概觀
Well-Architected 支柱
上方的架構圖是一個考量到 Well-Architected 最佳實務而建立的的解決方案的範例。若要完全實現 Well-Architected,您應該盡可能地多遵循 Well-Architected 的最佳實務。
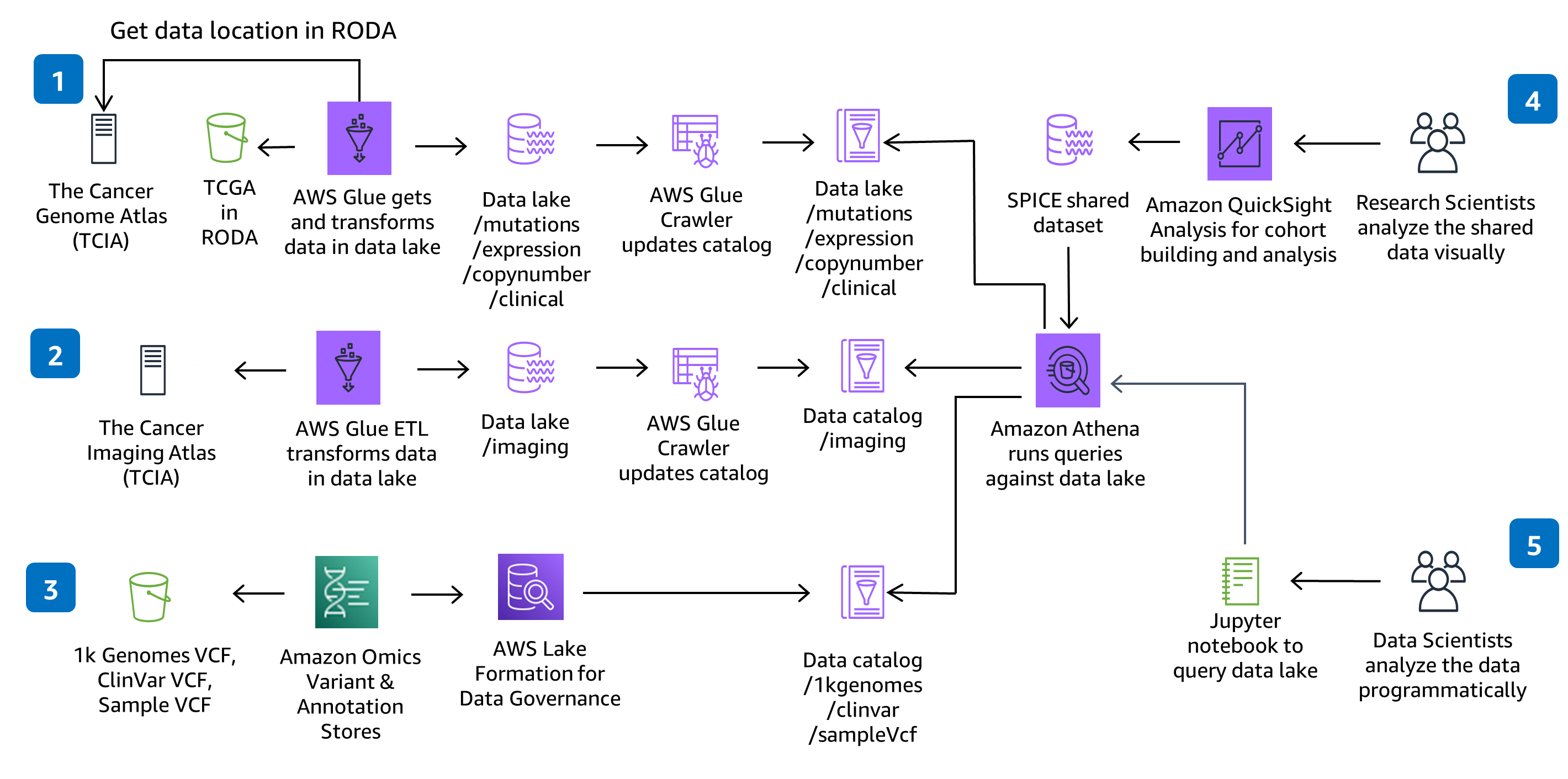
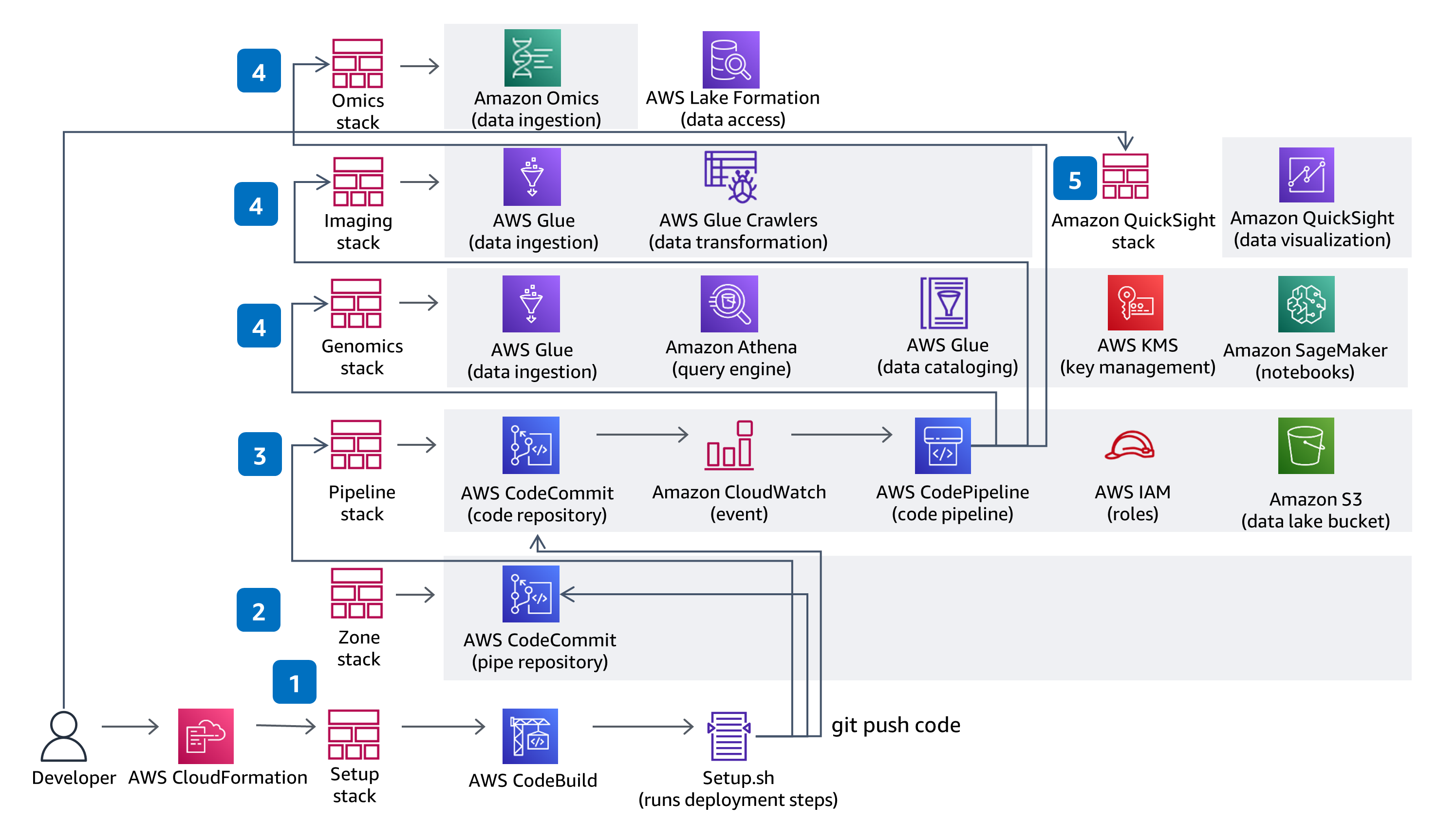
本指引使用 CodeBuild 和 CodePipeline 來建置、封裝和部署解決方案中所需的一切內容,以擷取和儲存變體呼叫檔案 (VCF),並搭配使用 The Cancer Genome Atlas (TCGA) 和 The Cancer Imaging Atlas (TCIA) 資料集中的多模態和多組學資料。使用全受管的服務 – Amazon Omics 展現了無伺服器基因體資料擷取和分析。在解決方案 CodeCommit 儲存庫中做出的程式碼變更,將透過提供的 CodePipeline 部署管道進行部署。
本指引使用包含 IAM 的角色型存取,並且所有儲存貯體均已啟用加密、均為私有且封鎖公有存取。AWS Glue 中的資料型錄均已啟用加密,並且 由 AWS Glue 寫入 Amazon S3 的所有中繼資料均已加密。所有角色均以最低權限定義,且服務之間的所有通訊均保留在客戶帳戶中。管理員可控制 Jupyter 筆記本、Amazon Omics Variant Stores 的資料,AWS Glue 型錄資料存取權使用 Lake Formation 進行完全管理,而 Athena、SageMaker Notebook 和 QuickSight 資料存取權透過提供的 IAM 角色進行管理。
