AWS News Blog
Amazon RDS: Announcing Read Replicas

|
It is possible to characterize the workload handled by a relational database in terms of the ratio of reads to writes. Some applications seem to use about the same number of reads and writes. Others write a little bit of data and read a lot. This read-heavy behavior is frequently seen in web applications.
Different scaling techniques are applicable to different workloads. Read-heavy workloads that place too much of a load on a single database deployment can often be accommodated by distributing the reads to one or more “read replicas.” The read replicas track all of the writes made to the master and can provide an increase in aggregate read throughput when properly implemented.
Well, guess what? You can now set up read replicas for the Amazon Relational Database Service (RDS). You can do this for a single or multi-AZ DB Instance deployment. Here’s a block diagram:
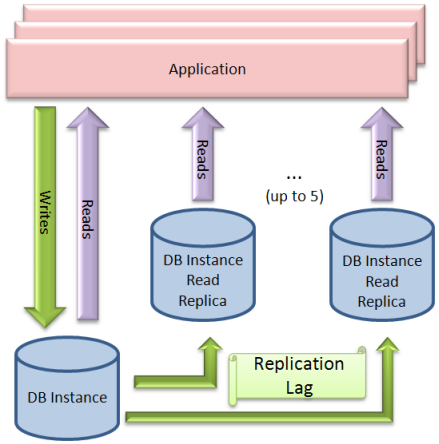
All of the writes are directed to the main DB Instance. The Read Replicas track all changes made on the main DB Instance and update their own copies of the data.
You can choose to read from the main DB Instance or from any of the Read Replicas. If you need strict read-after-write consistency (what you read is what you just wrote) then you should read from the main DB Instance. Otherwise, you should spread out the load and read from one of the Read Replicas. You can make this decision on a query-by-query basis within your application. You will probably want to maintain some sort of registry of available Read Replicas within your application, choosing from among them on a round-robin or randomly distributed basis.
As I noted earlier, the Read Replicas track all of the changes made to the source DB Instance. This is an asynchronous operation (updates are propagated to Read Replicas after they occur on the source DB Instance) and the Read Replicas can sometimes be out of date with respect to the source. This phenomenon is called replication lag and it is a common side-effect of the MySQL replication process. Each Read Replica publishes a Replica Lag metric in Amazon CloudWatch to allow you to see how far it has fallen behind the source DB Instance. You can access this metric via the AWS Management Console and the Amazon CloudWatch APIs, or via the customary “show slave status” MySQL command. When things are running well the lag is generally measured in seconds or a small number of minutes.
Read Replicas are complements, not substitutes, to Multi-AZ deployments. Because of the replication lag you can expect with Read Replicas and MySQL 5.1s built-in replication, Read Replicas are not best-suited to increasing database write availability or protecting your latest database updates in the event of source DB Instance or Availability Zone failure. Instead, you should run your source DB Instance as a Multi-AZ deployment. The replication used by Multi-AZ deployments is synchronous, meaning that all database writes are concurrent on the primary and standby and all of your latest updates to the primary should be available on the standby after failover occurs. In addition, with Multi-AZ deployments replication is fully managed. Amazon RDS automatically monitors for DB Instance failure conditions or Availability Zone failure and initiates automatic failover to the standby in a different Availability Zone if an outage occurs. You can use a Multi-AZ deployment as the source for your Read Replicas, gaining the availability and durability benefits of Multi-AZ, as well as the scaling benefits of Read Replicas.
You can create Read Replicas using the RDS APIs, the RDS command-line tools, or the AWS Management Console.If you use the Amazon RDS APIs, you will call the CreateDBInstanceReadReplica API to create a Read Replica from a specified source DB Instance. For a create to succeed, your source DB Instance must be running MySQL 5.1.50 or later. You can upgrade the DB Instance to the proper version using the ModifyDBInstance API or the Modify Instance menu item in the AWS Management Console. When you create a replica of an existing DB Instance, one of two things happen next:
- For a single AZ DB Instance, the DB Instance pauses briefly while a snapshot is made. The instance then resumes, and the Read Replica is created from the snapshot.
- For a Multi-AZ DB Instance deployment, a snapshot is made from the standby without pausing the primary. The Read Replica is created from the snapshot.
The Read Replica will always have the same MySQL version (e.g. MySQL 5.1.50) as the source DB Instance. Each Read Replica should have at least as much storage and processing power as the source DB Instance. You can scale the processing power and storage of each Read Replica independently of the source DB Instance or of other Read Replicas. As of launch time, each DB Instance can have up to five Read Replicas. Read Replicas are billed at the same rates as standard DB Instances, and standard DB Instance reservations (RDS Reserved Instances) of the same DB Instance class and Region can be applied to Read Replicas.
There are other use cases for a Read Replica beyond increasing effective read traffic capacity. For example, you might want to use a Read Replica for business reporting. This prevents queries by business analysts from impacting the performance of your production DB Instance. For this use case, you might want to add a special index that is only on the Read Replica and is used only for reporting purposes. To do this, you can enable DDL write operations on a given Read Replica by setting a parameter in the Read Replica’s DB Parameter Group. The ability to promote Read Replica into a primary/source DB Instance does not exist at feature launch, but this functionality is coming soon.
It should be fairly easy to create a data-driven auto scaling database cluster using Read Replicas and CloudWatch metrics. At the low end, this cluster would consist of a Small DB Instance running in one Availability Zone with 5 GB of storage. At the high end it would consist of a High Memory Quadruple Extra Large Multi-AZ deployment (primary/secondary pair) DB Instance with 1 TB of storage and 5 associated Read Replicas. That’s quite a range!
— Jeff;