概览
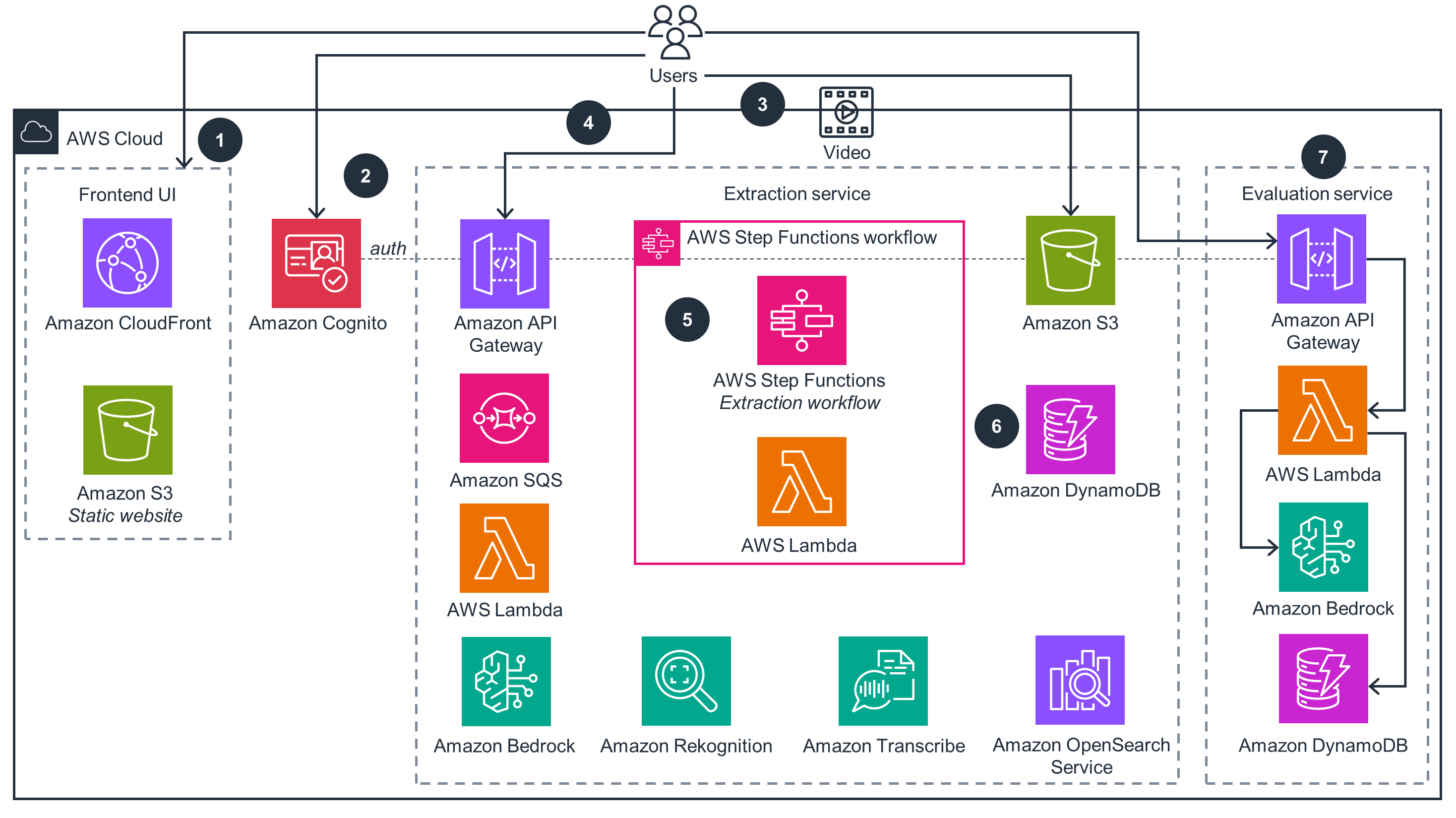
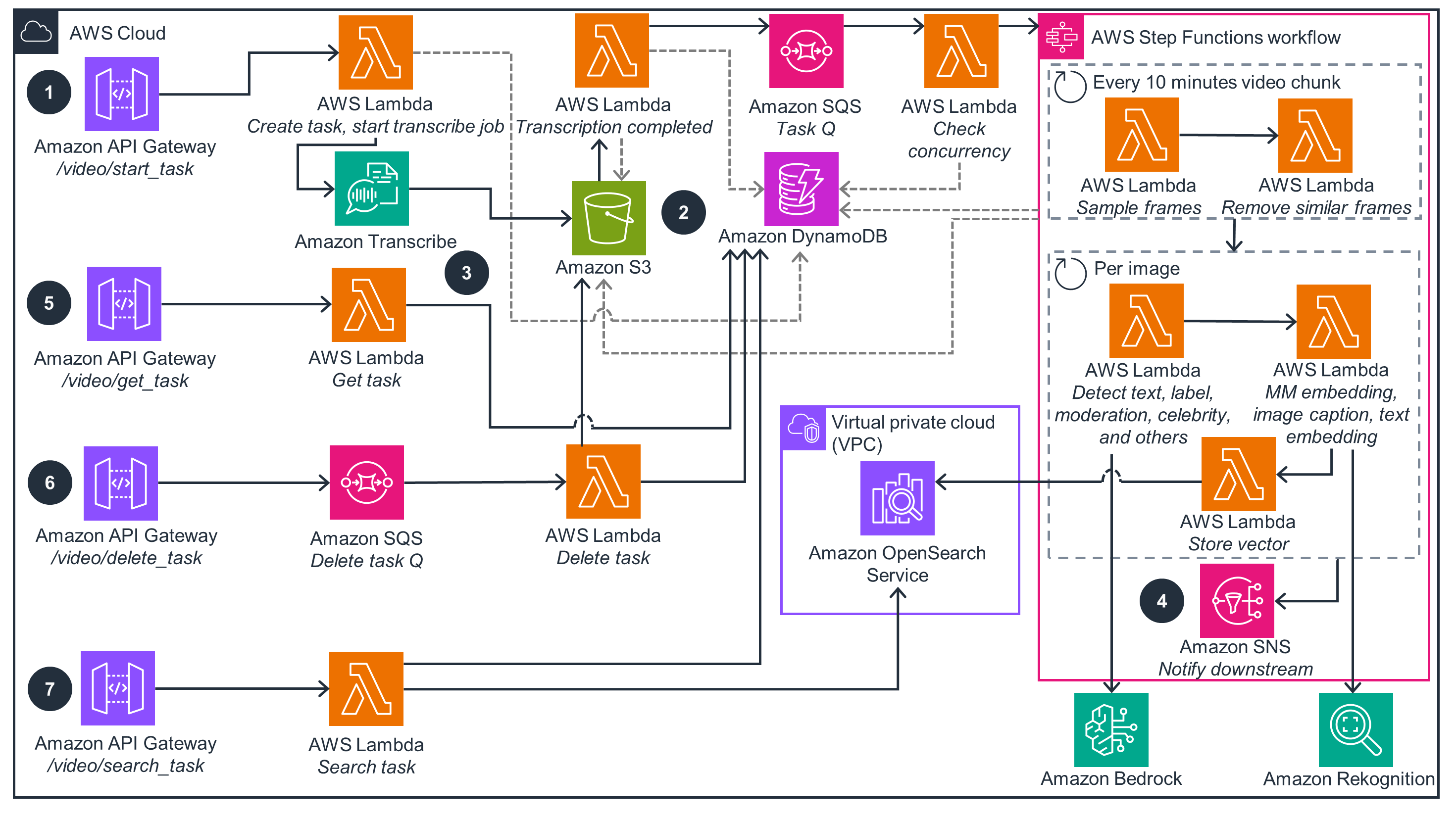
本指南演示了如何通过自动提取视频元数据、情报收集和内容审核来加快内容分析工作流程。它使您能够高效地处理大量视频内容,提取有价值的见解,并通过可自定义的策略评估做出数据驱动型决策。通过将这些传统的手动任务自动化,您可以降低运营成本、提高准确性并扩展内容分析能力,同时保持安全可靠的运营。
自信地进行部署
为部署做好准备了吗? 查看 GitHub 上的示例代码,了解详细的部署说明,进而根据需要按原样部署或进行自定义部署。
Well-Architected 支柱
上面的架构图是按照 Well-Architected 最佳实践创建的解决方案示例。要做到完全的良好架构,您应该遵循尽可能多的 Well-Architected 最佳实践。
Amazon CloudWatch 为在 AWS Lambda 和 Step Functions 中运行的服务提供日志记录和见解。 本指南在各个阶段将指标推送到 CloudWatch,以提供 Lambda 函数、AI/ML 服务和 S3 存储桶等基础设施的可观测性。
阅读《卓越运营》白皮书本指南实施最低权限 AWS Identity and Access Management 策略,并使用 AWS Key Management Service(AWS KMS)密钥加密 S3 数据。通过 Amazon Cognito 处理用户身份验证,使用 OAuth 模式进行 Web 应用程序登录和 API Gateway 调用。OpenSearch 服务集群部署在 Amazon Virtual Private Cloud(Amazon VPC)私有子网中,只有经授权的 Lambda 函数才能访问。
