概述
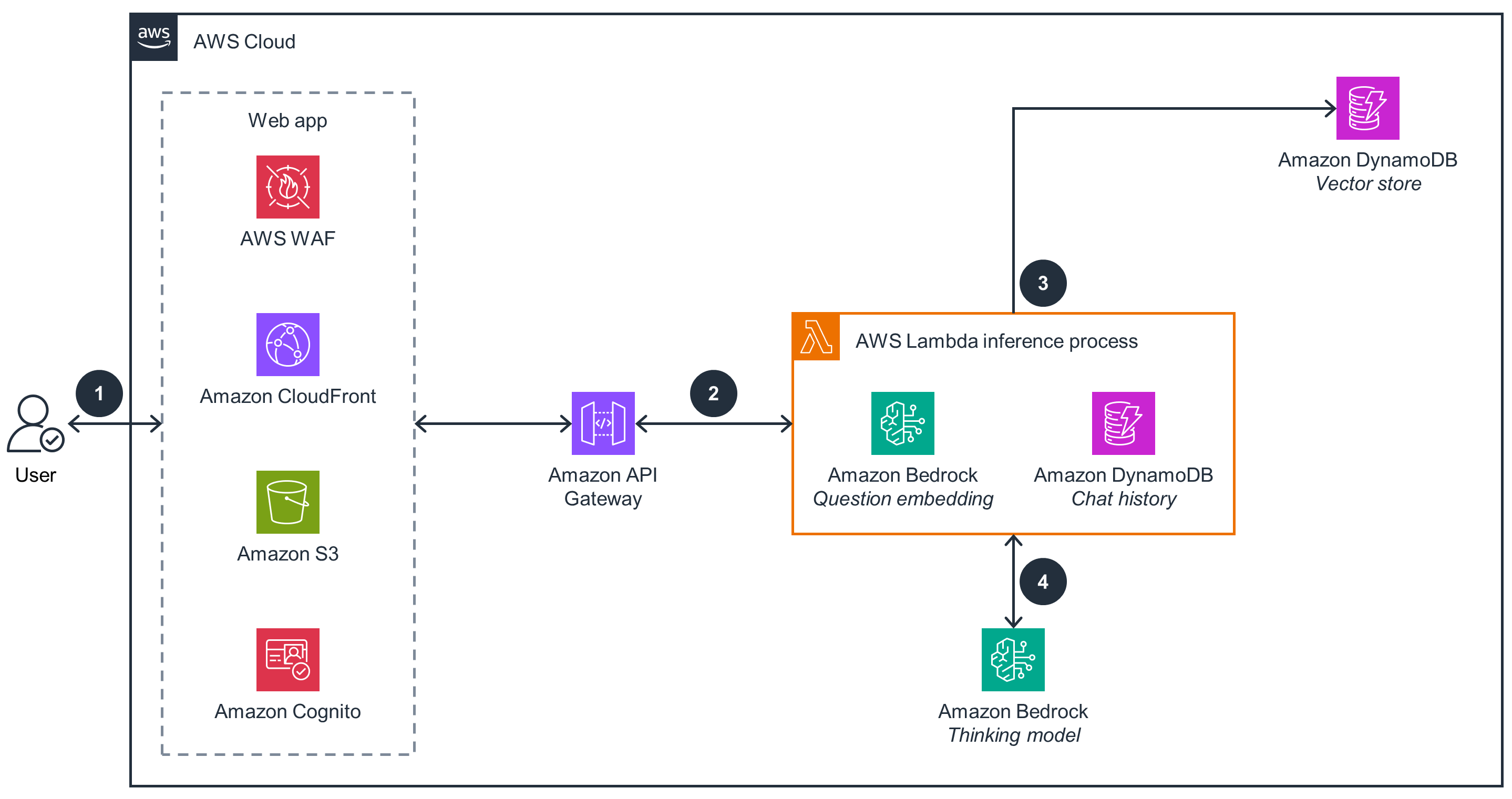
本指南将展示如何实施经济高效的检索增强生成(RAG)解决方案,以满足您的人工智能需求。它为创建易于访问的小规模 RAG 实现提供了实用的工具和方法,这些 RAG 实现始终保持有效,而不会产生通常与向量数据库解决方案相关的高昂成本。这种方法让人们更容易获得先进的人工智能技术,并使您的小型企业能够对生成式人工智能应用程序进行个性化,并在预算限制内使用各项人工智能功能。

自信地进行部署
为部署做好准备了吗? 查看 GitHub 上的示例代码,了解详细的部署说明,以根据需要按原样部署或进行自定义部署。
优势
免责声明
示例代码;软件库;命令行工具;概念验证;模板;或其他相关技术(包括由我方人员提供的任何前述项)作为 AWS 内容按照《AWS 客户协议》或您与 AWS 之间的相关书面协议(以适用者为准)向您提供。您不应将这些 AWS 内容用在您的生产账户中,或用于生产或其他关键数据。您负责根据特定质量控制规程和标准测试、保护和优化 AWS 内容,例如示例代码,以使其适合生产级应用。部署 AWS 内容可能会因创建或使用 AWS 可收费资源(例如,运行 Amazon EC2 实例或使用 Amazon S3 存储)而产生 AWS 费用。
本指南中提及第三方服务或组织并不意味着 Amazon 或 AWS 与第三方之间存在认可、赞助或从属关系。AWS 的指南是一个技术起点,您可以在部署架构时自定义与第三方服务的集成。
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量。