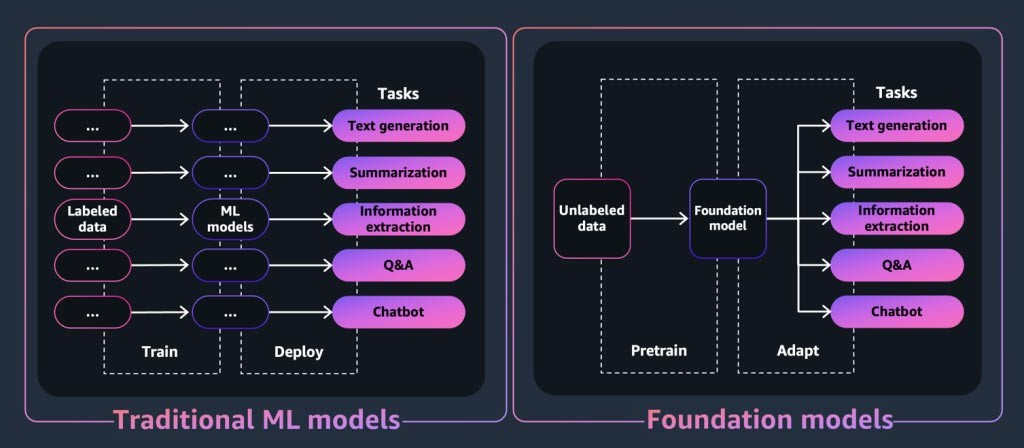
Entonces, ¿cómo un modelo fundacional “genera” los resultados por los que son conocidas las aplicaciones de IA generativa? Estas capacidades son el resultado de patrones y relaciones de aprendizaje que permiten al FM predecir el siguiente elemento o elementos de una secuencia o generar uno nuevo:
- En los modelos generadores de texto, los FM generan la siguiente palabra, la siguiente frase o la respuesta a una pregunta.
- Para los modelos de generación de imágenes, los FM generan una imagen basada en el texto.
- Cuando se utiliza una imagen como entrada, los FM generan la imagen o animación relevante o mejorada o la imagen 3D siguiente.
En cada caso, el modelo comienza con un vector semilla derivado de una “indicación”: las indicaciones describen la tarea que debe realizar el modelo. La calidad y el detalle (también conocidos como “contexto”) de la indicación determinan la calidad y la relevancia del resultado.
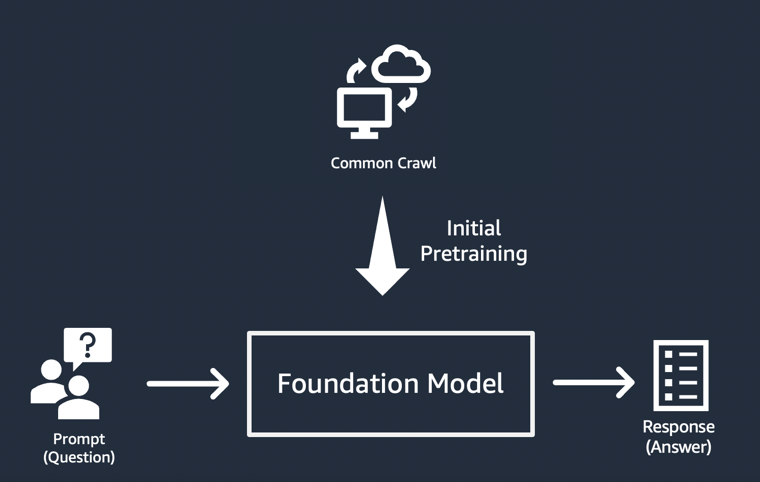
La implementación más sencilla de aplicaciones de IA generativa
El enfoque más simple para crear una aplicación de IA generativa consiste en utilizar un modelo fundacional ajustado a las instrucciones y proporcionar una indicación significativa (“ingeniería de las indicaciones”) mediante el aprendizaje desde cero o de pocos pasos. Un modelo ajustado a las instrucciones (como el FLAN T5 XXL, el Open-Llama o el Falcon 40B Instruct) utiliza su conocimiento de tareas o conceptos relacionados para generar predicciones a partir de las indicaciones. Estos son algunos ejemplos de indicaciones:
Aprendizaje desde cero
Título: \”La universidad tendrá un nuevo edificio próximamente“\\n Dado el título anterior de un artículo imaginario, imagine el artículo.\n
Aprendizaje de pocos pasos
¡Esto es impresionante! // Positivo
¡Esto es malo! // Negativo
¡Esa película es un caso perdido! // Negativo
¡Qué espectáculo horrible! //
RESPUESTA: Negativa
Las startups, en particular, pueden beneficiarse del despliegue rápido, las necesidades mínimas de datos y la optimización de los costos que resultan del uso de un modelo ajustado a las instrucciones.
Para obtener más información sobre las consideraciones a la hora de elegir un modelo fundacional consulte Selecting the right foundation model for your startup.
