With Deep Learning, Disney Sorts Through a Universe of Content
Em um episódio de 1957 da série de TV Disneylândia, Walt Disney conduziu os espectadores às profundezas do seu estúdio de animação em Burbank. “No nosso necrotério” - disse ele, referindo-se à biblioteca subterrânea -, “essas prateleiras, mesas e armários de arquivos guardam toda a história do nosso estúdio de cinema”.
Em um episódio de 1957 da série de TV Disneylândia, Walt Disney conduziu os espectadores às profundezas do seu estúdio de animação em Burbank. “No nosso necrotério” - disse ele, referindo-se à biblioteca subterrânea -, “essas prateleiras, mesas e armários de arquivos guardam toda a história do nosso estúdio de cinema”.
Muio antes de outros estúdios de animação, Disney insistia que esse arquivo fosse acessível a escritores e ilustradores, que poderiam precisar dele como referência ou inspiração. Desenhos, ilustrações conceituais e mais informações sobre trabalhos favoritos, como Dumbo e Peter Pan, foram cuidadosamente guardados nessa câmara. E, desde aquela época, a Disney está comprometida com a preservação.
Com quase um século de conteúdo nas mãos, grande parte digitalizada, a Disney precisa organizar sua biblioteca com mais cuidado do que nunca. Manter a ordem e a limpeza entre as pilhas (virtuais) é tarefa de um pequeno grupo de engenheiros de P&D e de cientistas de informações que fazem parte de uma equipe de Tecnologia internacional e direta ao consumidor (DTCI) da Disney. A DTCI foi formada em 2018, em parte para reunir tecnólogos e experiência de toda a Walt Disney Company para dar suporte à enorme matriz de conteúdo exclusivo e às necessidades comerciais da Disney.
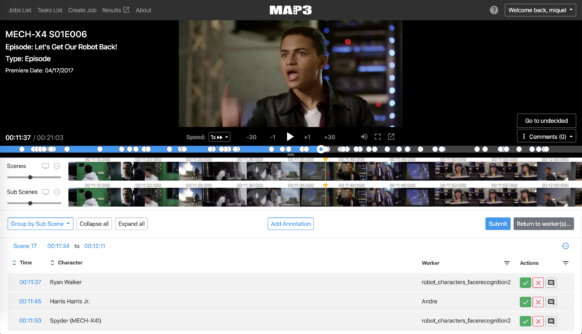
A base do sistema organizacional são os metadados: informações sobre as histórias, cenas e personagens dos programas e filmes da Disney. Por exemplo, Bambi teria tags de metadados para identificar não apenas os personagens, como o coelho Tambor ou o gambá Flor, mas o tipo de animal, as relações entre os animais e os arquétipos dos personagens que cada animal retrata. As cenas na natureza, detalhando até os tipos específicos de flores retratados, a música, o sentimento e o tom da história, também possuem tags específicas. Como resultado, a marcação adequada com tags de todo esse conteúdo, com os metadados corretos permitindo que o conteúdo seja ordenado corretamente, é um desafio, principalmente considerando o ritmo intenso do crescimento da Disney:
“Temos novos personagens em programas de TV, jogadores de futebol trocando de equipe, novas armas para super-heróis, novos programas”, disse Miquel Farré, chefe da equipe técnica, e tudo isso exige um monte de metadados novos.
Com a ajuda dos serviços da AWS, ele e sua equipe estão desenvolvendo ferramentas de machine learning e aprendizado profundo para automaticamente marcar esse conteúdo com tags com metadados descritivos para tornar o processo de arquivamento mais eficiente. Como resultado, os autores e os animadores podem rapidamente pesquisar e se familiarizar com todos os personagens, do Mickey ao Phil Dunphy da Modern Family.
O que é tão mágico sobre os metadados?
Imagem cortesia da Disney
A equipe que lidera esse trabalho foi formada, originalmente, em 2012, como parte do Disney & ABC Television Group. Ao longo dos anos, a equipe cresceu e, atualmente, como parte do grupo de tecnologia DTCI da Disney, tornou-se o índice e a base de conhecimento dos estilos e convenções do universo Disney (por exemplo, em Bambi, os animais falam e, em Branca de neve, não). Para que suas ferramentas de machine learning gerem metadados que descrevam com precisão o conteúdo criativo, a equipe depende dos autores e animadores para explicar os aspectos estilísticos que transformam cada programa em algo exclusivo.
Esses membros da equipe criativa se beneficiam da cooperação dessas ferramentas. Depois que o conteúdo é marcado com metadados precisos, a equipe pode achar facilmente aquilo de que precisa por meio de uma interface de pesquisa. Por exemplo, um autor de Grey”s Anatomy, para evitar redundância, pode precisar saber quantas vezes a cirurgia de Whipple foi apresentada em um episódio. Enquanto isso, um artista que está trabalhando em um novo desenho animado no fundo do mar pode querer procurar a postura ou o posicionamento de um personagem específico em A pequena sereia ou Procurando Nemo para obter inspiração.
