AWS News Blog
Twelve New Features for Amazon Redshift

|
Amazon Redshift makes it easy for you to launch a data warehouse. Because Redshift is a managed service, you can focus on your data and your analytics, while Redshift takes care of the infrastructure for you.
We have added support for twelve powerful and important features over the past month or so. Let’s take a look at each one…
JSON Support
You can now load data in JSON format directly into Redshift, without preprocessing. Many devices, event handling systems, servers, and games generate data in this format. When you use this new option, you can specify the mapping of JSON elements to Redshift column names in a jsonpaths file. This gives you the power to map the hierarchically data in the JSON file to the flat array of columns used by Redshift. Here’s a sample file:
{
"jsonpaths":
[
"$['id']",
"$['name']",
"$['location'][0]",
"$['location'][1]",
"$['seats']"
]
}
And here’s a COPY command which references the jsonpaths file and the JSON data, both of which are stored in Amazon S3:
COPY venue FROM 's3://mybucket/venue.json'
credentials 'aws_access_key_id=ACCESS-KEY-ID; aws_secret_access_key=SECRET-ACCESS-KEY'
JSON AS 's3://mybucket/venue_jsonpaths.json';
Documentation: Copy from JSON Format.
Copy from Elastic MapReduce
You can now copy data from an Elastic MapReduce cluster to a Redshift cluster. In order to do this you first need to transfer your Redshift cluster’s public key and the IP addresses of the cluster nodes to the EC2 hosts in the Elastic MapReduce cluster. Then you can use a Redshift COPY command to copy fixed-width files, character-delimited files, CSV files, and JSON-formatted files to Redshift.
Documentation: Loading Data From Amazon EMR
Unload to a Single File
You can now use UNLOAD to upload the result of a query to one or more Amazon S3 files:
UNLOAD ('select_statement')
TO 's3://object_path_prefix'
[ WITH ] CREDENTIALS [AS] 'aws_access_credentials'
[ option [ ... ] ]
Option can be either PARALLEL ON or PARALLEL OFF.
By default, UNLOAD writes data in parallel to multiple files, according to the number of slices in the cluster. If PARALLEL is OFF or FALSE, UNLOAD writes to one or more data files serially, limiting the size of each S3 object to 6.2 Gigabytes. If, for example, you unload 13.4 GB of data, UNLOAD automatically will create the following three files:
s3://bucket/key000 6.2 GB
s3://bucket/key001 6.2 GB
s3://bucket/key002 1.0 GB
Documentation: UNLOAD command.
Increased Concurrency
You can now configure a maximum of 50 simultaneous queries across all of your queues. Each slot in a queue is allocated an equal, fixed share of the server memory allocated to the queue.
Increasing the level of concurrency will allow you to increase query performance for some types of workloads. For example, workloads that contain a mix of many small, quick queries and a few, long-running queries can be served by a pair of queues, using one with a high level of concurrency for the small, quick queries and another with a different level of concurrency for long-running queries.
Documentation: Defining Query Queues.
Max Result Set Size
You can now configure the cursor counts and result set sizes. Larger values will result in increased memory consumption; be sure to read the documentation on Cursor Constraints before making any changes. We know that this change will be of special interest to Redshift users who are also making use of data visualization and analytical products from Tableau.
Regular Expression Extraction
The new REGEX_SUBSTR function extracts a substring from a string, as specified by a regular expression. For example, the following SELECT statement retrieves the portion of an email address between the “@” character and the top-level domain name:
select email, regexp_substr(email,'@[^.]*')
Documentation: REGEX_SUBSTR function.
The new REGEX_COUNT function returns an integer that indicates the number of times a regular expression pattern occurs in the string. For example, the following SELECT statement counts the number of times a three-letter sequence occurs:
select regexp_count('abcdefghijklmnopqrstuvwxyz', '[a-z]{3}')
Documentation: REGEX_COUNT function.
The new REGEX_INSTR function returns an integer that indicates the beginning position of the matched regular expression. For example, the following SELECT statement searches for the @ character that begins a domain name and returns the starting position of the first match:
select email, regexp_instr(email,'@[^.]*\\.(org|edu)')
Documentation: REGEX_INSTR function.
The new REGEX_REPLACE function replaces every occurrence of a regular expression with the specified string. For example, the following SELECT statement deletes the @ and domain name from email addresses:
select email, regexp_replace(email, '@.*\\.(org|gov|com)$')
Documentation: REGEX_REPLACE function.
FedRAMP Approval
Amazon Redshift has successfully completed the FedRAMP assessment and authorization process and has been added to the list of services covered under our US East/West FedRAMP Agency Authority to Operate granted by the U.S. Department of Health and Human Services (HHS).
Support for ECDHE-RSA and ECDHE-ESDCSA Cipher Suites
SSL connections to Redshift can now choose between a pair of ECDHE key exchange protocols and the associated cipher suites. With this change, SSL clients that specify these cipher suites now provide perfect forward secrecy.
Resize Progress Indicator
You can now monitor the progress of cluster resize operations. The information is displayed in the Redshift console and is also available via the Redshift API:
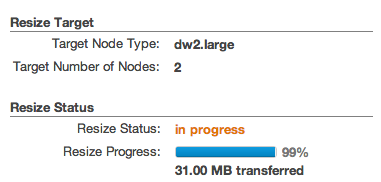
Documentation: DescribeResize.
All of these new features are available now for new clusters and will roll out to existing clusters during maintenance windows in the next two weeks.
To see a complete list of features that we have added to Redshift, please view the Management Guide History and the Developer Guide History.
— Jeff;