Personalización de modelos fundacionales
No todos los casos de uso pueden satisfacerse mediante la ingeniería de las indicaciones en los modelos ajustados para las instrucciones. Los motivos para personalizar un modelo fundacional para su startup pueden incluir:
- Agregar una tarea específica (como la generación de código) al modelo fundacional
- Generar respuestas basadas en el conjunto de datos propio de su empresa
- Buscar respuestas generadas a partir de conjuntos de datos de mayor calidad que los que entrenaron el modelo con anterioridad
- Reducir la “alucinación”, que es un resultado incorrecto o poco razonable desde el punto de vista fáctico
Existen tres técnicas comunes para personalizar un modelo fundacional.
Ajuste preciso basado en las instrucciones
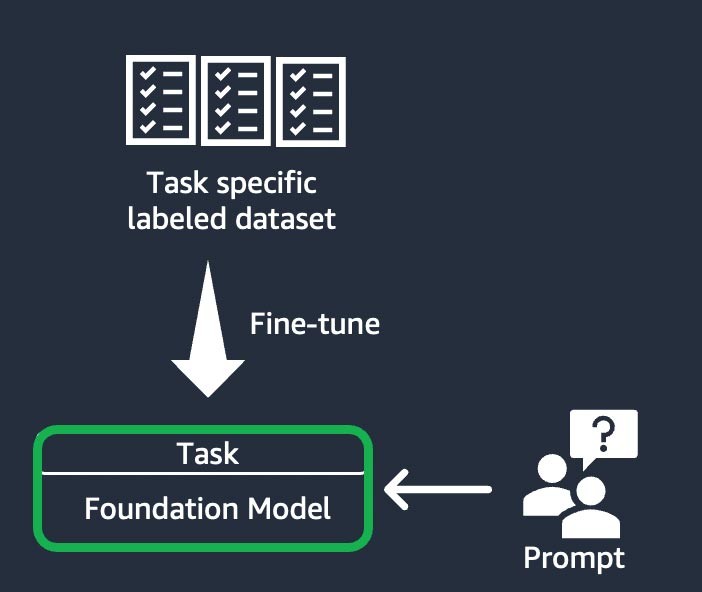
Esta técnica implica entrenar el modelo fundacional para completar una tarea específica, en función de un conjunto de datos etiquetado para tal fin. Un conjunto de datos etiquetados consta de pares de indicaciones y respuestas. Esta técnica de personalización es beneficiosa para las startups que desean personalizar su FM de forma rápida y con un conjunto mínimo de datos: el entrenamiento requiere menos pasos y conjuntos de datos. Los pesos del modelo se actualizan en función de la tarea o el nivel que ajuste.
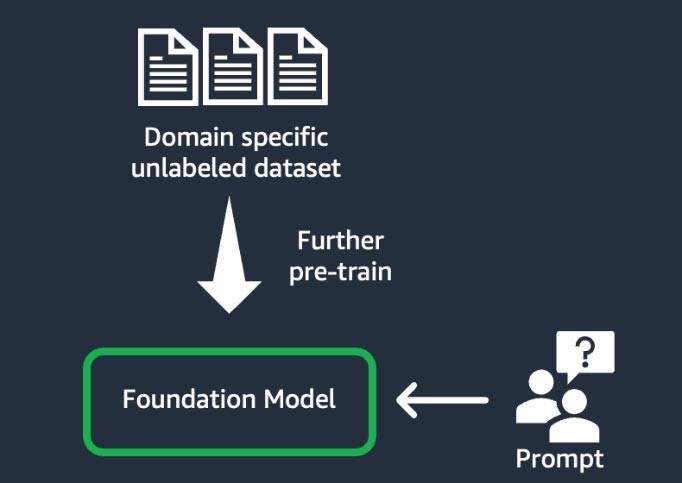
Adaptación del dominio (también conocida como “entrenamiento previo adicional”)
Esta técnica implica entrenar el modelo fundacional mediante un gran “corpus”, un conjunto de materiales de entrenamiento, de datos no etiquetados de dominios específicos (lo que se conoce como “aprendizaje autosupervisado”). Esta técnica beneficia a los casos de uso que incluyen jerga específica de un dominio y datos estadísticos que el modelo fundacional existente no había visto antes. Por ejemplo, las startups que crean una aplicación de IA generativa para trabajar con datos propios en el ámbito financiero podrían beneficiarse de entrenar con anterioridad el FM en vocabulario personalizado y de la “tokenización”, un proceso que consiste en dividir el texto en unidades más pequeñas denominadas tokens.
Para lograr una mayor calidad, algunas startups implementan técnicas de aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) en este proceso. Además de esto, será necesario realizar ajustes precisos basados en la instrucción para ajustar una tarea específica. Se trata de una técnica costosa y que requiere mucho tiempo en comparación con las demás. Los pesos del modelo se actualizan en todas las capas.
