背景
根據 Knowledge Bases for Amazon Bedrock(以下簡稱 Knowledge Base)文件 [1] 的說明:「每次您在 data source 的 S3 中新增、修改或刪除檔案時,您必須同步該 data source,使其在 Knowledge Base 中重新建立 index。同步是累加的,因此 Amazon Bedrock 僅會處理自上次同步後新增、修改或刪除的物件。」
本篇文章的目的便是為了驗證並觀察在 Knowledge Base 中新增、刪除或修改檔案時 vector database 的變化。
測試案例
全部開啟- 編輯 data source 中的其中一個檔案 ( 只修改檔案中的一個單字 )
- 編輯 data source 中的其中一個檔案 ( 修改檔案中的一筆資料 )
- 刪除 Knowledge Base 中的一個 data source
- 刪除 data source 中的一個檔案
- 覆蓋一個檔案而不修改其內容
- 在 data source 中新增一個新檔案
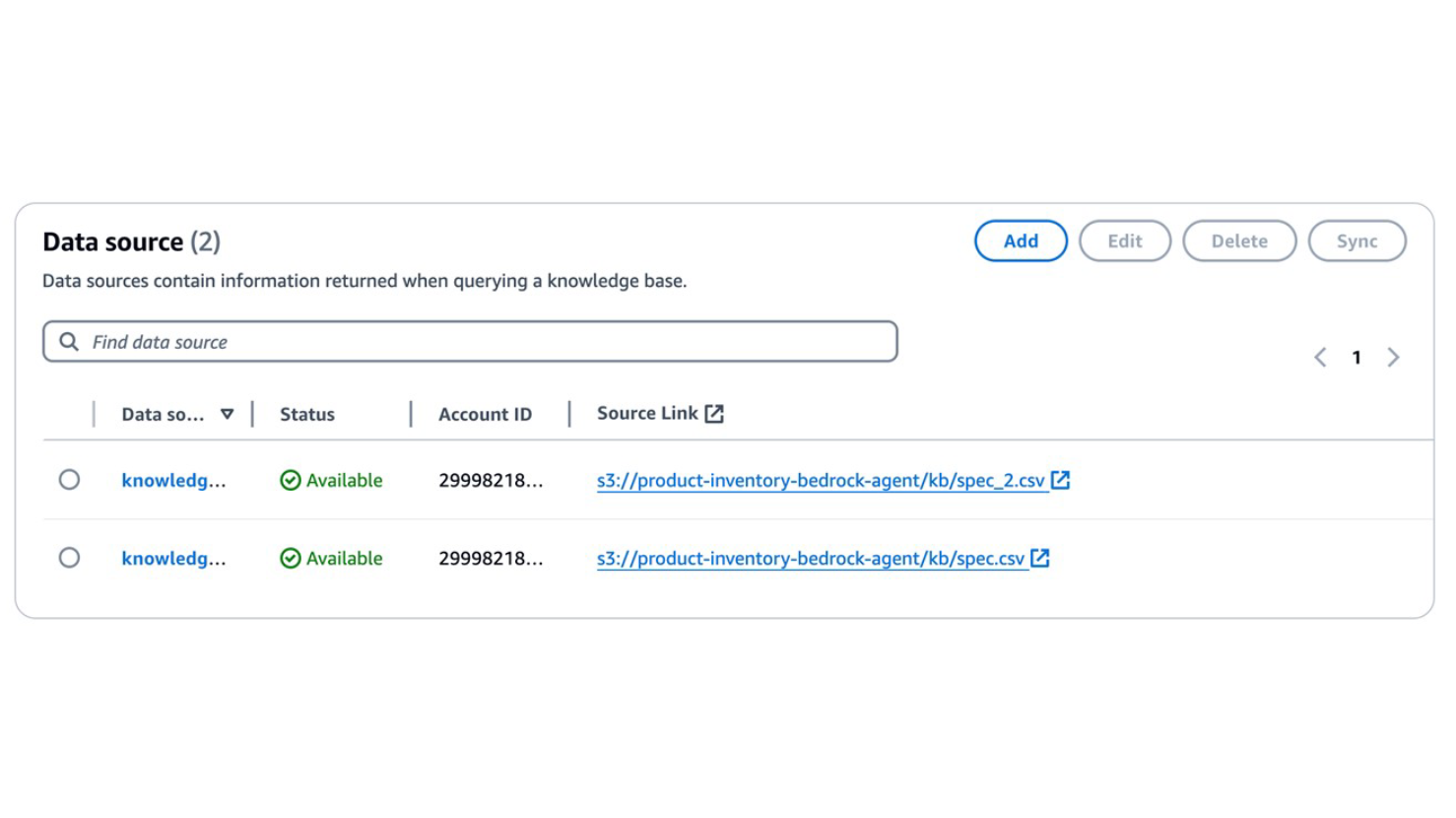
目前 Knowledge Bases for Amazon Bedrock 的 Data Source
測試一
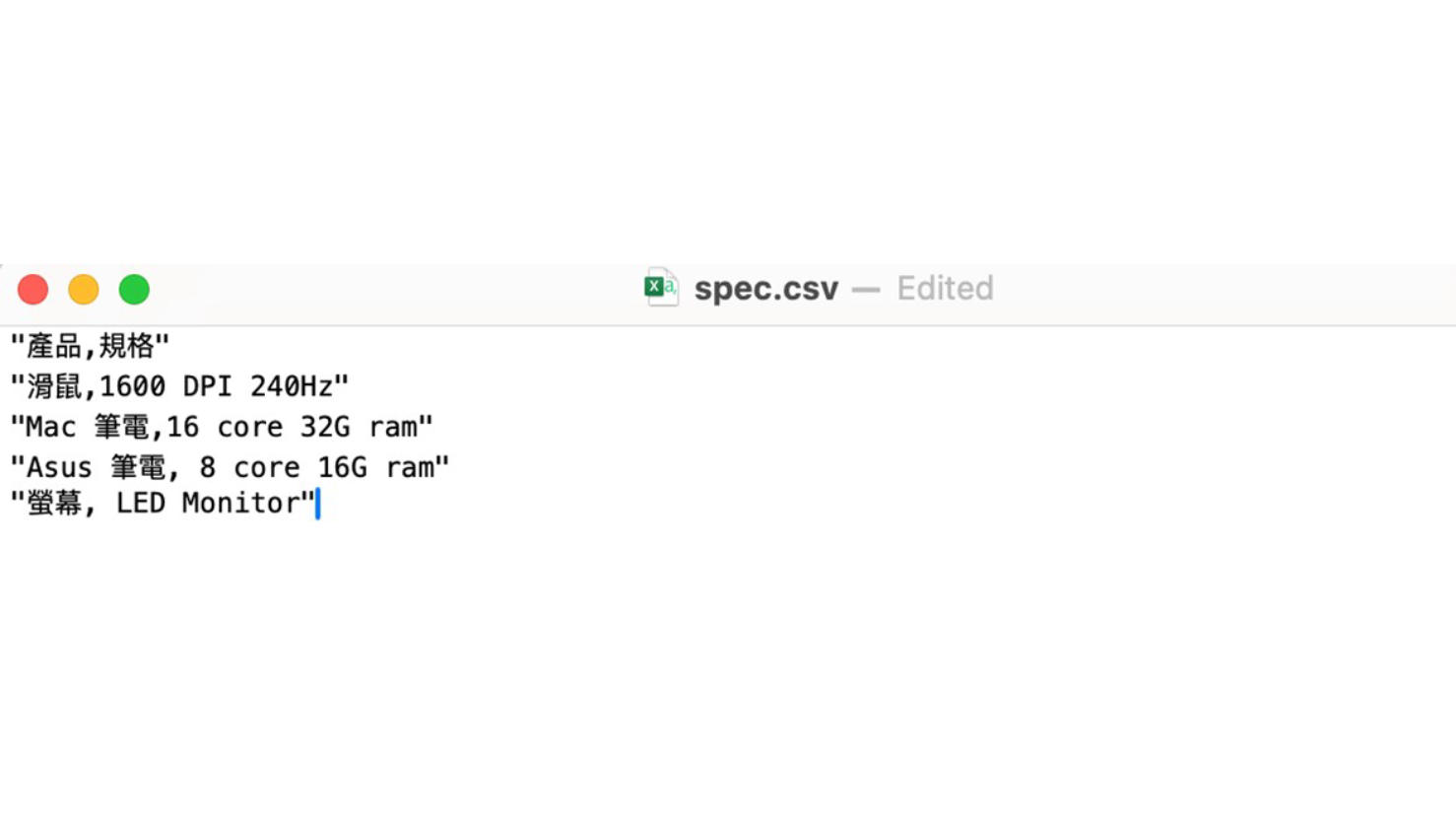
全部開啟修改 “spec.csv” 文件中的 "Acer" 為 "Mac",並重新 sync data source。
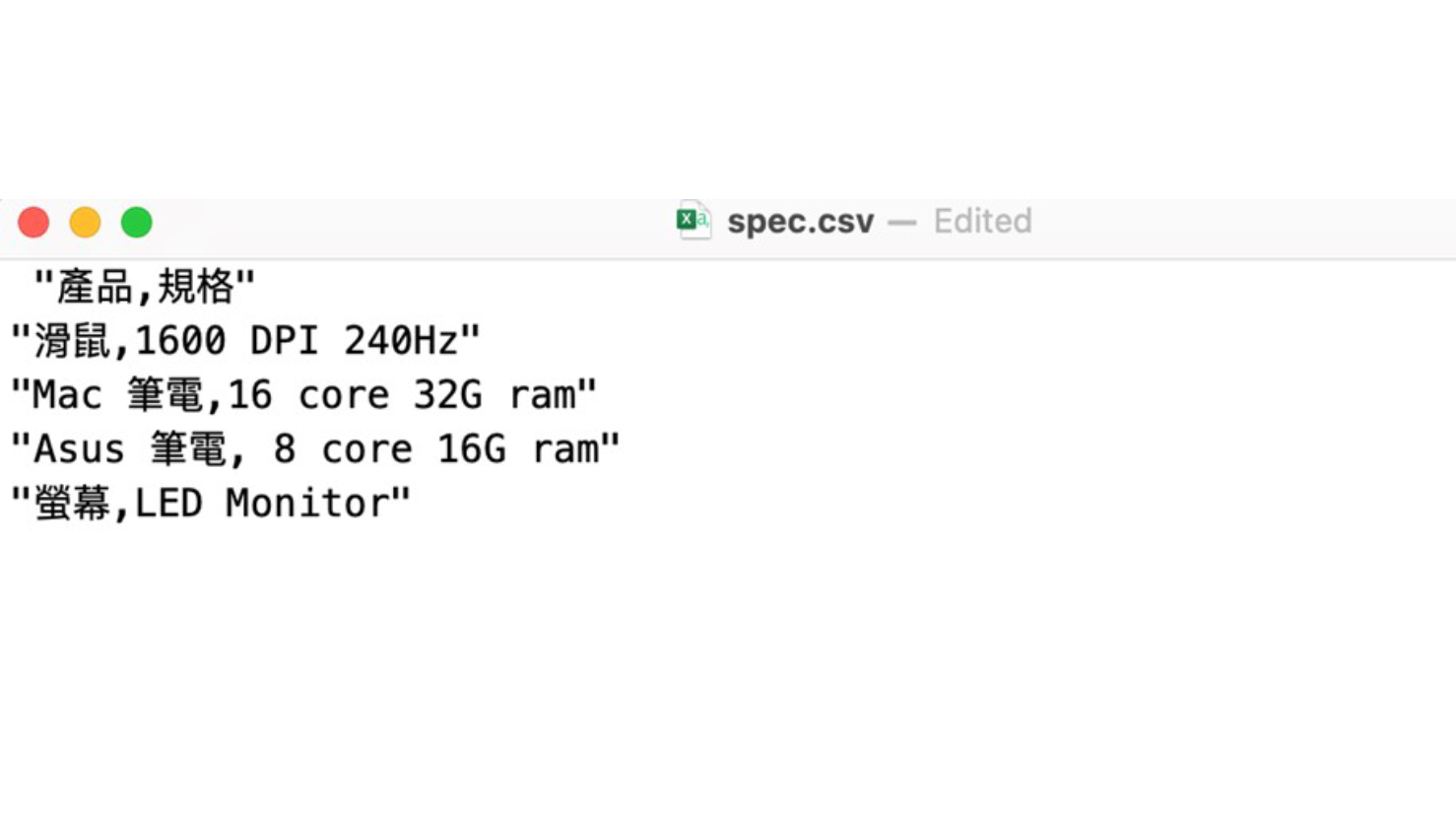
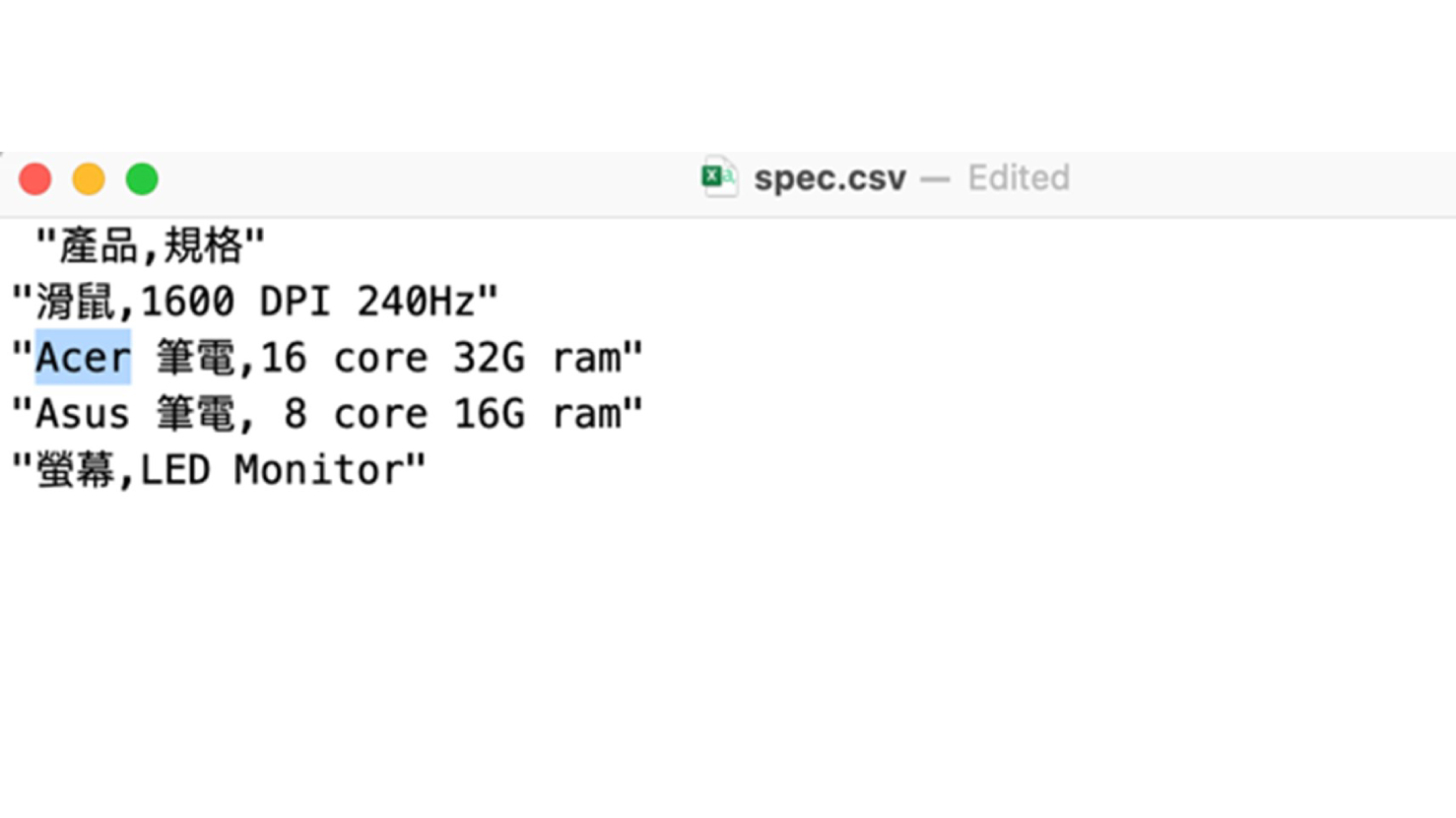
編輯檔案後:
我們使用 Visual Studio Code 來比較 Knowledge Bases for Amazon Bedrock 在修改資料前後所產生的 vector index。
在我們修改 "spec.csv" 之前,vector index 的內容可以參考 "spec_1_origin.json"。
在我們修改 "spec.csv" 之後,vector index 的內容可以參考 "spec_1_edit_a_word.json"。
藉由此測試,我們可以看到即使我們只修改其中的一個單詞,vector database 也重新生成了整個 vector index,包括 "id" 和 "bedrock-knowledge-base-default-vector"。
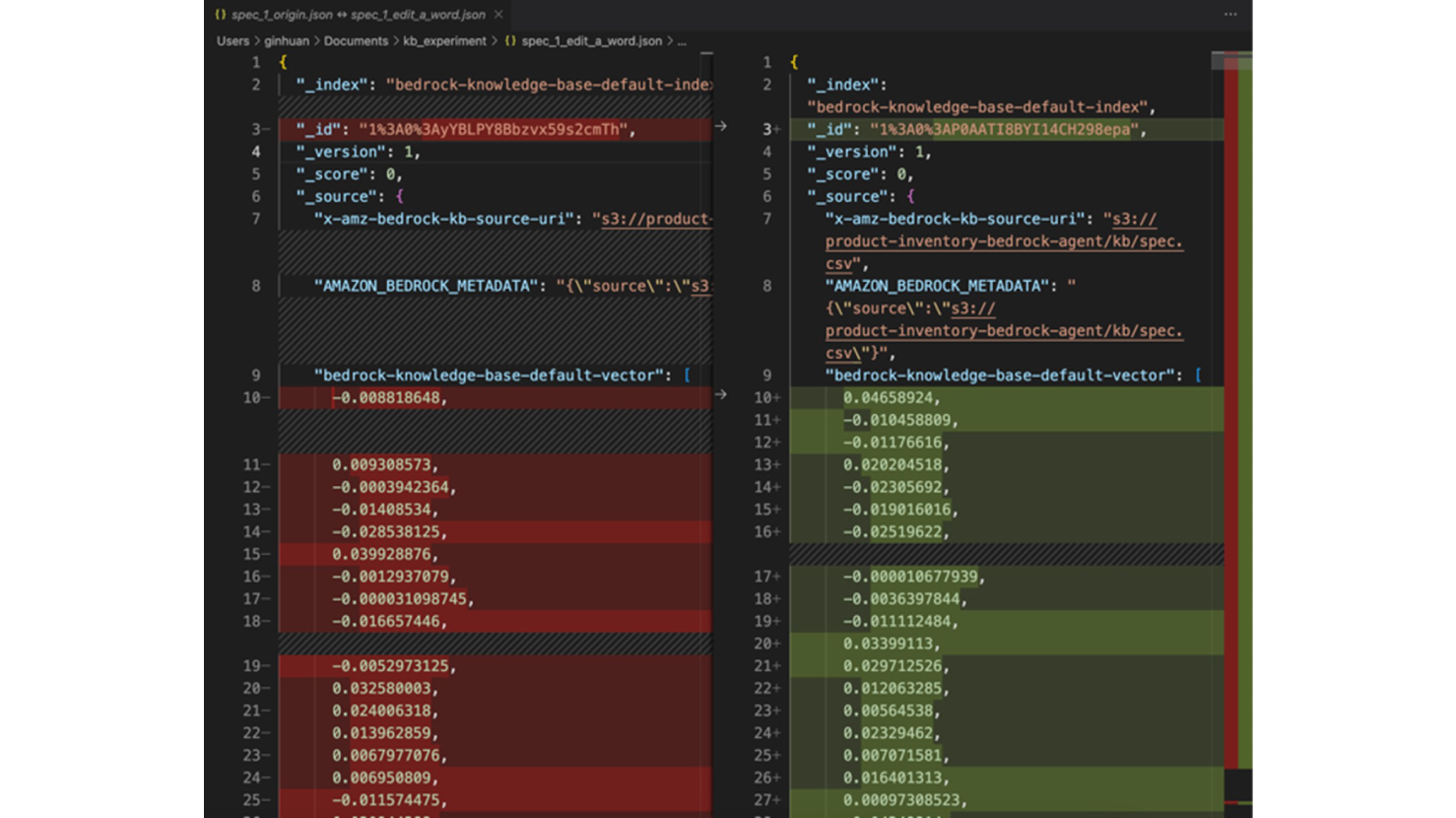
