Amazon SageMaker HyperPod 功能
擴展和加速跨數千種 AI 加速器的生成式 AI 模型開發作業
無檢查點訓練
在 Amazon SageMaker HyperPod 上進行無檢查點訓練,無須手動干預的情況下,幾分鐘內即可從基礎結構故障中自動復原。該服務無須進行以檢查點為基礎的任務層級重新啟動,來進行故障復原,而這項任務需要暫停整個叢集、修復問題,以及透過儲存的檢查點進行復原。由於 SageMaker HyperPod 可自動交換故障元件,以及透過運作狀態良好 AI 加速器,利用模型對等傳輸與最佳化程式狀態來復原訓練,儘管出現故障,檢查點訓練仍可確保朝向目標取得進展。該服務還可在配備數千個 AI 加速器的叢集上,支援 95% 以上的實際訓練輸送量。 藉助無檢查點訓練,可節省數百萬的運算費用,將訓練擴展至數千個 AI 加速器,以及加速在生產中運用您的模型。
彈性訓練
在 Amazon SageMaker HyperPod 上進行彈性訓練,可依據運算資源的可用性來自動擴展訓練任務,從而每週節省數小時之前花費在重新設定訓練任務上的工程時間。隨著推論工作負載依據流量模式擴展,對 AI 加速器的需求會持續波動,完成的試驗可釋放資源,並且新的訓練任務會改變工作負載優先級。SageMaker HyperPod 可動態擴展執行中的訓練任務,以便吸收閒置的 AI 加速器,從而最大化基礎結構使用率。若推論或評估等較高優先級的工作負載需要資源,訓練將縮減規模,以較少資源繼續,而不完全停止,從而依據透過任務治理政策建立的優先級來產生必要的容量。彈性訓練有助於加速 AI 模型開發,同時減少因運算運算不足而導致的成本超額。
任務治理
靈活的訓練方案
Amazon SageMaker HyperPod Spot 執行個體
使用 SageMaker HyperPod 上的 Spot 執行個體,您能夠以顯著幅降低的成本來存取運算容量。Spot 執行個體非常適合批次推論任務等容錯型工作負載。價格因區域與執行個體類型而有所差異,相較於 SageMaker HyperPod 隨需定價,通常可提供最高 90% 的折扣。Spot 執行個體的價格由 Amazon EC2 制定,然後根據 Spot 執行個體容量的長期供需趨勢逐漸調整。在您的執行個體執行的這段時間,您將按 Spot 價格付費,無須預先簽訂合約。如需進一步了解估算的 Spot 執行個體價格及執行個體可用性,請造訪 EC2 Spot Instances 定價頁面。請注意,僅在 HyperPod 上同樣受到支援的執行個體,才會在 HyperPod 上提供 Spot 用量。
自訂模型的最佳化配方
藉助 SageMaker HyperPod 配方,各種技能組合的資料科學家和開發人員可從最先進的效能獲益,並能快速開始訓練和微調公開可用的基礎模型,包括 Llama、Mixtral、Mistral 和 DeepSeek 模型。此外,您還可以使用一套技術來自訂包括 Nova Micro、Nova Lite 和 Nova Pro 在內的 Amazon Nova 模型,這套技術包括監督微調 (SFT)、知識蒸餾、直接偏好最佳化 (DPO)、近距政策最佳化和持續預先訓練,並支持 SFT、蒸餾和 DPO 的參數效率和全模型訓練選項。每個配方都包含 AWS 測試的訓練堆疊,省去為期數週測試不同模型組態的繁瑣工作。您也可以透過一行配方變更,切換以 GPU 為基礎的執行個體和以 AWS Trainium 為基礎的執行個體,並啟用自動化模型檢查點,以改善訓練恢復能力,並在 SageMaker HyperPod 上執行生產環境中的工作負載。