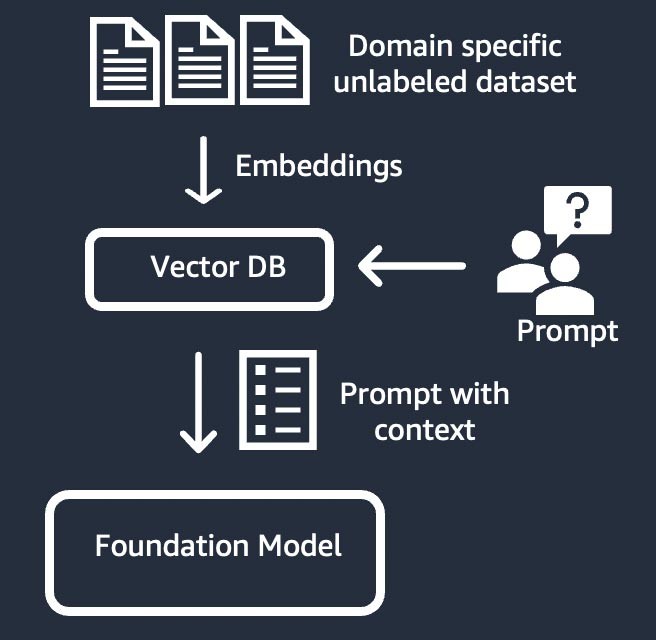
Recuperación de información (también conocida como “generación aumentada de recuperación” o “RAG”)
Esta técnica amplía el modelo fundacional con un sistema de recuperación de información que se basa en una representación vectorial densa. El conocimiento de dominio cerrado o los datos patentados pasan por un proceso de incrustación de texto para generar una representación vectorial del corpus y se almacenan en una base de datos vectorial. El resultado de una búsqueda semántica basado en la consulta del usuario se convierte en el contexto de la solicitud. El modelo fundacional se utiliza para generar una respuesta basada en la solicitud con contexto. En esta técnica, el peso del modelo fundacional no se actualiza.
Componentes de una aplicación de IA generativa
En las secciones anteriores, aprendimos varios enfoques que las startups pueden adoptar con los modelos fundacionales cuando crean aplicaciones de IA generativa. Repasemos cómo estos modelos fundacionales forman parte de los ingredientes o componentes típicos necesarios para crear una aplicación de IA generativa.
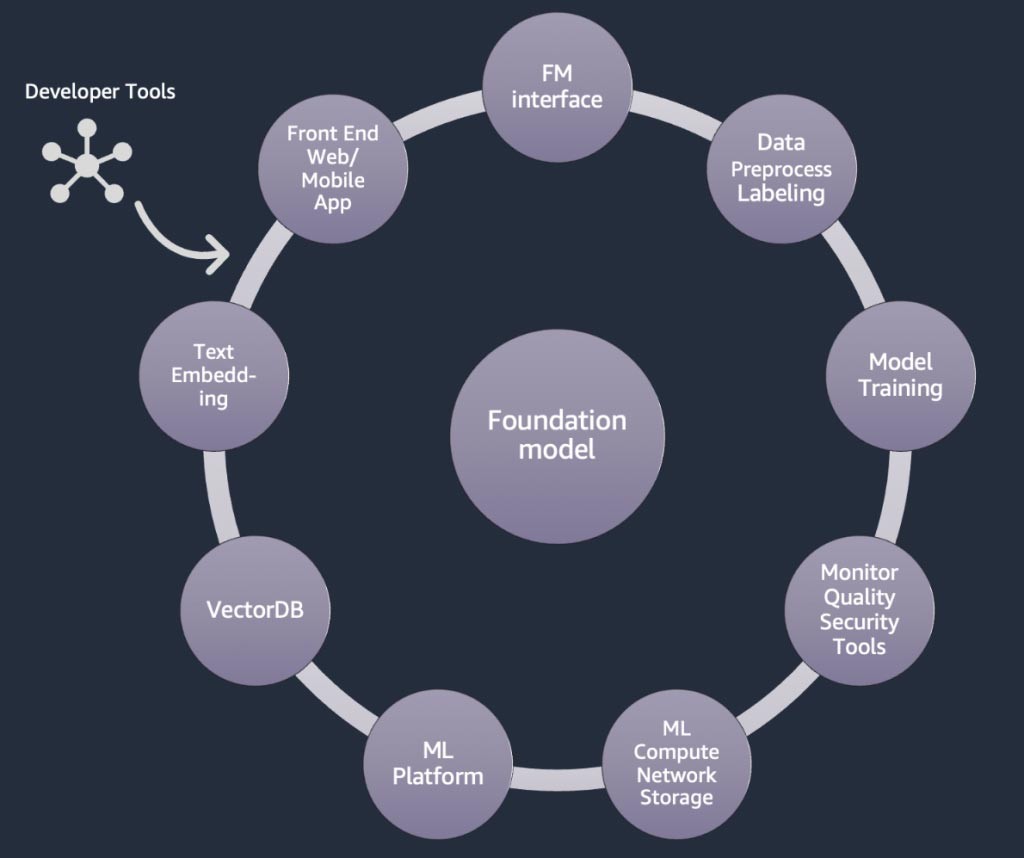
En el núcleo, se encuentra un modelo fundacional (centro). En el enfoque más simple descrito anteriormente en este blog, se requiere una aplicación web o una aplicación móvil (arriba a la izquierda) que acceda al modelo fundacional a través de una API (arriba). Esta API es un servicio administrado a través de un proveedor de modelos o se aloja automáticamente mediante un modelo de código abierto o patentado. En el caso del autoalojamiento, es posible que necesite una plataforma de machine learning compatible con instancias de computación acelerada para alojar el modelo.