左側為 "spec_1_origin.json" / 右側為 "spec_1_edit_a_word.json"
測試二
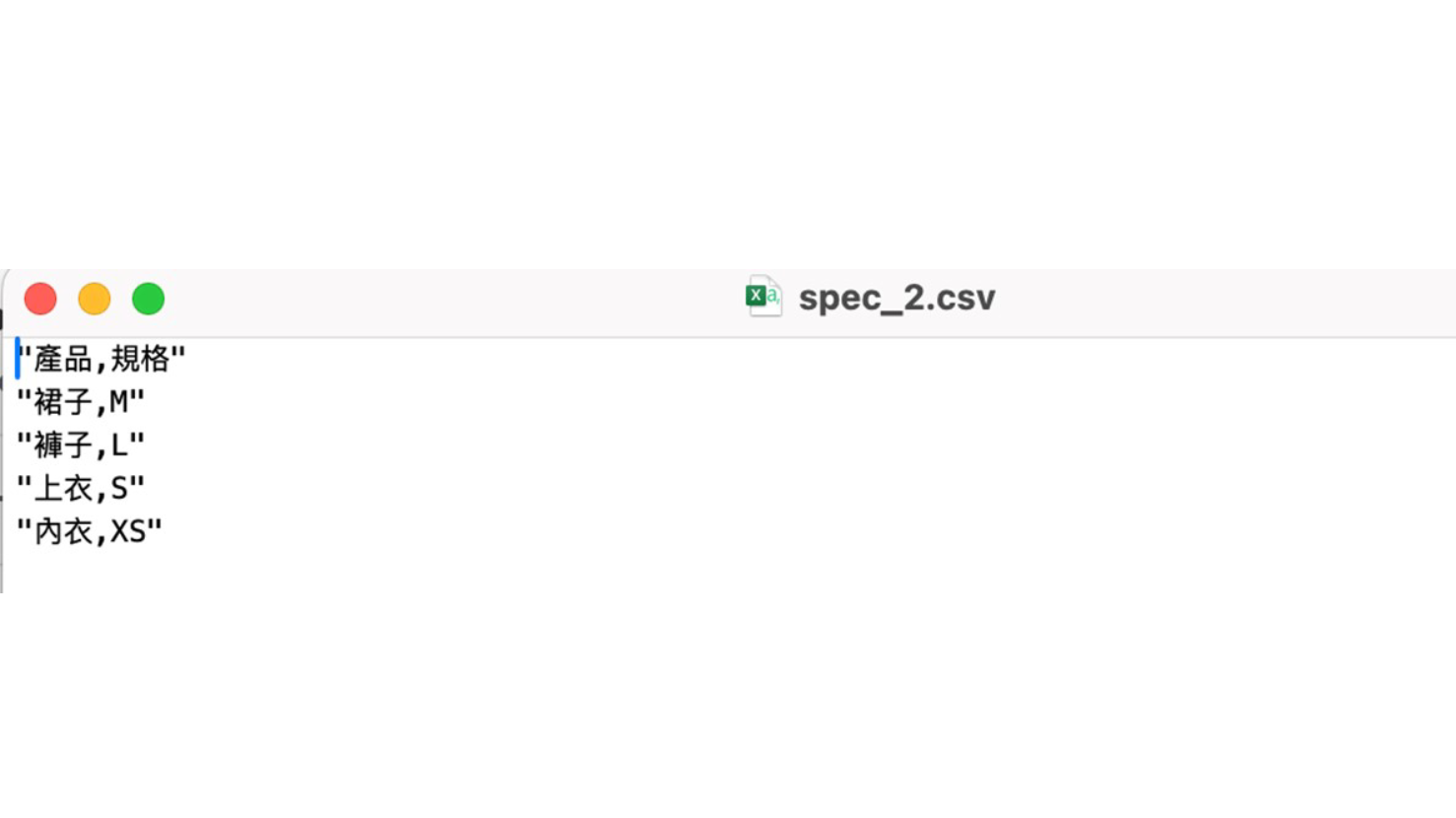
全部開啟修改 "spec.csv" 中的一筆資料,即刪除 "螢幕, LED Monitor" 這一筆資料,並重新在 Knowledge Bases for Amazon Bedrock 中 sync data source。
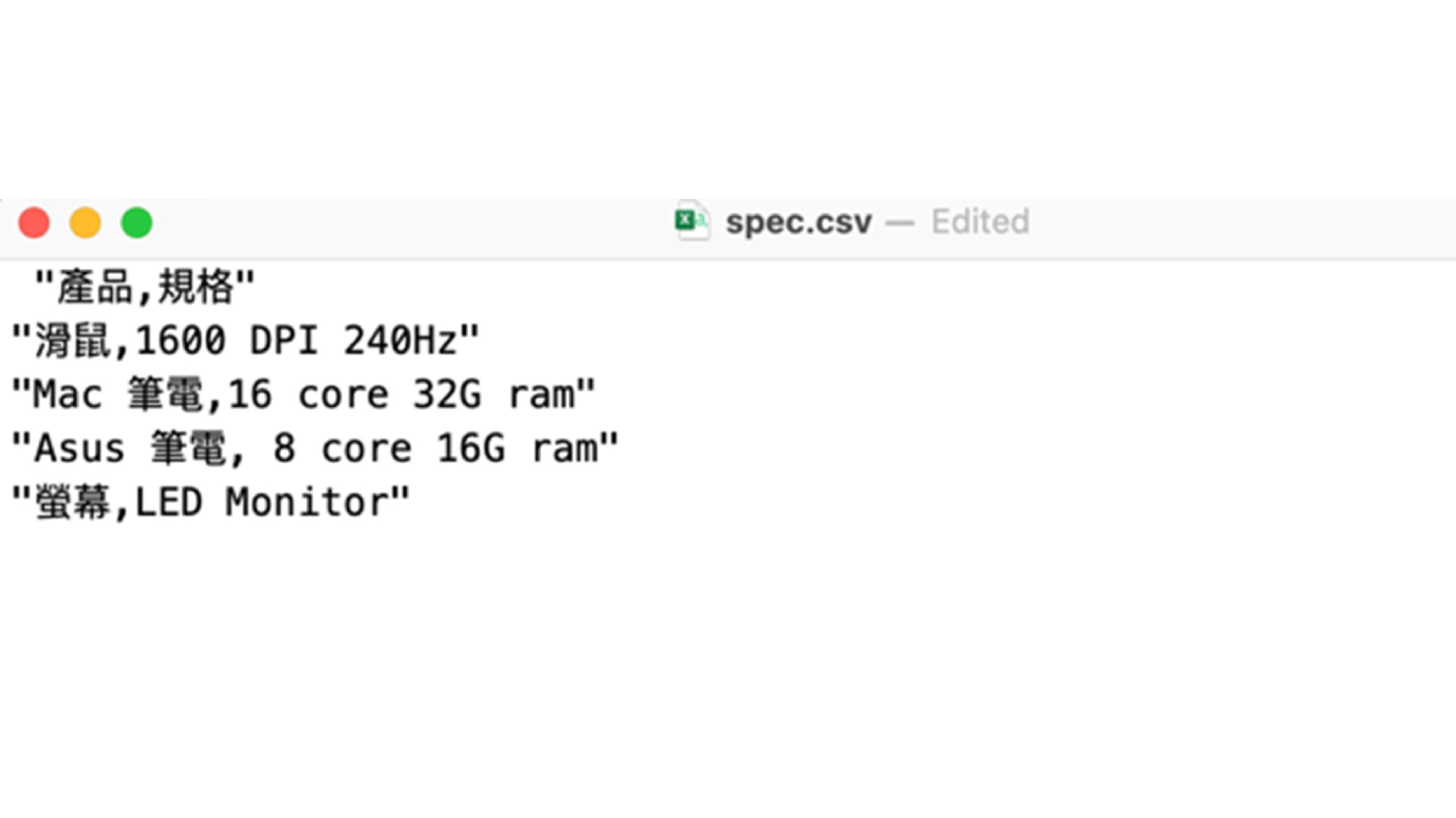

編輯後:
我們使用 Visual Studio Code 比較修改數據前後 Knowledge Bases for Amazon Bedrock 生成的索引。
在我們修改 "spec.csv" 之前,vector index 的內容可以參考 "spec_1_edit_a_word.json"。
