Amazon Redshift
A melhor relação entre preço e performance para data warehouse na nuvemPor que usar o Amazon Redshift?
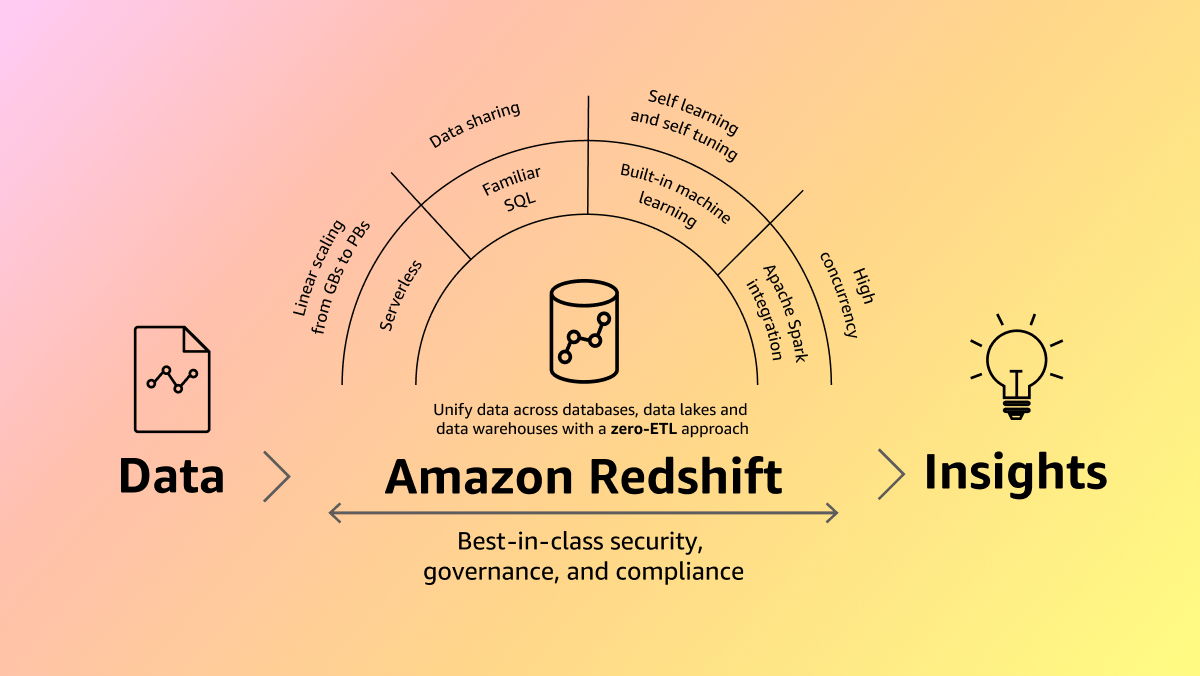
Dezenas de milhares de clientes usam o Amazon Redshift todos os dias para modernizar as workloads de análise de dados e obter insights para os negócios. Com uma arquitetura de processamento paralelo massivo (MPP) totalmente gerenciada, alimentada por IA, o Amazon Redshift impulsiona a tomada de decisões de negócios de forma rápida e econômica. A abordagem ETL zero da AWS unifica todos os dados para análises poderosas, casos de uso quase em tempo real e aplicações de AI/ML. Compartilhe e colabore em dados com facilidade e segurança dentro e entre organizações, regiões da AWS e até mesmo provedores de dados terceirizados, com o suporte de recursos de segurança líderes do setor e governança refinada.
Benefícios
Como funciona
Casos de uso
Amazon Redshift sem servidor
Realize a execução e a escalabilidade das análises em segundos e de forma fácil, sem a necessidade de provisionar e gerenciar um data warehouse