AWS Glue、Amazon S3、Amazon Omics 和 Athena 均為無伺服器,並且會隨著資料量的增加而擴展資料存取效能。AWS Glue 會佈建、設定和擴展執行資料整合任務所需的資源。Athena 是無伺服器的,所以您可以快速查詢資料,而無需設定和管理任何伺服器或資料倉儲。QuickSight SPICE 記憶體儲存將您的資料探索擴展至數千名使用者。
透過使用無伺服器技術,您只需佈建您使用的確切資源。每項 AWS Glue 任務將隨需佈建 Spark 叢集以轉換資料,並在完成後取消佈建資源。如果您選擇新增 TCGA 資料集,則可以新增 AWS Glue 任務和 AWS Glue 編目程式,這也會隨需佈建資源。Athena 會自動平行執行查詢,因此大部分的結果都可在幾秒鐘內傳回。 Amazon Omics 透過將檔案轉換為 Apache Parquet 來大規模最佳化變體查詢效能。
透過使用隨需擴展的無伺服器技術,您只需依使用的資源付費。為進一步最佳化成本,您可以在不使用筆記本環境時,在 SageMaker 中將其停止。QuickSight 儀表板也透過單獨的 CloudFormation 範本進行部署,因此如果您不打算使用視覺化儀表板,可以選擇不部署以節省成本。 Amazon Omics 大規模最佳化變體資料儲存成本。查詢成本由 Athena 掃描的資料量決定,可以透過據以編寫查詢來最佳化。
透過廣泛使用受管服務和動態擴展,您可以最大限度地減少後端服務對環境的影響。永續發展的一個關鍵組成部分是最大限度地利用筆記本伺服器執行個體。您應在不使用筆記本環境時將其停止。
其他注意事項
資料轉換
此架構選擇使用 AWS Glue 獲取所需的擷取、轉換和載入 (ETL) 功能,以擷取、準備和編目解決方案中的資料集,來實現查詢和效能。您可以視需新增 AWS Glue 任務和 AWS Glue 編目程式,以擷取新的 The Cancer Genome Atlas (TCGA) 和 The Cancer Image Atlas (TCIA) 資料集。您還可以新增任務和爬蟲程式,來擷取、準備和編目您自己的專有資料集。