阅读《安全性》白皮书Amazon S3 通过版本控制、防止删除和跨区域复制功能提供强大的数据管理。API Gataway、Lambda、Step Functions 和 Amazon Simple Queue Service(Amazon SQS)等无服务器服务提供内置的可扩展性和高可用性。OpenSearch Service 部署通过多个可用区支持高可用性,其特点是具有复制分片的冗余数据节点,有助于确保数据的持久性和恢复能力。
阅读《可靠性》白皮书Lambda 和 Step Functions 通过并行执行函数和工作流程步骤实现高效的并行处理。这种并行处理能力提高了总体吞吐量并缩短了执行时间。无服务器架构可自动处理在 AWS 上扩展工作负载的复杂性,从而为媒体处理任务提供最佳性能。
阅读《性能效率》白皮书Amazon S3 存储类和生命周期策略可优化视频存储成本,而无服务器和 AI/ML 服务则采用即用即付模式,这意味着您只需为使用的服务付费。事件驱动型架构有助于确保仅对实际使用的资源收费,使您能够经济高效地配置和定制媒体工作流程,同时使用 S3 生命周期策略存储和归档摄取的内容、代理和元数据。
阅读《成本优化》白皮书AWS 无服务器服务和 AI/ML 组件可根据需求动态分配计算资源,从而消除过度配置并减少资源浪费。与传统的本地服务器相比,这种方法最大限度地降低了能耗,同时最大限度地提高了 AWS 人工智能服务的效率,从而减少后端操作对环境的影响。
免责声明
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量