Amazon Nova Forge 是一款史無前例的計劃,它為組織提供了使用 Nova 來建立自己的前沿模型的最簡單和最具成本效益的方法。透過 Nova 模型的中間檢查點來存取及訓練,在訓練期間混合 Amazon 的經策管資料集與專屬資料,以及使用 SageMaker HyperPod 配方來訓練您自己的模型。藉助 Nova Forge,您可使用自己的業務資料,依據您的各項任務來解鎖使用案例特定智慧與價格效能改善功能。
高效能分散式訓練
進階可觀測性和實驗工具
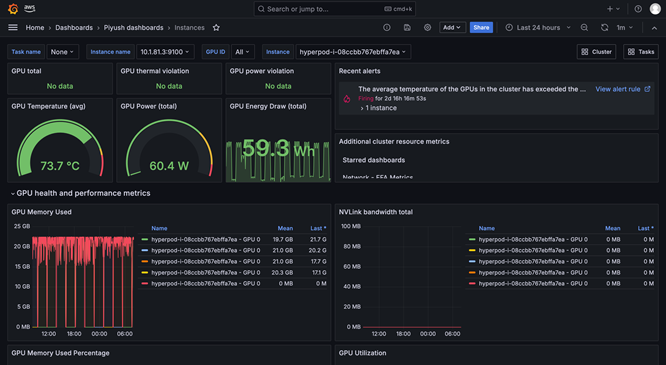
SageMaker HyperPod 可觀測性提供了在 Amazon Managed Grafana 中預先設定的統一儀表板,同時監控資料會自動發佈到 Amazon Managed Prometheus 工作區。您可以在單一檢視中查看即時效能指標、資源使用率和叢集運作狀態,從而讓團隊能夠快速發現瓶頸、防止代價高昂的延遲以及最佳化運算資源。SageMaker HyperPod 亦可與 Amazon CloudWatch Container Insights 整合,從而提供有關叢集效能、運作狀態和使用率的深入洞察。SageMaker 中的受管 TensorBoard 可協助您透過視覺化模型架構來識別和修正融合問題,進而節省開發時間。SageMaker 中的受管 MLflow 可協助您有效率地管理大規模實驗。
工作負載排程和協同運作
自動叢集運作狀態檢查和修復
加速 SageMaker Jumpstart 的開放式權重模型部署
SageMaker HyperPod 可自動簡化 SageMaker JumpStart 的開放式權重基礎模型部署,以及 Amazon S3 和 Amazon FSx 的經微調的模型。SageMaker HyperPod 會自動佈建所需的基礎架構並設定端點,因此無需手動佈建。藉助 SageMaker HyperPod 任務治理,可持續監控端點流量並動態調整運算資源,同時將綜合效能指標發布到可觀測性儀表板,從而實現即時監控和最佳化。
受管分層檢查點
SageMaker HyperPod 受管分層檢查點利用 CPU 記憶體儲存頻繁的檢查點進行快速復原,同時定期將資料保存至 Amazon Simple Storage Service (Amazon S3) 以獲得長期耐用性。這種混合方法可最大程度地減少訓練損失,並大幅縮短故障後恢復訓練的時間。客戶可在記憶體內和持久性儲存層中,設定檢查點頻率和保留政策。透過經常在記憶體中儲存檢查點,客戶能夠在降低儲存成本的情況下快速復原。受管分層檢查點與 PyTorch 的分散式檢查點 (DCP) 整合,客戶只需幾行程式碼即可輕鬆實作檢查點,同時享受記憶體內儲存的效能優勢。
透過 GPU 分割最大化資源使用率
藉助 SageMaker HyperPod,管理員能夠將 GPU 資源分割為較小的、隔離式運算單元,以便最大化 GPU 使用率。您可在單一 GPU 上執行各種生成式 AI 任務,並非全部 GPU 專門用於只需小部分資源的任務。透過跨 GPU 分割區監控即時效能指標與資源使用率,您可深入洞察任務使用運算資源的方式。憑藉此最佳化配置以及簡化的設定,能夠加速生成式 AI 開發,改善 GPU 使用率,以及在大規模任務中實現高效的 GPU 資源使用。
找到今天所需的資訊了嗎?
讓我們知道,以便我們改善頁面內容的品質