資料分析
此架構選擇使用 SageMaker 筆記本,來提供 Jupyter 筆記本環境進行分析。您可以將新的筆記本新增至現有環境或建立新環境。如果您更喜歡 RStudio 而不是 Jupyter 筆記本,則可以使用 RStudio on Amazon SageMaker。
資料視覺化
此架構選擇使用 QuickSight 來提供互動式儀表板,以進行資料視覺化和探索。QuickSight 儀表板透過單獨的 CloudFormation 範本設定,因此,如果您不打算使用儀表板,則不必對其進行佈建。在 QuickSight 中,您可以建立自己的分析、探索其他篩選條件或視覺化,並與同事共用資料集和分析。
充滿信心地進行部署
此儲存庫在 AWS 中建立了一個可擴展環境,以準備用於大規模分析的基因體、臨床、突變、表現和影像資料,並針對資料湖執行互動式查詢。該解決方案示範了以下操作方法︰1) 使用 HealthOmics Variant Store & Annotation Store 儲存基因體變異資料和註釋資料,2) 針對多模態資料準備和編目佈建無伺服器資料擷取管道,3) 透過互動式介面來視覺化和探索臨床資料,以及 4 ) 使用 Amazon Athena 和 Amazon SageMaker 針對多模態資料湖執行互動式分析查詢。
提供了詳細的指南,以在您的 AWS 帳戶中實驗和使用。建立指南的每個階段 (包括部署、使用和清理) 都經過檢查以準備部署。
範本程式碼是一個起點。它經過產業驗證、具規範性但非最終定論,還可讓您一窺底層實作細節,協助您著手進行。
相關內容
指引
在 AWS 上運用健康 AI 和 ML 服務的多模式資料分析指引
本指引示範如何設定端對端架構,以分析多模態醫療保健與生命科學 (HCLS) 資料。
參與者
免責聲明
您今天是否找到需要的資訊?
讓我們知道,以便我們改善頁面內容的品質