En la técnica RAG, necesitará agregar un punto de conexión de incrustación de texto y una base de datos vectorial (izquierda e inferior izquierda). Ambos se ofrecen como un servicio de API o están autoalojados. El punto de conexión de incrustación de texto está respaldado por un modelo fundacional, y la elección del modelo fundacional depende de la lógica de incrustación y del soporte de tokenización. Todos estos componentes están conectados entre sí mediante herramientas para desarrolladores, que proporcionan el marco para desarrollar aplicaciones de IA generativa.
Y, por último, cuando elige las técnicas de personalización para un ajuste preciso o la continuación del entrenamiento previo de un modelo fundacional (derecha), necesita componentes que ayuden con el preprocesamiento y la anotación de los datos (arriba a la derecha), y una plataforma de ML (abajo) para ejecutar el trabajo de capacitación en instancias de computación acelerada específicas. Algunos proveedores de modelos admiten ajustes precisos basados en API y, en esos casos, no hay que preocuparse por la plataforma de ML ni por el hardware subyacente.
Independientemente del enfoque de personalización, es posible que también desee integrar componentes que proporcionen herramientas de supervisión, métricas de calidad y seguridad (parte inferior derecha).
¿Qué servicios de AWS debo usar para crear mi aplicación de IA generativa?
En el siguiente diagrama, figura 9, se asigna cada componente a los servicios de AWS correspondientes. Tenga en cuenta que se trata de un conjunto seleccionado de servicios de AWS de los que veo que las startup se benefician; sin embargo, hay otros servicios de AWS disponibles.
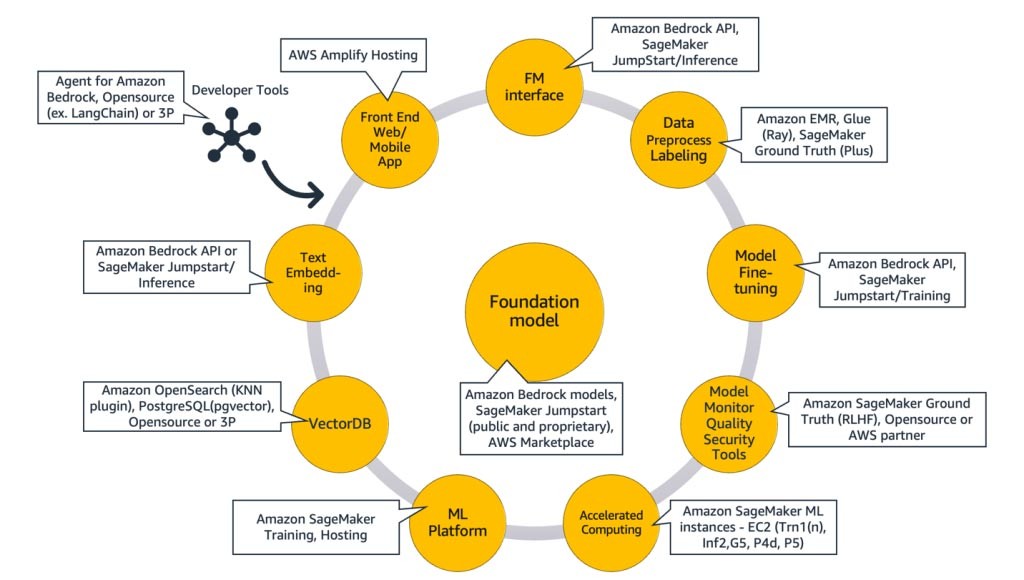
Para dar más detalles, comenzaré por asignar los servicios de AWS a los componentes comunes de una aplicación de IA generativa. A continuación, explicaré los servicios de AWS que se asignan a los componentes restantes de la figura 9, en función de los enfoques que utilice para implementar la aplicación.
Componentes comunes
Los componentes comunes de una aplicación de IA generativa son el modelo fundacional (FM), su interfaz y, opcionalmente, la plataforma de machine learning (ML) y la computación acelerada. Estos se pueden cumplir con las ofertas administradas disponibles en AWS:
Amazon Bedrock (modelo fundacional y sus componentes de interfaz)
Amazon Bedrock, un servicio totalmente administrado que hace que los modelos fundacionales de las principales startups de IA (Jurassic de AI21, Claude de Anthropic, Command and Embedding de Cohere, modelos SDXL de Stability) y Amazon (modelos Titan Text y Embeddings) estén disponibles mediante API, de modo que puede elegir entre una amplia gama de máquinas virtuales para encontrar el modelo que mejor se adapte a su caso de uso. Amazon Bedrock proporciona acceso mediante API o sin servidor a un conjunto de modelos fundacionales para ofrecer tres capacidades: incrustación de texto, solicitud/respuesta y ajuste preciso (en algunos modelos).