Porém, marcar tudo com tags rapidamente com os metadados certos pode apresentar um problema de mão de obra: ainda wue a marcação manual com tags seja uma parte importante do processo, a equipe de tecnologia DTCI não tem tempo para categorizar cada quadro manualmente. É por isso que a equipe de Farré passou a usar machine learning e, mais recentemente, aprendizado profundo, na tarefa de geração de metadados. O objetivo é desenvolver algoritmos de aprendizado profundo que possam automaticamente marcar com tags os componentes de uma cena de forma consistente com o resto da base de conhecimento da Disney. Os seres humanos ainda precisam aprovar as tags do algoritmo, mas o projeto está reduzindo significativamente o trabalho necessário para organizar a biblioteca da Disney, melhorando a precisão das pesquisas feitas nela.
Além disso, esse progresso está liberando os engenheiros para que se concentrem mais no desenvolvimento de modelos de aprendizado profundo usando a AWS (Amazon Web Services). E, como resultado, os esforços deles para a automatização da criação de metadados em diferentes tipos de conteúdo da Disney estão progredindo.

O aprendizado profundo dá identidade às animações
Imagem cortesia da Disney
Um dos projetos de metadados de aprendizado profundo foi a solução de problemas apresentados pelo reconhecimento de animação.
Em um filme ou programa de TV protagonizado por pessoas, para uma máquina, separar o personagem do que está ao seu redor é relativamente simples. Mas a animação torna as coisas mais complicadas. Por exemplo, uma cena em que o personagem aparece em carne e osso e também em um cartaz (digamos que o personagem é um criminoso e cartazes de “Procura-se” foram afixados em toda a cidade). “Para um algoritmo, isso é extremamente complexo”, disse Farré.
No ano passado, a equipe de Farré desenvolveu um método de aprendizado profundo que pode distinguir personagens animados das suas representações estáticas, identificá-los em uma multidão de sósias (como em Os caçadores de aventuras, em que muitos personagens são quase idênticos) e reconhecê-los em cenas com iluminação diferente (em Alice no país das maravilhas, quando Alice encontra o Gato Risonho e ele mostra o sorriso cheio de dentes). Depois de decidir o que é o que, o algoritmo pode marcar com tags as cenas com os metadados adequados.
Mas o verdadeiro poder do modelo é que ele pode ser aplicado a qualquer parte de conteúdo animado. Ou seja, em vez de criar um novo modelo para cada Pateta, Hércules ou Elsa, a equipe só precisa usar o modelo genérico deles que, com pequenos ajustes, funcionará para qualquer personagem em qualquer programa ou filme.
Antes deste ano, a equipe estava trabalhando com algoritmos de machine learning mais tradicionais, que necessitam de menos dados do que uma abordagem de aprendizado profundo, mas que também geravam resultados mais limitados e menos flexíveis. Com menos informações de dados, os algoritmos tradicionais funcionam bem. Porém, quando você possui um volume exponencialmente maior de dados, o aprendizado profundo pode fazer um enorme diferença.
Atualmente, disse Farré, o modelo de aprendizado profundo pode se beneficiar de redes já treinadas e de ajustes finos para casos de uso específicos. No caso específico de personagens animados, a Disney fez o ajuste fino de uma rede neural com milhares de imagens para se certificar de que ela entende o conceito de “personagem animado”. Em seguida, para cada programa específico, a rede neural é reajustada com o uso de algumas centenas de imagens de alguns episódios para que ela aprenda como os “personagens animados” deverão ser detectados e interpretados no programa específico.
A AWS foi um parceiro fundamental na transição da Disney de machine learning tradicional para aprendizado profundo, especialmente em termos de experimentação. Instâncias elásticas de computação em nuvem do EC2 permitem que a equipe teste rapidamente novas versões do modelo. (Para o projeto de reconhecimento de animação, a Disney está usando a estrutura de trabalho PyTorch com modelos pré-treinados.) Como existe um grande volume de pesquisas ocorrendo no aprendizado profundo, a equipe está constantemente experimentando modelos novos e recentes.
A pesquisa de metadados tem sido tão bem-sucedida que os departamentos de toda a Disney a conheceram. Farré disse que sua equipe recentemente se envolveu com a equipe de personalização da ESPN para fornecer metadados detalhados sobre todos os artigos e vídeos que são exibidos nos aplicativos digitais e sites líderes do setor. Se o produto souber que você é fã dos Los Angeles Dodgers, de Steph Curry, dos Minnesota Vikings e do Manchester United, quanto mais metadados ele tiver sobre cada artigo, mais ele poderá garantir que você receba conteúdo mais alinhado com suas preferências. Além disso, os algoritmos de machine learning, juntamente com os metadados que eles fornecem, podem criar uma IA mais avançada para promover uma personalização ainda mais implícita (com base nas relações e nos comportamentos dos dados) ao longo do tempo.
Conforme Farré visualiza, os aplicativos para metadados são infinitos, principalmente devido à vasta e crescente biblioteca da Disney de conteúdos, personagens e produtos distintos. “Acho que não ficaremos entediados”, disse ele.