- Amazon Redshift
- Recursos
- Integração para Apache Spark
Integração do Amazon Redshift para Apache Spark
Crie aplicações Apache Spark para leitura e gravação de dados usando o Amazon Redshift
Por que usar o Amazon Redshift Integration for Apache Spark?
Benefícios do Amazon Redshift
-
Expanda a diversidade de fontes de dados que podem ser usadas em suas aplicações avançadas de análise e machine learning (ML) executadas no Amazon EMR, AWS Glue ou SageMaker lendo e gravando dados em seu data warehouse.
-
Simplifique o processo complicado e frequentemente manual de configuração de conectores não certificados e drivers JDBC, reduzindo o tempo de preparação para análises e tarefas de ML.
-
Use vários recursos de pushdown, como classificação, agregação, limite, união e funções escalares para que apenas os dados relevantes sejam movidos do data warehouse do Amazon Redshift.
Como funciona
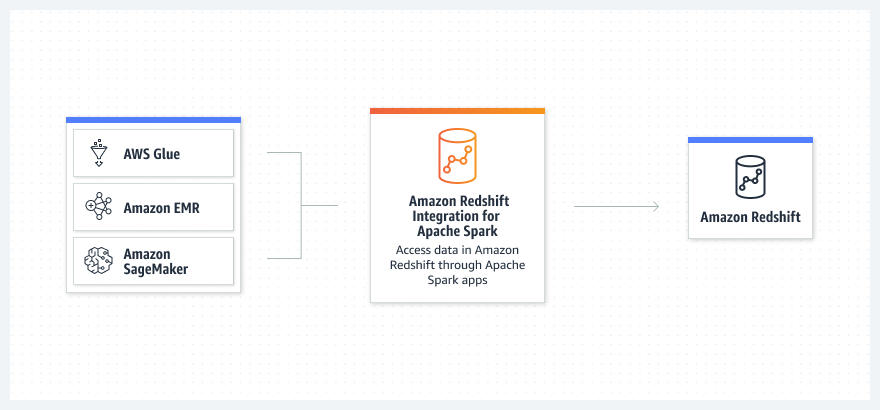
Casos de uso
-
Crie aplicações Apache Spark em Java, Scala e Python com os serviços de análise da AWS baseados no Apache Spark.
-
Leia e grave dados de e para o Amazon Redshift com o Amazon EMR, o AWS Glue, o SageMaker e os serviços de análise e ML da AWS.
-
Use o Amazon EMR ou o AWS Glue para obter o código do quadro de dados de seu trabalho ou bloco de anotações do Apache Spark e conectar ao Amazon Redshift.
-
Simplifique seu processo sem instalação nem teste, segurança aprimorada (credenciais baseadas em IAM) e pushdowns operacionais e formato de arquivo Parquet para aumentar a performance.
Clientes
Corey Johnson, gerente de arquitetura de dados, Huron Consulting
A Huron é uma empresa global de serviços profissionais que colabora com clientes para transformar possibilidades em realidade criando estratégias sólidas, otimizando operações, acelerando a transformação digital e capacitando as empresas e suas equipes a assumir o controle do seu futuro.
“Capacitamos nossos engenheiros a construir seus pipelines de dados e aplicações com o Apache Spark usando Python e Scala. Queríamos uma solução personalizada que simplificasse as operações e fosse entregue com mais rapidez e eficiência para nossos clientes, e é isso que obtemos com o novo Amazon Redshift Integration for Apache Spark.”
Alcuin Weidus, arquiteto de dados sênior, GE Aerospace
A GE Aerospace é uma fornecedora global de motores a jato, componentes e sistemas para aeronaves comerciais e militares. A empresa projeta, desenvolve e fabrica motores a jato desde a Primeira Guerra Mundial.
“A GE Aerospace usa análises da AWS e o Amazon Redshift para possibilitar insights de negócios críticos que impulsionam importantes decisões de negócios. Com o suporte à cópia automática do Amazon S3, podemos criar pipelines de dados mais simples para mover dados do Amazon S3 para o Amazon Redshift. Isso aumenta a capacidade de nossas equipes de produtos de dados de acessar dados e fornecer informações aos usuários finais. Gastamos mais tempo agregando valor por meio de dados e menos tempo em integrações.”
Neema Raphael, diretor de processamento de dados, Goldman Sachs
O Goldman Sachs Group, Inc. é uma instituição financeira global líder que oferece uma ampla gama de serviços financeiros em banco de investimento, valores mobiliários, gerenciamento de investimentos e banco de consumo para uma base de clientes grande e diversificada que inclui corporações, instituições financeiras, governos e indivíduos.
“Nosso foco é fornecer acesso de autoatendimento aos dados para todos os usuários do Goldman Sachs. Por meio do Legend, nossa plataforma de gerenciamento e governança de dados de código aberto, permitimos que os usuários desenvolvam aplicações centradas em dados e obtenham insights orientados por dados à medida que colaboramos em todo o setor de serviços financeiros. Com a Integração do Amazon Redshift para Apache Spark, nossa equipe de plataforma de dados poderá acessar os dados do Amazon Redshift com o mínimo de etapas manuais, permitindo ETL de código zero que aumentará nossa capacidade de tornar mais fácil para os engenheiros se concentrarem em aperfeiçoar seu fluxo de trabalho à medida que eles coletam informações completas de forma ágil. Esperamos ver uma melhoria na performance das aplicações e segurança aprimorada, pois nossos usuários agora podem acessar facilmente os dados mais recentes no Amazon Redshift.”
Recursos
Você encontrou o que estava procurando hoje?
Informe-nos para que possamos melhorar a qualidade do conteúdo em nossas páginas