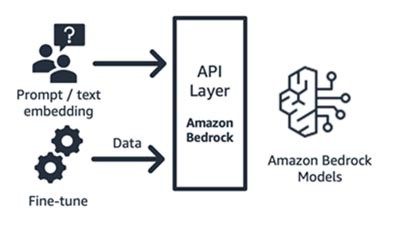
Amazon Bedrock es ideal para startups de consumo basadas en aplicaciones o modelos que crean servicios de valor agregado (ingeniería rápida, generación aumentada de recuperación, etc.) en torno al modelo fundacional de su elección. Su modelo de precios es de pago por uso, normalmente por unidad de millones de tokens procesados. Normalmente, Amazon Bedrock está disponible; sin embargo, algunas de las características que se describen en este blog se encuentran en versión preliminar privada. Obtenga más información aquí.
Amazon SageMaker JumpStart (modelo fundacional y sus componentes de interfaz)
AWS ofrece capacidades de IA generativa a Amazon SageMaker Jumpstart: un hub de modelos fundacionales que contiene modelos patentados y disponibles para el público, soluciones de inicio rápido y cuadernos de ejemplos para implementar y ajustar modelos. Cuando despliega estos modelos, se crea un punto de conexión de inferencia en tiempo real al que puede acceder directamente mediante el SDK o la API de SageMaker. O bien, puede gestionar el punto de conexión del modelo fundacional de SageMaker con AWS API Gateway y una lógica de computación ligera en una función de AWS Lambda . También puede aprovechar algunos de estos modelos para la incrustación de texto.
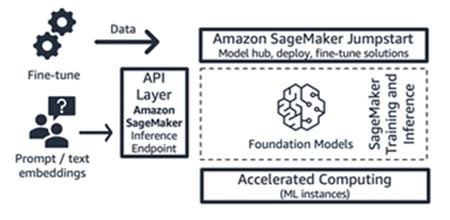
Tanto el punto de conexión de inferencia como los trabajos de entrenamiento de ajuste preciso se ejecutan en las instancias de ML administradas que elija (consulte “Computación acelerada” en la figura 9) y utilizan SageMaker como plataforma de ML (consulte “Plataforma de ML” en la figura 9). SageMaker Jumpstart es ideal para startups dedicadas al consumo de aplicaciones o modelos que desean tener más control sobre su infraestructura y que tienen conocimientos moderados de ML y de infraestructura. Su modelo de precios es de pago por uso, normalmente en la unidad de horas de instancia. Todos los modelos y soluciones de esta oferta están disponibles de forma general.
Entrenamiento e inferencia de Amazon SageMaker (plataforma de ML)
Las startups pueden aprovechar las características de entrenamiento e inferencia de Amazon SageMaker para obtener funciones avanzadas como el entrenamiento distribuido, la inferencia distribuida, los puntos de conexión multimodeloy más. Puede utilizar los modelos fundacionales del hub de modelos que prefiera, ya sea SageMaker JumpStart, Hugging Face o AWS Marketplace, o puede crear su propio modelo fundacional desde cero.
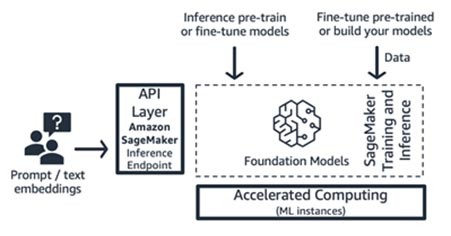
SageMaker es ideal para desarrolladores de pila completa de aplicaciones de IA generativa (desde proveedores de modelos hasta consumidores de modelos), o para proveedores de modelos con equipos que tienen habilidades avanzadas de ML y preprocesamiento de datos. SageMaker también ofrece un modelo de precios de pago por uso, normalmente en unidades de horas de instancia.
AWS Trainium y AWS Inferentia (computación acelerada)
En abril de 2023, AWS anunció la disponibilidad general de las instancias Trn1n de Amazon EC2 con tecnología AWS Trainium y las instancias Inf2 de Amazon EC2 con tecnología de AWS Inferentia2. Puede aprovechar los aceleradores de AWS diseñados específicamente (AWS Trainium y AWS Inferentia) utilizando SageMaker como plataforma de ML.
Las pruebas comparativas para cargas de trabajo de inferencia indican que las instancias Inf2 tienen costes un 52 % inferiores a los de una instancia de Amazon EC2 comparable optimizada para inferencias. Sugiero que preste atención a los ciclos de desarrollo rápidos del SDK de AWS Neuron, en los que aproximadamente cada mes AWS agrega una nueva arquitectura modelo a su matriz de soporte , tanto para entrenamiento como para inferencia.
Enfoques para crear aplicaciones de IA generativa
Analicemos cada uno de los componentes de la figura 9 desde una perspectiva de implementación.
El enfoque de inferencia de aprendizaje desde cero o de pocos pasos
Como comentamos anteriormente, el aprendizaje desde cero o de pocos pasos es el enfoque más simple para crear una aplicación de IA generativa. Para crear aplicaciones basadas en este enfoque, lo único que necesita son los servicios de los cuatro componentes comunes (el modelo fundacional, su interfaz, la plataforma de ML y la computación), su código personalizado para generar solicitudes y una aplicación web o móvil frontend.
