Amazon Bedrock 知识库
借助 Amazon Bedrock 知识库,您可以为基础模型和代理提供来自公司私有数据来源的上下文信息,帮助其做出更相关、更准确、更个性化的响应
对端到端 RAG 工作流的完全托管式支持
为了向基础模型(FM)提供最新的专有信息,组织使用了检索增强生成(RAG),该技术可从公司数据来源获取数据,并丰富提示以提供更相关和更准确的响应。Amazon Bedrock 知识库是一项完全托管式功能,具有内置的会话上下文管理和来源归因功能,可帮助您实施从摄取到检索和提示增强的整个 RAG 工作流程,而无需构建与数据来源的自定义集成或管理数据流。您还可以提问并总结单个文档的数据,而无需设置向量数据库。如果您的数据包含结构化来源,则 Amazon Bedrock 知识库会为结构化查询语言解决方案提供内置的托管自然语言,用于生成查询命令来检索数据,而无需将其转移到另一个存储中。
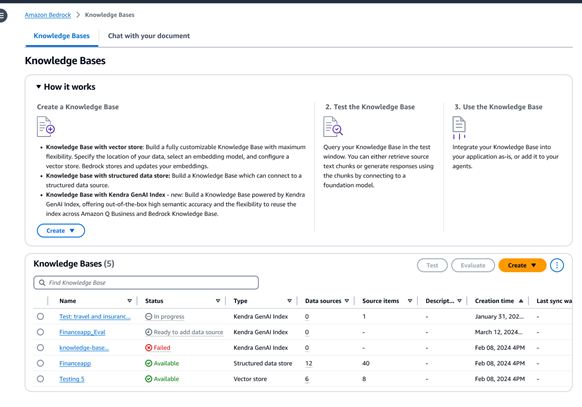
将基础模型和代理与数据来源安全地连接起来
如果您拥有非结构化数据来源,Amazon Bedrock 知识库会自动从预览版 Amazon Simple Storage Service(Amazon S3)、Confluence、Salesforce、SharePoint 或 Web 爬网程序等来源获取数据。此外,您还会获得程序化的文档摄取,让客户能够摄取流数据或从不受支持的来源摄取数据。提取内容后,Amazon Bedrock 知识库会将内容转换为文本块,然后将文本转换为嵌入,并将其存储在向量数据库中。您可以从多个支持的向量存储中进行选择,包括 Amazon Aurora、Amazon Opensearch 无服务器、Amazon Neptune Analytics 分析数据库引擎、MongoDB、Pinecone 和 Redis Enterprise Cloud。您也可以选择连接到 Amazon Kendra 混合搜索索引进行托管式检索。
您还可以使用 Amazon Bedrock 知识库连接到结构化数据存储,以生成可靠的响应。当您有源材料(例如事务详细信息)存储在数据仓库和数据湖中时,这一点特别有用。Amazon Bedrock 知识库使用自然语言到 SQL 将查询转换为 SQL 命令,然后执行这些命令来检索数据,而无需将其从来源中移出。
