- Amazon SageMaker AI
- Amazon SageMaker HyperPod
- Atributos
Atributos do Amazon SageMaker HyperPod
Escale e acelere o desenvolvimento de modelos de IA generativa em milhares de aceleradores de IA
Treinamento sem necessidade de pontos de verificação
O treinamento sem necessidade de pontos de verificação no Amazon SageMaker HyperPod permite a recuperação automática de falhas de infraestrutura em minutos, sem intervenção manual. Ele reduz a necessidade de uma reinicialização em nível de trabalho baseada em pontos de verificação para recuperação de falhas, o que exige pausar todo o cluster, corrigir problemas e retomar de um ponto de verificação salvo. O treinamento sem necessidade de pontos de verificação mantém o progresso do treinamento apesar das falhas, pois o SageMaker HyperPod troca automaticamente os componentes defeituosos e recupera o treinamento usando a transferência ponto a ponto dos estados do modelo e do otimizador de aceleradores de IA íntegros. Ele permite mais de 95% de bons resultados de treinamento em clusters com milhares de aceleradores de IA. Com o treinamento sem necessidade de pontos de verificação, economize milhões em custos de computação, escale o treinamento para milhares de aceleradores de IA e coloque seus modelos em produção mais rapidamente.
Treinamento flexível
O treinamento flexível no Amazon SageMaker HyperPod escala automaticamente as tarefas de treinamento com base na disponibilidade de recursos computacionais, economizando horas de engenharia por semana, que antes eram gastas na reconfiguração de tarefas de treinamento. A demanda por aceleradores de IA flutua constantemente à medida que as workloads de inferência se adaptam aos padrões de tráfego, experimentos concluídos liberam recursos e novas tarefas de treinamento mudam as prioridades da workload. O SageMaker HyperPod expande dinamicamente as tarefas de treinamento em execução para absorver aceleradores de IA ociosos, maximizando a utilização da infraestrutura. Quando workloads de maior prioridade, como inferência ou avaliação, precisam de recursos, o treinamento é reduzido para continuar com menos recursos sem parar totalmente, gerando a capacidade necessária com base nas prioridades estabelecidas por meio de políticas de governança de tarefas. O treinamento flexível ajuda você a acelerar o desenvolvimento de modelos de IA e, ao mesmo tempo, reduzir os custos excessivos causados pela computação subutilizada.
Governança de tarefas
Planos de treinamento flexíveis
Instâncias spot do Amazon SageMaker HyperPod
As instâncias spot no SageMaker HyperPod permitem que você acesse a capacidade computacional com custos significativamente reduzidos. As instâncias spot são ideais para workloads tolerantes a falhas, como trabalhos de inferência em lote. Os preços variam de acordo com a região e o tipo de instância, geralmente oferecendo um desconto de até 90% em comparação com os preços do SageMaker HyperPod On-Demand. Os preços de instâncias spot são definidos pelo Amazon EC2 e ajustados gradualmente de acordo com tendências de longo prazo da oferta e da demanda de capacidade de instâncias spot. Você paga o preço do spot que está em vigor durante o período em que suas instâncias estão em execução, sem a necessidade de compromisso inicial. Para saber mais sobre os preços estimados das instâncias spot e a disponibilidade das instâncias, acesse a página de preços das instâncias spot do EC2. Observe que somente instâncias que também são compatíveis com o HyperPod estão disponíveis para uso do spot no HyperPod.
Receitas otimizadas para personalizar modelos
Com as receitas do SageMaker HyperPod, cientistas de dados e desenvolvedores de todos os níveis de habilidade se beneficiam do desempenho de última geração e podem rapidamente começar a treinar e ajustar modelos básicos disponíveis publicamente, incluindo modelos Llama, Mixtral, Mistral e DeepSeek. Além disso, é possível personalizar os modelos do Amazon Nova, incluindo Nova Micro, Nova Lite e Nova Pro, usando um conjunto de técnicas que incluem Ajuste Fino Supervisionado (SFT), Destilação de Conhecimento, Otimização Direta de Preferências (DPO), Otimização de Política Proximal e Pré-treinamento Contínuo, com suporte para opções de eficiência de parâmetros e treinamento de modelo completo em SFT, Destilação e DPO. Cada receita inclui uma pilha de treinamento que foi testada pela AWS, economizando semanas de trabalho tedioso testando diferentes configurações de modelos. Você pode alternar entre instâncias baseadas em GPU e AWS Trainium, com uma alteração de receita de uma linha, habilitar os pontos de verificação automatizados de modelos para melhorar a resiliência do treinamento e executar workloads em produção no SageMaker HyperPod.