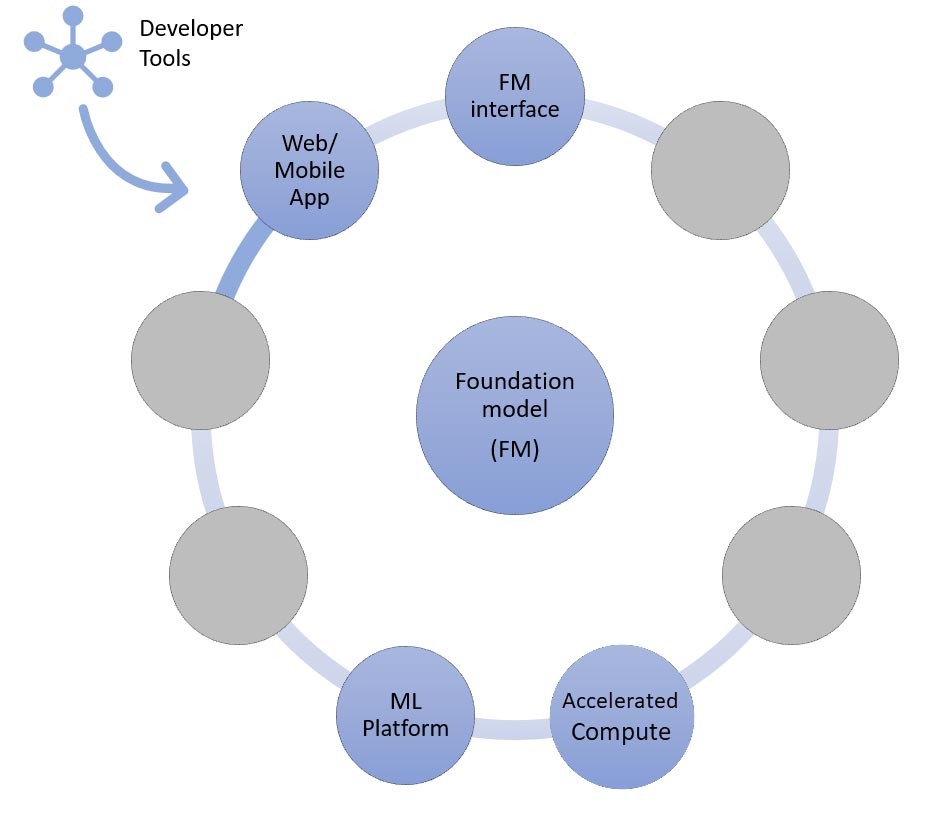
Para obtener más información sobre cómo seleccionar un modelo fundacional mediante Amazon Bedrock o Amazon SageMaker JumpStart, consulte las pautas de selección de modelos aquí.
El código personalizado puede aprovechar herramientas de desarrollo como LangChain para generar solicitudes y sus plantillas. La comunidad de LangChain ya agregó soporte para los puntos de conexión de Amazon Bedrock, Amazon API Gateway y SageMaker. Solo como recordatorio, tal vez quiera aprovechar Amazon CodeWhisperer de AWS, una herramienta complementaria de programación, para ayudar a mejorar la eficiencia de los desarrolladores.
Las startups que crean una aplicación web frontend o una aplicación móvil pueden empezar y escalar fácilmente con AWS Amplify, y alojar estas aplicaciones web de forma rápida, segura y confiable con AWS Amplify Hosting.
Consulte este ejemplo de aprendizaje desde cero que se crea con SageMaker Jumpstart.
Enfoque de recuperación de información
Como ya se ha mencionado, una de las formas en que su startup puede personalizar los modelos fundacionales es mediante el uso de un sistema de recuperación de información, más comúnmente conocido como generación aumentada de recuperación (RAG). Este enfoque incluye todos los componentes que se mencionan en el aprendizaje desde cero y de pocos pasos, así como el punto de conexión de las incrustaciones de texto y la base de datos vectorial.
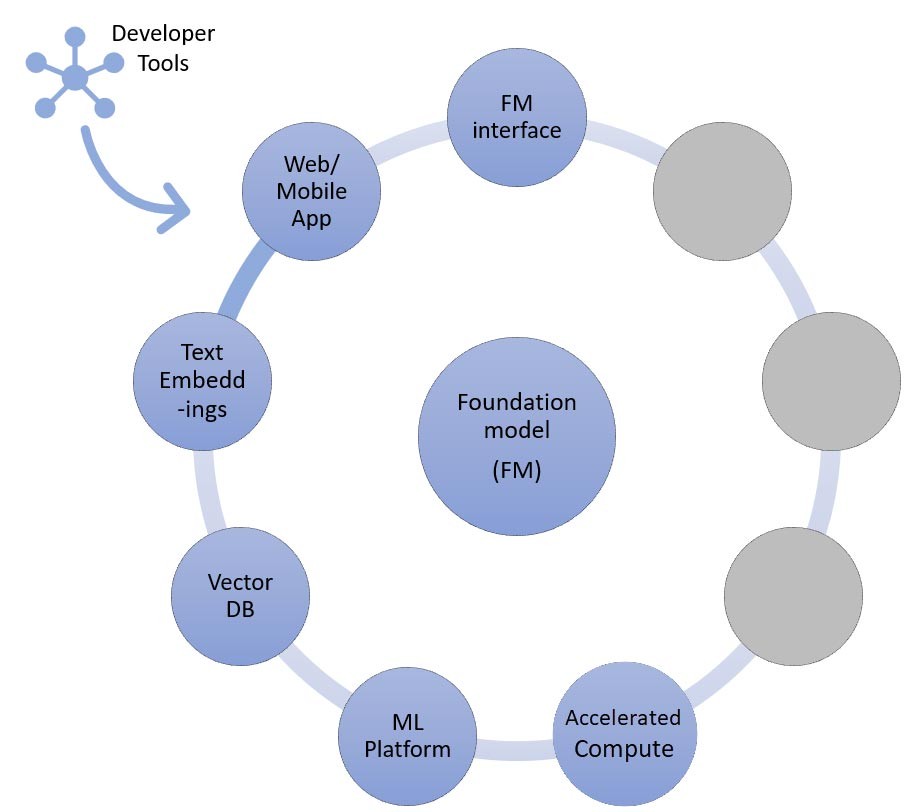
Las opciones para el punto de conexión de las incrustaciones de texto varían en función del servicio administrado de AWS seleccionado:
- Amazon Bedrock ofrece un modelo de lenguaje de gran tamaño (LLM) de incrustaciones que traduce las entradas de texto (palabras, frases y grandes unidades de texto) en representaciones numéricas (conocidas como incrustaciones) que contienen el significado semántico del texto.
