- Amazon Redshift›
- Funktionen›
- Integration für Apache Spark
Amazon-Redshift-Integration für Apache Spark
Erstellen Sie Apache-Spark-Anwendungen, die Daten von Amazon Redshift lesen und schreiben
Warum Amazon-Redshift-Integration für Apache Spark?
Vorteile von Amazon Redshift
-
Erweitern Sie die Breite der Datenquellen, die Sie in Ihren Rich-Analytics- und Machine-Learning-Anwendungen (ML) verwenden können, die in Amazon EMR, AWS Glue oder SageMaker ausgeführt werden, indem Sie Daten aus Ihrem Data Warehouse lesen und in dieses schreiben.
-
Optimieren Sie den umständlichen und oft manuellen Prozess der Einrichtung nicht zertifizierter Konnektoren und JDBC-Treiber und reduzieren Sie die Vorbereitungszeit für Analyse- und ML-Aufgaben.
-
Verwenden Sie mehrere Pushdown-Funktionen wie Sortieren, Aggregieren, Begrenzen, Verbinden und Skalarfunktionen, damit nur relevante Daten aus dem Amazon Redshift Data Warehouse verschoben werden.
Funktionsweise
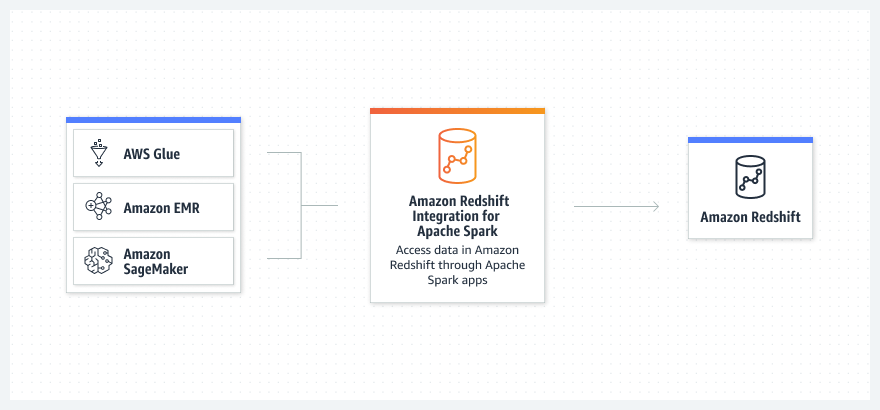
Anwendungsfälle
-
Erstellen Sie Apache-Spark-Anwendungen in Java, Scala und Python mit Apache-Spark-basierten AWS-Analyseservices.
-
Lesen und schreiben Sie Daten in und aus Amazon Redshift mit Amazon EMR, AWS Glue, SageMaker und AWS Analytics und ML-Services.
-
Verwenden Sie Amazon EMR oder AWS Glue, um Datenrahmencode aus Ihrer Apache-Spark-Aufgabe oder -Notebook zu übernehmen und eine Verbindung zu Amazon Redshift herzustellen.
-
Optimieren Sie Ihren Prozess ohne Installation oder Tests, mit verbesserter Sicherheit (IAM-basierte Anmeldeinformationen) und Betriebs-Pushdowns, sowie Parquet-Dateiformat für Leistung.
Kunden
Corey Johnson, Data Architect Manager – Huron Consulting
Huron ist ein globales Unternehmen für professionelle Dienstleistungen, das mit Kunden zusammenarbeitet, um das Mögliche in die Praxis umzusetzen, indem es solide Strategien entwickelt, Abläufe optimiert, die digitale Transformation beschleunigt und Unternehmen und ihre Mitarbeiter in die Lage versetzt, ihre Zukunft selbst in die Hand zu nehmen.
„Wir befähigen unsere Ingenieure, ihre Datenpipelines und Anwendungen mit Apache Spark unter Verwendung von Python und Scala zu erstellen. Wir wollten eine maßgeschneiderte Lösung, die den Betrieb vereinfacht und schneller und effizienter für unsere Kunden bereitgestellt wird, und genau das bekommen wir mit der neuen Amazon Redshift-Integration für Apache Spark.“
Alcuin Weidus, Sr Principal Data Architect – GE Aerospace
GE Aerospace ist ein globaler Anbieter von Strahltriebwerken, Komponenten und Systemen für Verkehrs- und Militärflugzeuge. Das Unternehmen entwirft, entwickelt und fertigt seit dem Ersten Weltkrieg Strahltriebwerke.
„GE Aerospace nutzt AWS Analytics und Amazon Redshift, um wichtige Geschäftseinblicke zu ermöglichen, die wichtige Geschäftsentscheidungen vorantreiben. Mit der Unterstützung für das automatische Kopieren von Amazon S3 können wir einfachere Datenpipelines erstellen, um Daten von Amazon S3 zu Amazon Redshift zu verschieben. Dies beschleunigt die Fähigkeit unserer Datenproduktteams, auf Daten zuzugreifen und Endbenutzern Einblicke zu liefern. Wir verbringen mehr Zeit mit der Wertschöpfung durch Daten und weniger Zeit mit Integrationen.“
Neema Raphael, Chief Data Officer – Goldman Sachs
Die Goldman Sachs Group, Inc. ist ein führendes globales Finanzinstitut, das einem großen und diversifizierten Kundenstamm, zu dem Unternehmen, Finanzinstitute, Regierungen und Privatpersonen gehören, eine breite Palette von Finanzdienstleistungen in den Bereichen Investment Banking, Wertpapiere, Anlageverwaltung und Privatkundengeschäft anbietet.
„Unser Fokus liegt darauf, allen unseren Nutzern bei Goldman Sachs einen Self-Service-Zugriff auf Daten zu bieten. Über Legend, unsere Open-Source-Datenmanagement- und Governance-Plattform, ermöglichen wir es Benutzern, datenzentrische Anwendungen zu entwickeln und datengesteuerte Erkenntnisse zu gewinnen, während wir in der gesamten Finanzdienstleistungsbranche zusammenarbeiten. Mit der Amazon Redshift-Integration für Apache Spark wird unser Datenplattformteam in der Lage sein, mit minimalen manuellen Schritten auf Amazon-Redshift-Daten zuzugreifen – was Zero-Code-ETL ermöglicht, was unsere Fähigkeit erhöht, es Ingenieuren zu erleichtern, sich auf die Perfektionierung ihres Arbeitsablaufs zu konzentrieren, während sie vollständige und zeitnahe Informationen sammeln. Wir erwarten eine Leistungssteigerung von Anwendungen und eine verbesserte Sicherheit, da unsere Benutzer jetzt problemlos auf die neuesten Daten in Amazon Redshift zugreifen können.“
Ressourcen
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern.