- AWS 解决方案库
- AWS 上具有分布式数据资产所有权的安全数据网格的指南
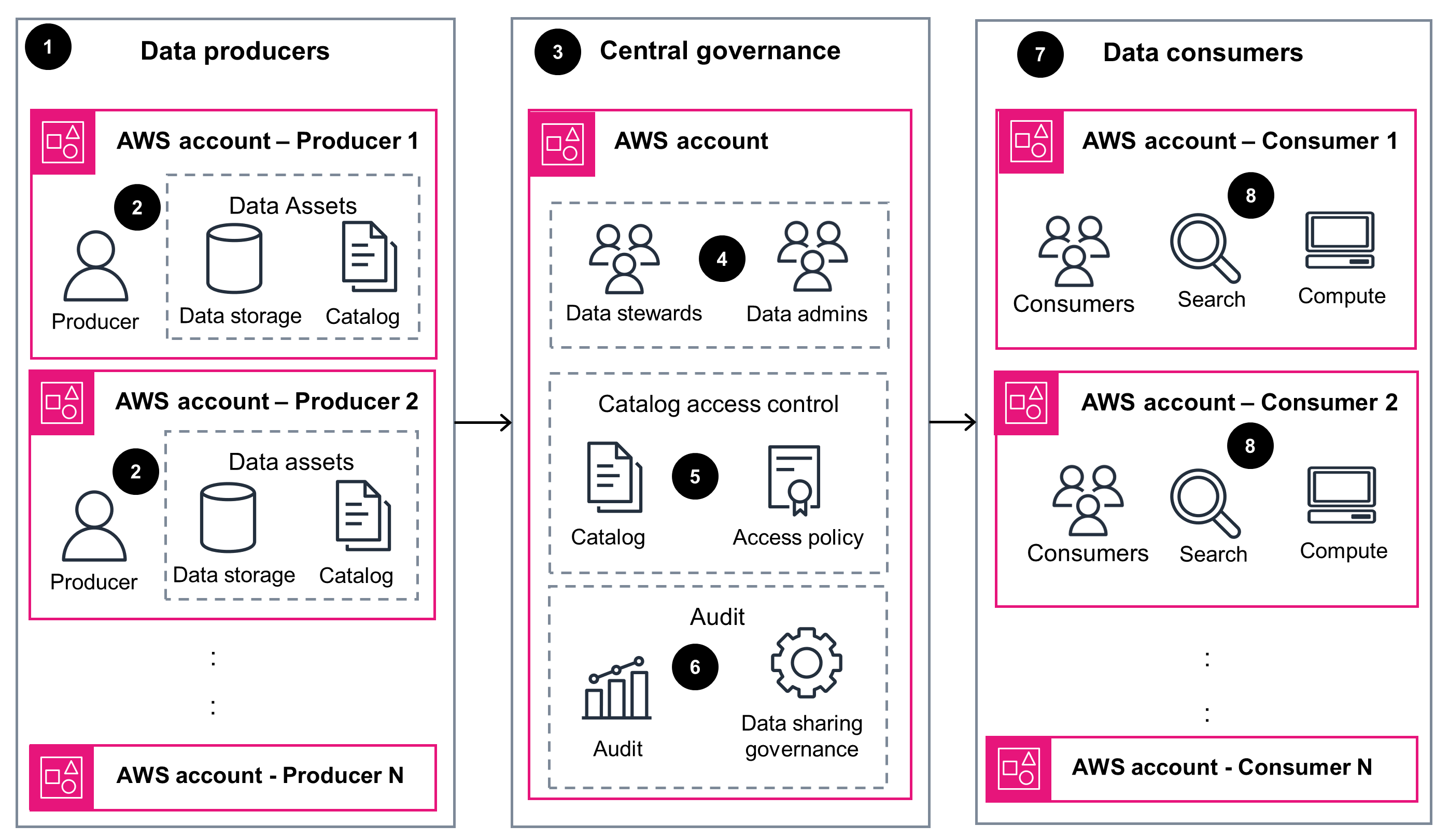
AWS 上具有分布式数据资产所有权的安全数据网格的指南
概览
Well-Architected 支柱
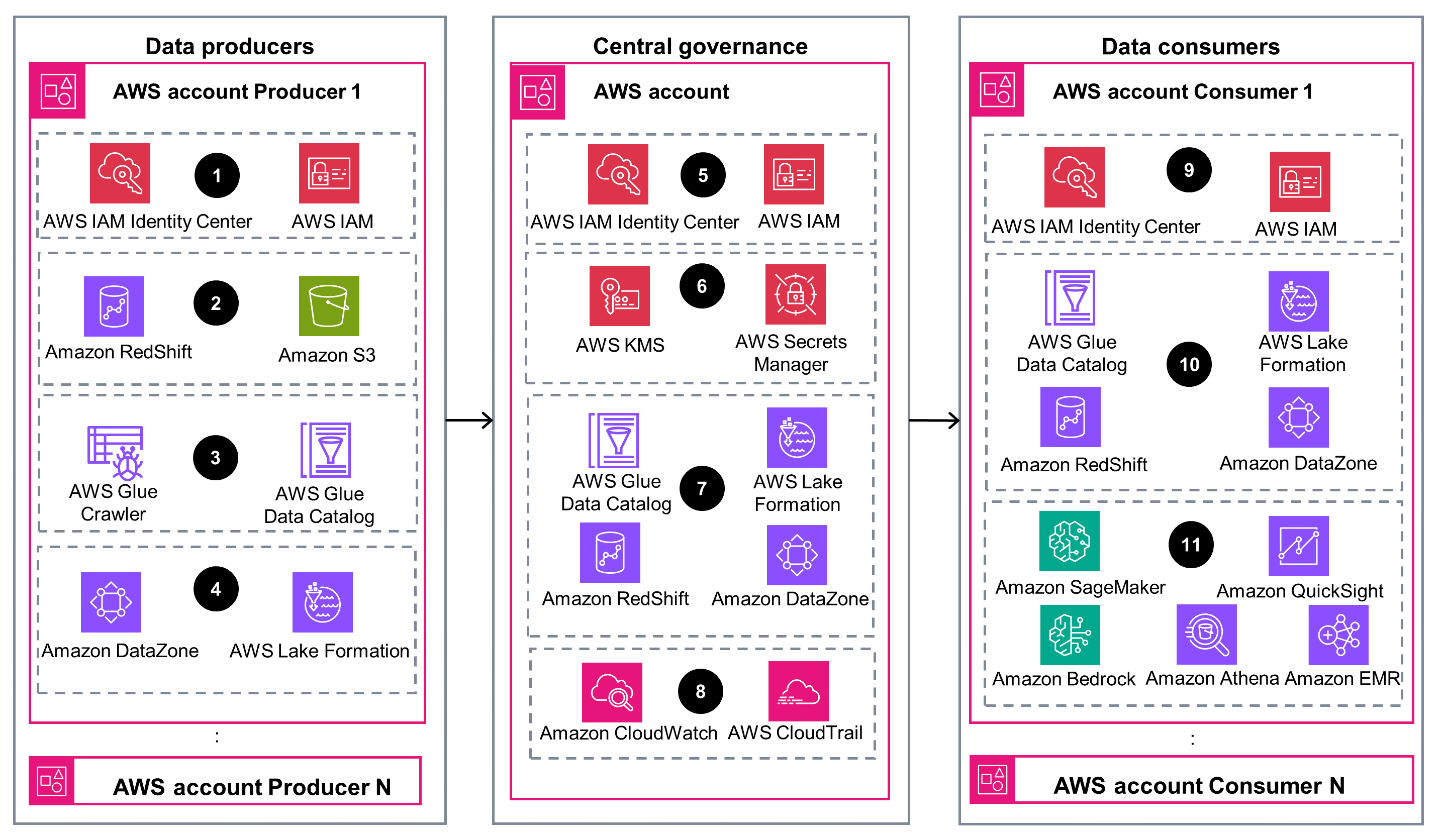
上面的架构图是按照 Well-Architected 最佳实践创建的解决方案示例。要做到完全的良好架构,您应该遵循尽可能多的 Well-Architected 最佳实践。
您可以通过 CloudWatch 全面了解您的资源和服务,从而实现主动监控、快速故障排除和及时事件响应。您还可以通过 CloudTrail 审核 AWS 账户,通过详细的活动日志支持治理和合规性。使用这些服务可以维护架构的卓越运营并有效应对事件和事故。
使用 IAM 和 AWS KMS 优先考虑数据和资源的安全。IAM 允许您集中管理细粒度的权限,指定谁或什么可以访问您的 AWS 服务和资源。另一方面,AWS KMS 允许您定义静态和传输中数据加密的加密密钥,从而保护敏感信息的机密性和完整性。
使用 Amazon S3 和 Data Catalog 保障数据和应用程序的可靠性。Amazon S3 旨在提供高耐用性和可用性,可自动在多个可用区域复制您的数据。Data Catalog 充当集中式元数据存储库,帮助您在不同的数据存储中维护一致且可靠的数据来源视图。
使用 Amazon Redshift 和 Athena 优化数据处理和分析的性能。Amazon Redshift 是一项完全托管的大规模并行处理(MPP)数据仓库服务,可帮助您快速且经济高效地做出业务决策。Athena 是一项无服务器交互式查询服务,让您可以使用标准 SQL 直接在 Amazon S3 中分析数据,而无需管理任何基础设施。
作为一项完全托管的无服务器服务,Amazon S3 无需配置和管理基础设施,从而降低了相关成本。使用 Amazon S3 提供的各种存储类,包括 Amazon S3 Intelligent-Tiering 存储类、S3 Standard、S3 Standard-IA 和 S3 Glacier,以最具成本效益的选项满足您的数据存储和访问需求。
Amazon DataZone 有助于减少数据冗余、执行数据治理策略并促进安全的数据共享,从而优化存储使用率并降低对环境的影响。通过集中数据并启用协作数据共享,您可以最大限度地降低整个组织内部的数据重复需求,从而帮助建立更可持续的数据环境。
免责声明
找到今天要查找的内容了吗?
请提供您的意见,以便我们改进网页内容的质量