在我們修改 "spec.csv" 之後,vector index 的內容可以參考 "spec_1_edit_a_row.json"。
藉由此測試,我們可以看到即使只刪除文件中的一筆資料,vector database 也重新生成了整個 vector index,包括 "id" 和 "bedrock-knowledge-base-default-vector"。
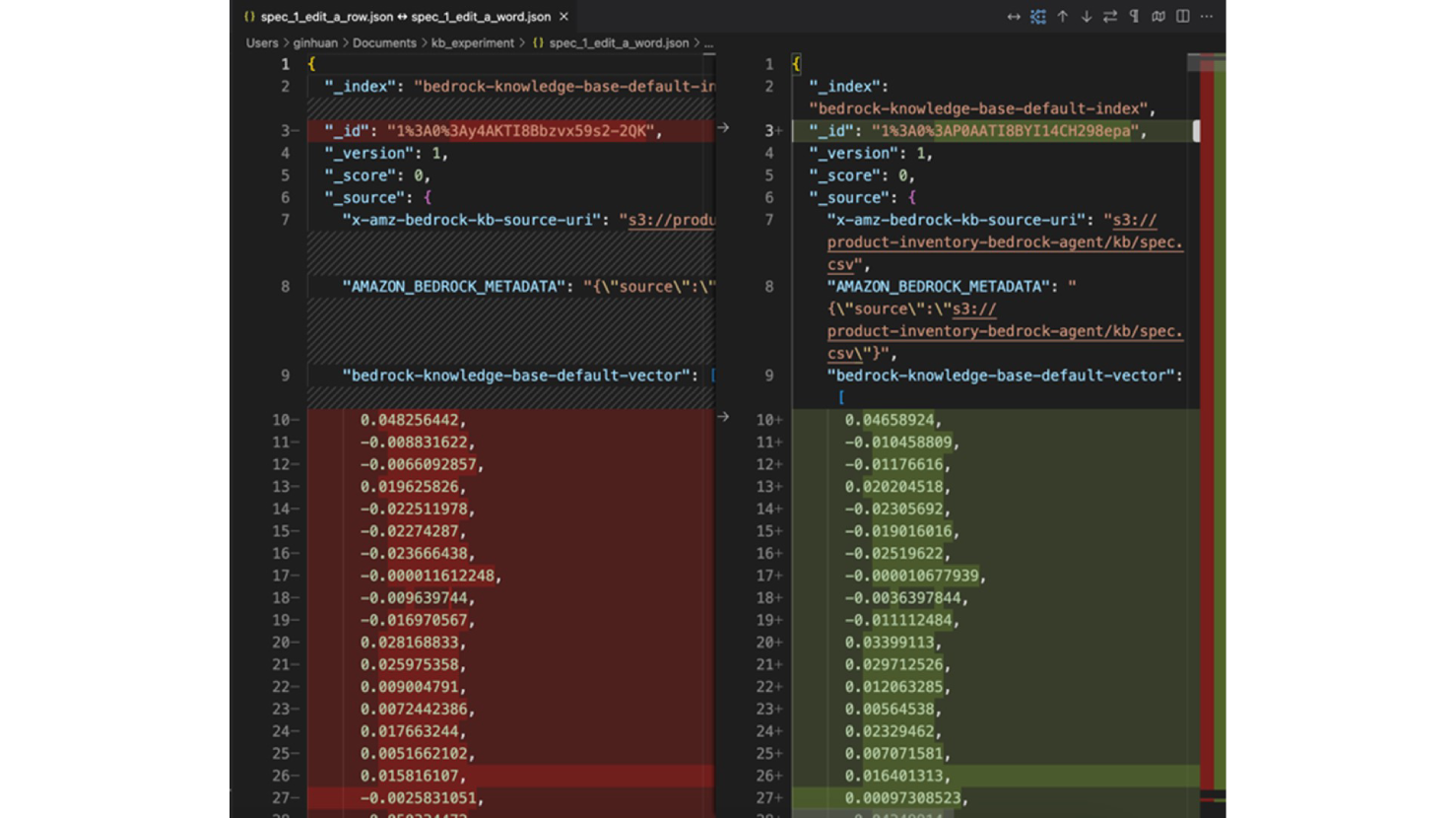
左側為 "spec_1_edit_a_row.json"/ 右側為 "spec_1_edit_a_word.json
結論
全部開啟經過以上六個測驗,我們可以證明在 sync data source 之後,Knowledge Bases for Amazon Bedrock 只會處理在 S3 中被新增、刪除或修改的物件。