O Amazon Nova Forge é um programa inédito que oferece às organizações a maneira mais fácil e econômica de criar seus próprios modelos de fronteira usando o Nova. Acesse e treine a partir de pontos de verificação intermediários dos modelos Nova, misture conjuntos de dados selecionados pela Amazon com dados proprietários durante o treinamento e use as receitas do SageMaker HyperPod para treinar seus próprios modelos. Com o Nova Forge, você pode usar seus próprios dados comerciais para desbloquear inteligência específica de casos de uso e melhorias de custo-benefício para suas tarefas.
Treinamento distribuído de alto desempenho
Ferramentas avançadas de observabilidade e experimentação
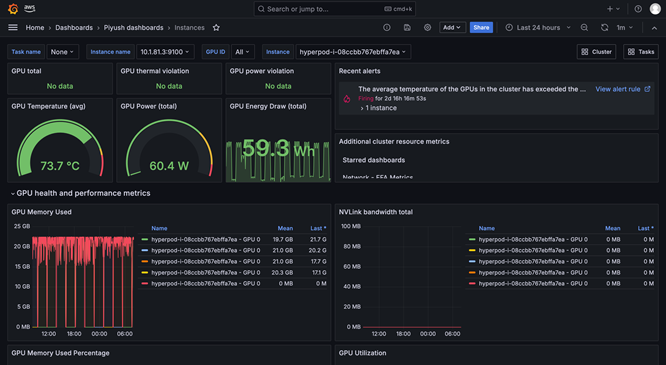
A observabilidade do SageMaker HyperPod fornece um painel unificado pré-configurado no Amazon Managed Grafana, e os dados de monitoramento são publicados automaticamente em um espaço de trabalho do Amazon Managed Prometheus. É possível observar métricas de performance, utilização de recursos e integridade do cluster em tempo real em uma única visualização, permitindo que as equipes identifiquem rapidamente gargalos, evitem atrasos dispendiosos e otimizem os recursos de computação. O SageMaker HyperPod também é integrado ao Amazon CloudWatch Container Insights, fornecendo insights mais detalhados sobre a performance, a integridade e a utilização dos clusters. O TensorBoard gerenciado no SageMaker ajuda você a economizar tempo de desenvolvimento ao visualizar a arquitetura do modelo para identificar e corrigir problemas de convergência. O MLflow gerenciado no SageMaker ajuda você a gerenciar eficientemente experimentos em grande escala.
Programação e orquestração de workloads
Verificação e reparo automáticos da integridade do cluster
Acelere as implantações de modelos de pesos abertos com o SageMaker Jumpstart
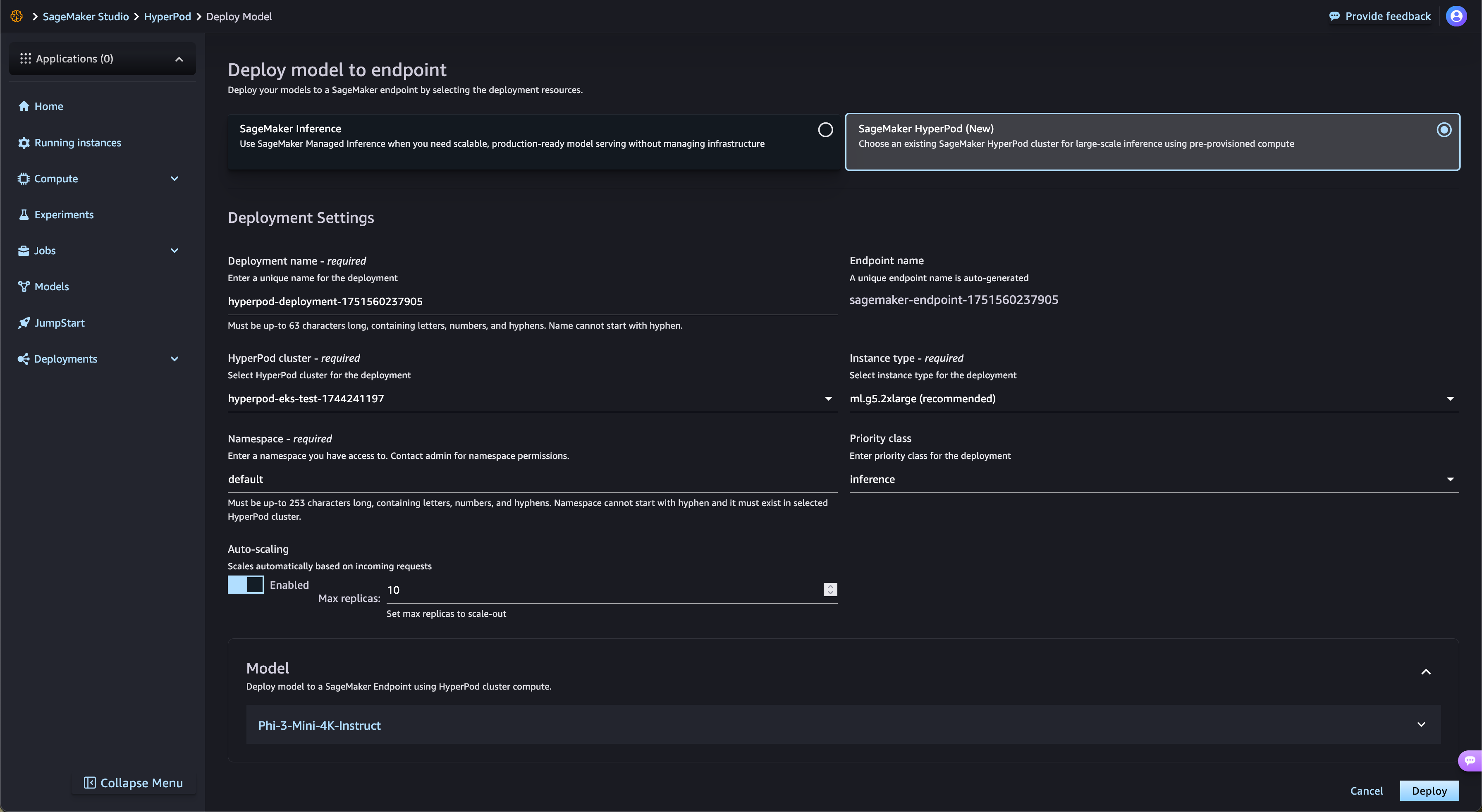