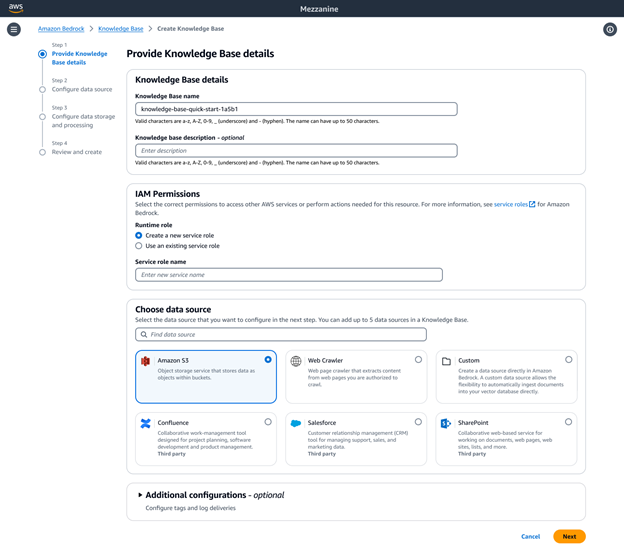
自定义 Amazon Bedrock 知识库,在运行时提供准确响应
您可以将 Amazon Bedrock 知识库作为完全托管式 RAG 解决方案,这样您就可以灵活地进行自定义并提高检索准确性。对于包含图像和布局复杂的视觉效果丰富的文档(例如包含表格、数字、图表和图解的文档)等多模态数据的非结构化数据来源,您可以配置知识库来解析、分析和提取有意义的洞察。您可以选择 Bedrock Data Automation 或基础模型作为解析器。这样就可以无缝处理复杂的多模态数据,从而让您能够构建高度准确的生成式人工智能应用程序。
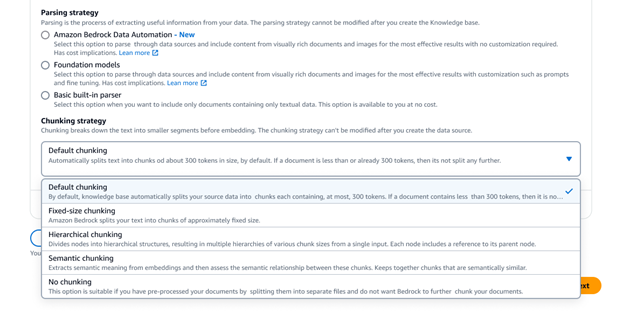
Amazon Bedrock 知识库提供了各种高级数据分块选项,包括语义、分层和固定大小的分块。为了实现完全控制,您可以将自己的分块代码编写为 Lambda 函数,甚至可以使用来自 LangChain 和 LlamaIndex 等框架的现成组件。如果您选择 Amazon Neptune Analytics 分析数据库引擎作为向量存储,则 Amazon Bedrock 知识库会自动创建嵌入和图表,以链接您数据来源中的相关内容。Bedrock 知识库利用与 GraphRAG 相关的这些内容来提高检索的准确性,从而为最终用户提供更全面、更相关以及更可解释的响应。
检索数据并增强提示
您可以使用 Retrieve API 从知识库中获取用户查询的相关结果,包括图像、图解、图表、表格、音频和视频内容等视觉元素,或从数据库中获取结构化数据(如适用)。RetrieveAndGenerate API 可帮助您直接使用检索到的多模态结果来增强基础模型提示并返回响应。您也可以选择提供筛选条件或使用基础模型生成隐式筛选条件,以便将返回的结果限制为仅显示相关内容。Amazon Bedrock 知识库可提供重排器模型,以提高检索到的文档区块在文本、视觉和多媒体内容中的相关性。
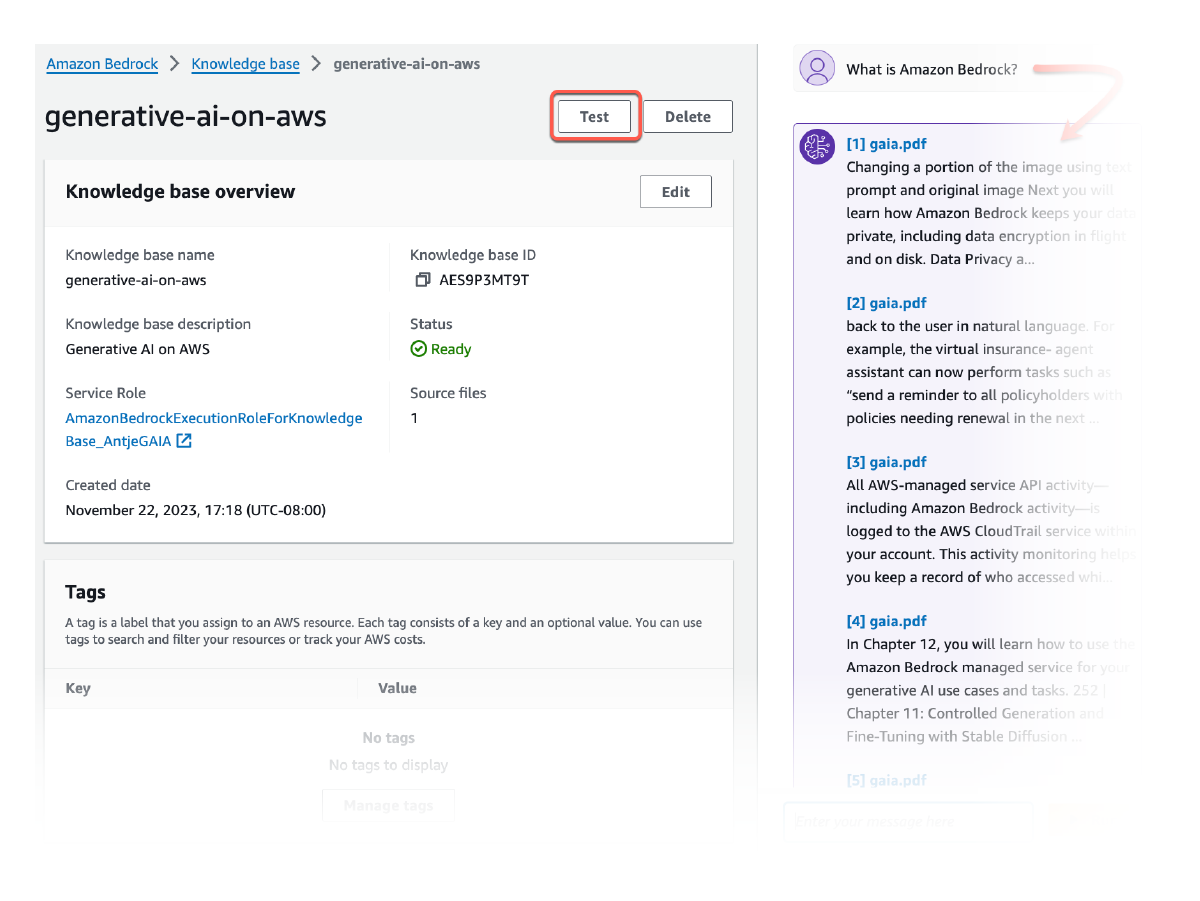
提供来源归因
从 Amazon Bedrock 知识库检索到的所有信息均附有引文(其中还包括视觉效果),可提高透明度并最大限度地减少幻觉。
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量