- Si utiliza SageMaker JumpStart, puede alojar un modelo de incrustaciones como el GPT-J 6B o cualquier otro LLM de su elección desde el hub de modelos. El SDK de SageMaker o Boto3 pueden invocar el punto de conexión de SageMaker para convertir las entradas de texto en incrustaciones.
Luego, las incrustaciones se pueden almacenar en un almacén de datos vectoriales para realizar búsquedas semánticas utilizando Amazon RDS para PostgreSQL para la extensión pgvector o el complemento k-NN de Amazon OpenSearch Service . Las startups prefieren una u otra en función del servicio con el que suelen sentirse más cómodas. En algunos casos, las startups utilizan bases de datos vectoriales nativas de IA de socios de AWS o de código abierto. Para obtener orientación sobre la selección de almacenes de datos vectoriales, recomiendo consultar El rol de los almacenes de datos vectoriales en las aplicaciones de IA generativa.
También en este enfoque, las herramientas para desarrolladores desempeñan un papel fundamental. Proporcionan un marco fácil de conectar y usar, plantillas de solicitudes y una amplia compatibilidad con las integraciones.
De ahora en adelante, también puede aprovechar los agentes para Amazon Bedrock, una nueva capacidad para los desarrolladores que puede administrar las llamadas API a los sistemas de su empresa.
Consulte este ejemplo del uso de la generación aumentada de recuperación con modelos fundacionales en Amazon SageMaker Jumpstart.
Enfoque de ajuste preciso o perfeccionamiento del entrenamiento previo
Asignemos los componentes a los servicios de AWS necesarios para el último enfoque de implementación de una aplicación de IA generativa: el ajuste preciso o el perfeccionamiento del entrenamiento previo de un modelo fundacional. Este enfoque incluye todos los componentes analizados en el aprendizaje desde cero o de pocos pasos, así como el preprocesamiento de los datos y el entrenamiento con modelos.
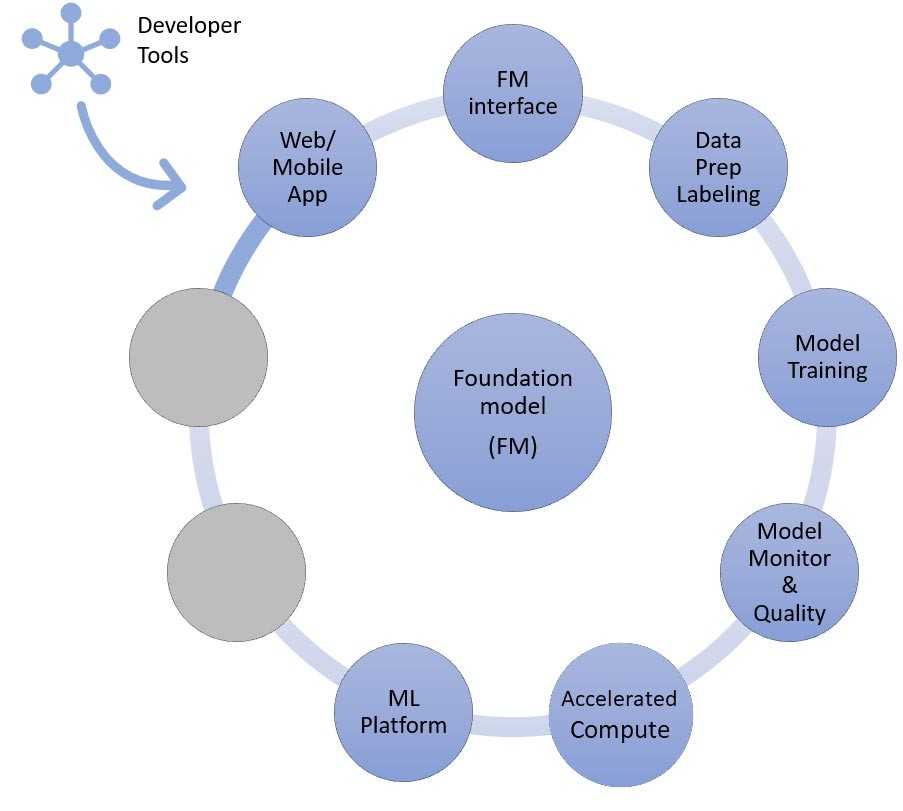
La preparación de los datos (a veces denominada preprocesamiento o anotación) es particularmente importante durante el ajuste preciso, en el que se necesitan conjuntos de datos más pequeños y etiquetados. Las startup pueden empezar a utilizar Amazon SageMaker Data Wrangler fácilmente. Este servicio ayuda a reducir el tiempo que se tarda en agregar y preparar datos tabulares e imágenes para machine learning, de semanas a minutos. También puede aprovechar la característica de canalización de inferencias de este servicio para encadenar el flujo de trabajo de preprocesamiento previo a los trabajos de entrenamiento o ajuste preciso.