此外,一旦某個文件被修改過,該文件的 vector index 會在 vector database 中被重新生成。
|
測試案例 |
測試結果 |
|
編輯 data source 中的其中一個檔案
|
Knowledge Base 重新生成該檔案的 vector index 在 vector database 中 其餘的 vector index 則維持原狀 |
|
編輯 data source 中的其中一個檔案
|
Knowledge Base 重新生成該檔案的 vector index 在 vector database 中 其餘的 vector index 則維持原狀 |
|
刪除 Knowledge Base 中的一個 data source |
[ 勾選 “Delete underlying vector data” ] Knowledge Base 刪除該 data source 在 vector database 的 vector index 其餘的 vector index 則維持原狀 |
|
[ 不勾選 “Delete underlying vector data” ] 不會刪除該 data source 在 vector database 的 vector index,所有的 vector index 維持原狀 |
|
|
刪除 data source 中的一個檔案 |
Knowledge Base 刪除該 data source 在 vector database 的 vector index 其餘的 vector index 則維持原狀 |
|
覆蓋一個檔案而不修改其內容 |
Vector index 維持原狀 |
|
在 data source 中新增一個新檔案 |
Knowledge Base 新增該檔案的 vector index 在 vector database 中 其餘的 vector index 則維持原狀 |
作者資訊
Ginny Huang, Associate Solutions Architect Intern, AWS
Ginny Huang 目前任職於台灣 AWS 的解決方案架構師部門擔任實習生。對生成式 AI 解決方案充滿熱情,並致力於了解客戶需求並協助客戶設計解決方案。

Ting-Yao Chang, Solutions Architect, AWS
Ting-Yao Chang 是任職於台灣 AWS 的解決方案架構師,擅長了解客戶需求並設計架構,服務過許多大型企業;近期致力於生成式 AI 技術,協助客戶探索使用情境並提供解決方案建議。