O SageMaker HyperPod simplifica automaticamente a implantação de FMs de peso aberto do SageMaker JumpStart e de modelos ajustados do Amazon S3 e do Amazon FSx. O SageMaker HyperPod provisiona automaticamente a infraestrutura necessária e configura os endpoints, eliminando o provisionamento manual. Com a governança de tarefas do SageMaker HyperPod, o tráfego de endpoints é monitorado continuamente e ajusta dinamicamente os recursos de computação, ao mesmo tempo que publica métricas de performance abrangentes no painel de observabilidade para monitoramento e otimização em tempo real.
Pontos de verificação hierárquicos gerenciados
O ponto de verificação hierárquico gerenciado pelo SageMaker HyperPod usa a memória da CPU para armazenar pontos de verificação frequentes para recuperação rápida, enquanto persiste periodicamente os dados no Amazon Simple Storage Service (Amazon S3) para durabilidade a longo prazo. Essa abordagem híbrida minimiza a perda de treinamento e reduz significativamente o tempo necessário para retomar o treinamento após uma falha. Os clientes podem configurar políticas de frequência e retenção de pontos de verificação em níveis de armazenamento persistente e na memória. Ao armazenar frequentemente na memória, os clientes podem agilizar as recuperações e minimizar os custos de armazenamento. Com a integração do ponto de verificação distribuído (DCP) do PyTorch, os clientes podem implementar facilmente esse recurso com apenas algumas linhas de código e obter os benefícios de performance do armazenamento na memória.
Maximize a utilização de recursos com o particionamento de GPU
O SageMaker HyperPod permite que os administradores particionem os recursos da GPU em unidades computacionais menores e isoladas para maximizar a utilização da GPU. Você pode executar diversas tarefas de IA generativa em uma única GPU em vez de dedicar GPUs completas a tarefas que precisam apenas de uma fração dos recursos. Com métricas de desempenho em tempo real e monitoramento da utilização de recursos em partições de GPU, você obtém visibilidade de como as tarefas estão usando os recursos computacionais. Essa alocação otimizada e a configuração simplificada aceleram o desenvolvimento da IA generativa, melhoram a utilização da GPU e proporcionam o uso eficiente dos recursos da GPU em tarefas em grande escala.
Você encontrou o que estava procurando hoje?
Informe-nos para que possamos melhorar a qualidade do conteúdo em nossas páginas