Si su startup necesita preprocesar un enorme corpus de conjuntos de datos no estructurados y sin etiquetar en su lago de datos de Amazon S3, tiene varias opciones:
- Si utiliza Python y bibliotecas populares de Python, es útil aprovechar AWS Glue para Ray. AWS Glue usa Ray, un marco de computación unificado de código abierto que se utiliza para escalar las cargas de trabajo de Python
- Como alternativa, Amazon EMR puede ayudar a procesar grandes cantidades de datos mediante herramientas de código abierto como Apache Spark, Apache Hive, Apache HBase, Apache Flink, Apache Hudi y Presto.
Para el componente de formación de modelos de este enfoque, Amazon Bedrock permite personalizar de forma privada los FM con sus propios datos. Administra sus FM a escala sin tener que administrar ninguna infraestructura (esta es la forma de ajuste preciso de las API). Como alternativa, el enfoque Jumpstart de SageMaker proporciona una solución de inicio rápido que permite un ajuste preciso de forma privada (en algunos modelos) para las instrucciones o la adaptación del dominio utilizando sus propios datos. Puede modificar el guion de entrenamiento incluido en el paquete JumpStart de SageMaker según sus necesidades, o puede traer sus propios guiones de entrenamiento para los modelos de código abierto y enviarlos como trabajo de entrenamiento de SageMaker. Si necesita seguir entrenando previamente al modelo (normalmente para los modelos de código abierto), puede aprovechar las bibliotecas de entrenamiento distribuido de SageMaker para acelerar y utilizar de forma eficiente todas las GPU de una instancia de ML.
Además, también puede considerar la generación de datos totalmente administrada, los servicios de anotación de datos y el desarrollo de modelos con la técnica de aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) mediante Amazon SageMaker Ground Truth Plus.
Un ejemplo de arquitectura
Entonces, ¿cómo se ven todos estos componentes cuando se realiza un caso de uso de IA generativa? Si bien cada startup tiene un caso de uso diferente y enfoques únicos para resolver los problemas del mundo real, un tema o punto de partida común que he visto cuando se crean aplicaciones de IA generativa es el enfoque de generación aumentada de recuperación. Tras incorporar todos los servicios de AWS descritos anteriormente, la arquitectura tiene el siguiente aspecto:
Canalización de ingestión : los datos patentados o específicos del dominio se procesan previamente como datos de texto. Se procesan por lotes (se almacenan en Amazon S3) o se transmiten (mediante Amazon Kinesis) a medida que se crean o se actualizan mediante el proceso de incrustación, y se almacenan en una representación vectorial densa.

Canalización de recuperación : cuando un usuario consulta los datos patentados almacenados en la representación vectorial, recupera los documentos relacionados mediante el vecino más cercano (kNN) o la búsqueda semántica. A continuación, se decodifica de nuevo para obtener un texto claro. El resultado sirve como un contexto rico y denso para la solicitud.

Proceso de generación de canalizaciones : el contexto se agrega a la solicitud con la consulta original del usuario para obtener información o un resumen del documento recuperado.

Todas estas capas se pueden crear con unas pocas líneas de código mediante herramientas para desarrolladores, como LangChain.
Conclusión
Esta es una forma de crear una aplicación de IA generativa integral mediante los servicios de AWS. Los servicios de AWS que seleccione variarán según el caso de uso o el enfoque de personalización que adopte. Manténgase informado sobre las últimas publicaciones, soluciones y blogs de AWS sobre IA generativa marcando este enlace como favorito.
¡Vamos a crear aplicaciones de IA generativas en AWS! Comience su viaje hacia la IA generativa con AWS Activate, un programa gratuito diseñado específicamente para startups y emprendedores en fase inicial que ofrece los recursos necesarios para comenzar a usar AWS.

Hrushikesh Gangur
Hrushikesh Gangur es Arquitecto principal de soluciones para startups de IA/ML, con experiencia en los servicios de redes y machine learning de AWS. Ayuda a las startups a crear plataformas de IA generativa, vehículos autónomos y aprendizaje automático para gestionar sus negocios de forma eficiente y eficaz en AWS.
¿Qué le pareció este contenido?