- Amazon Redshift›
- Возможности›
- Интеграция с Apache Spark
Интеграция Amazon Redshift для Apache Spark
Создание приложений Apache Spark с чтением и записью данных из Amazon Redshift
Почему стоит выбрать интеграцию Amazon Redshift для Apache Spark?
Преимущества Amazon Redshift
-
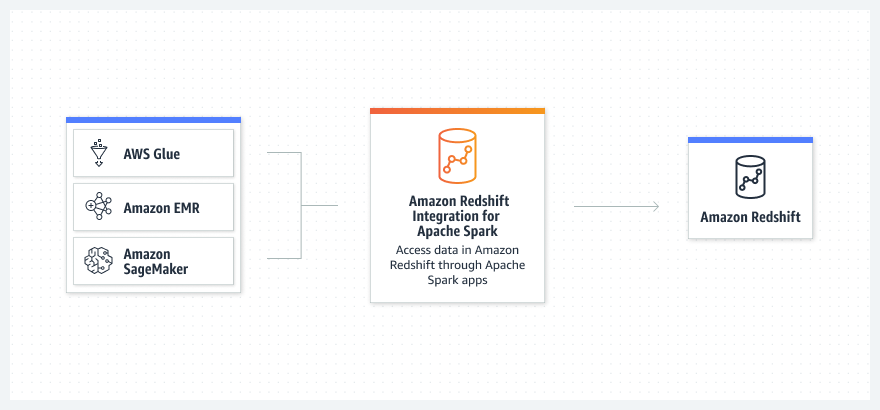
Расширьте диапазон источников данных, которые можно использовать в своих приложениях глубокой аналитики и машинного обучения, работающих в Amazon EMR, AWS Glue или SageMaker, путем чтения и записи данных в хранилище данных.
-
Оптимизируйте громоздкий и зачастую ручной процесс настройки несертифицированных соединителей и драйверов JDBC, сократив время подготовки задач аналитики и машинного обучения.
-
Используйте возможности pushdown-оптимизации, такие как функции сортировки, агрегирования, ограничения, объединения и скалярные функции, чтобы из хранилища данных Amazon Redshift передавались только значимые данные.
Как это работает
Примеры использования
-
Создавайте приложения Apache Spark на Java, Scala и Python с помощью аналитических сервисов AWS на основе Apache Spark.
-
Считывайте и записывайте данные в Amazon Redshift с помощью Amazon EMR, AWS Glue и SageMaker, а также сервисов AWS для аналитики и машинного обучения.
-
Используйте Amazon EMR или AWS Glue для получения кода кадра данных из задания или записной книжки Apache Spark и подключения к Amazon Redshift.
-
Оптимизируйте процессы благодаря отсутствию настройки и тестирования, повышенной безопасности (учетные данные IAM), pushdown-оптимизации операций и файлу формата PARQUET для повышения производительности.
Клиенты
Кори Джонсон, менеджер по архитектуре данных Huron Consulting
Huron — это международная фирма, которая оказывает квалифицированные услуги по реализации на практике надежных стратегий, оптимизации операций, ускорению цифровой трансформации и подготовке компаний и их сотрудников к будущему.
«Мы даем нашим инженерам возможность создавать конвейеры данных и приложения с помощью Apache Spark с использованием Python и Scala. Нам нужно было специализированное решение, которое бы упростило операции и обеспечило более быструю и эффективную доставку клиентам — и именно это мы получили с новой интеграцией Amazon Redshift для Apache Spark.»
Алкуин Вейдус, старший директор по архитектуре данных GE Aerospace
GE Aerospace — это международный поставщик реактивных двигателей, компонентов и систем для коммерческих и военных самолетов. Эта компания занимается проектированием, разработкой и производством реактивных двигателей со времен Первой мировой войны.
«GE Aerospace использует аналитику AWS и Amazon Redshift, для получения ключевых бизнес-данных, которые помогают принимать важные бизнес-решения. Благодаря поддержке автоматического копирования Amazon S3 мы можем создавать более простые конвейеры данных для перемещения данных из Amazon S3 в Amazon Redshift. Это повышает возможности наших специалистов по продуктам для работы с данными в отношении доступа к данным и предоставления информации конечным пользователям. Мы тратим больше времени на добавление ценности с помощью данных и меньше времени на интеграцию.»
Нима Рафаэль, директор по обработке и анализу данных Goldman Sachs
The Goldman Sachs Group, Inc. — ведущая мировая финансовая организация, предоставляющая широкий спектр финансовых услуг в области инвестиционно-банковских услуг, ценных бумаг, управления инвестициями и потребительских банковских услуг большой и диверсифицированной клиентской базе, в которую входят корпорации, финансовые учреждения, правительства и частные лица.
«В Goldman Sachs мы сосредоточены на предоставлении доступа к данным в режиме самообслуживания для всех наших пользователей. С помощью Legend, нашей платформы для руководства и управления данными с открытым исходным кодом, мы даем пользователям возможность разрабатывать приложения, ориентированные на данные, и получать аналитику на основе данных в ходе нашего сотрудничества в сфере финансовых услуг. Благодаря интеграции Amazon Redshift для Apache Spark наша команда по платформам данных сможет получать доступ к данным Amazon Redshift с минимальным количеством ручных действий, что позволит использовать операции извлечение-преобразование-загрузка без написания кода. Это позволит инженерам уделять больше внимания совершенствованию рабочих процессов, получая при этом полную и актуальную информацию. Мы ожидаем повышения производительности приложений и повышения безопасности, поскольку теперь наши пользователи могут легко получать доступ к самым свежим данным в Amazon Redshift.»
Ресурсы
Нашли то, что искали сегодня?
Скажите, как улучшить качество контента на наших страницах