Amazon SageMaker HyperPod – Features
Entwicklung generativer KI-Modelle für Tausende von KI-Beschleunigern skalieren und beschleunigen
Training ohne Kontrollpunkte
Das Training ohne Kontrollpunkte in Amazon SageMaker HyperPod ermöglicht eine automatische Wiederherstellung nach Infrastrukturfehlern innerhalb von Minuten ohne manuelles Eingreifen. Es reduziert die Notwendigkeit eines Kontrollpunkt-basierten Neustarts auf Auftragsebene zur Fehlerbehebung, bei dem der gesamte Cluster angehalten, Probleme behoben und der Zustand aus einem gespeicherten Kontrollpunkt wiederhergestellt werden muss. Das Training ohne Kontrollpunkte gewährleistet einen kontinuierlichen Trainingsfortschritt trotz Ausfällen, da SageMaker HyperPod fehlerhafte Komponenten automatisch austauscht. Das Training wird mithilfe einer Peer-to-Peer-Übertragung der Modell- und Optimierungszustände von funktionsfähigen KI-Beschleunigern wiederhergestellt. Es ermöglicht einen Trainingsdurchsatz von über 95 % in Clustern mit Tausenden von KI-Beschleunigern. Mit Training ohne Kontrollpunkte können Sie Millionen an Rechenkosten einsparen, das Training auf Tausende von KI-Beschleunigern skalieren und Ihre Modelle schneller in die Produktion bringen.
Elastisches Training
Das elastische Training in Amazon SageMaker HyperPod skaliert Trainingsaufträge automatisch basierend auf der Verfügbarkeit von Rechenressourcen und spart so wöchentlich mehrere Stunden an Entwicklungszeit, die zuvor für die Neukonfiguration von Trainingsaufträgen aufgewendet werden mussten. Die Nachfrage nach KI-Beschleunigern schwankt ständig, da sich Inferenz-Workloads mit den Datenverkehrsmustern erhöhen, abgeschlossene Experimente Ressourcen freigeben und neue Trainingsaufträge die Workload-Prioritäten verschieben. SageMaker HyperPod erweitert laufende Trainingsaufträge dynamisch, um ungenutzte KI-Beschleuniger aufzunehmen und so die Infrastrukturauslastung zu maximieren. Wenn Workloads mit höherer Priorität wie Inferenz oder Bewertung Ressourcen benötigen, wird das Training herunterskaliert, um mit weniger Ressourcen fortzufahren, ohne vollständig anzuhalten. Dadurch wird die erforderliche Kapazität basierend auf der durch die Richtlinien zur Aufgaben-Governance festgelegten Prioritäten erreicht. Elastisches Training hilft Ihnen dabei, die Entwicklung von KI-Modellen zu beschleunigen und gleichzeitig Kostenüberschreitungen durch ungenutzte Rechenkapazität zu reduzieren.
Aufgaben-Governance
Flexible Trainingspläne
Spot Instances für Amazon SageMaker HyperPod
Mit Spot Instances in SageMaker HyperPod können Sie zu deutlich reduzierten Kosten auf Rechenkapazitäten zugreifen. Spot Instances eignen sich ideal für fehlertolerante Workloads wie Batch-Inferenz-Aufträge. Die Preise variieren je nach Region und Instance-Typ und bieten in der Regel einen Rabatt von bis zu 90 % gegenüber den Preisen für SageMaker HyperPod On-Demand. Die Preise für Spot Instances werden von Amazon EC2 festgelegt und ändern sich schrittweise entsprechend der langfristigen Trends beim Angebot von und der Nachfrage nach Spot-Instance-Kapazitäten. Sie zahlen den Spot-Preis, der für den Zeitraum der Ausführung Ihrer Instances gilt, ohne dass eine Vorabverpflichtung erforderlich ist. Weitere Informationen zu den geschätzten Preisen für Spot Instances und zur Verfügbarkeit von Instances finden Sie auf der Preisseite für EC2 Spot Instances. Beachten Sie, dass für die Spot-Nutzung in HyperPod nur Instances verfügbar sind, die auch in HyperPod unterstützt werden.
Optimierte Rezepte zur Anpassung von Modellen
Mit SageMaker-HyperPod-Rezepten profitieren Datenwissenschaftler und Entwickler aller Qualifikationsstufen von modernster Leistung und können schnell mit dem Training und der Feinabstimmung öffentlich verfügbarer Basismodelle beginnen, darunter Llama-, Mixtral-, Mistral- und DeepSeek-Modelle. Darüber hinaus können Sie Basismodelle von Amazon Nova, darunter Nova Micro, Nova Lite und Nova Pro, mithilfe einer Reihe von Techniken wie Supervised Fine-Tuning (SFT), Knowledge Distillation, Direct Preference Optimization (DPO), Proximal Policy Optimization und Continued Pre-Training – mit Unterstützung für sowohl parametereffizientes Modelltraining als auch für Neutrainieren des gesamten Modells über SFT, Distillation und DPO hinweg. Jedes Rezept beinhaltet einen von AWS getesteten Trainings-Stack, wodurch Sie sich wochenlange, mühsame Arbeit beim Testen verschiedener Modellkonfigurationen ersparen. Sie können mit einer einzeiligen Rezeptänderung zwischen GPU-basierten und AWS-Trainium-basierten Instances wechseln, automatisierte Modell-Kontrollpunkte für eine verbesserte Trainingsresilienz aktivieren und Workloads in der Produktion auf SageMaker HyperPod ausführen.
Amazon Nova Forge ist ein einzigartiges Programm, das Unternehmen die einfachste und kostengünstigste Möglichkeit bietet, mit Nova ihre eigenen Frontier-Modelle zu entwickeln. Greifen Sie auf Zwischen-Kontrollpunkte von Nova-Modellen zu und trainieren Sie diese. Kombinieren Sie während des Trainings von Amazon kuratierte Datensätze mit geschützten Daten und nutzen Sie SageMaker-HyperPod-Rezepte, um Ihre eigenen Modelle zu trainieren. Mit Nova Forge können Sie Ihre eigenen Unternehmensdaten nutzen, um anwendungsspezifische Erkenntnisse zu gewinnen und die Preis-Leistungs-Verhältnisse für Ihre Aufgaben zu verbessern.
Hochleistungsfähiges verteiltes Training
Fortschrittliche Tools für Beobachtbarkeit und zum Experimentieren
Die Beobachtbarkeit von SageMaker HyperPod bietet ein einheitliches Dashboard, das in Amazon Managed Grafana vorkonfiguriert ist, wobei die Überwachungsdaten automatisch in einem Arbeitsbereich von Amazon Managed Prometheus veröffentlicht werden. Sie können Leistungsmetriken, Ressourcenauslastung und den Zustand des Clusters in Echtzeit in einer einzigen Ansicht anzeigen, sodass Teams Engpässe schnell erkennen, kostspielige Verzögerungen vermeiden und Rechenressourcen optimieren können. SageMaker HyperPod ist außerdem in Amazon CloudWatch Container Insights integriert und bietet so tiefere Einblicke in die Leistung, den Zustand und die Nutzung von Clustern. Mit Managed TensorBoard in SageMaker können Sie Entwicklungszeit einsparen, indem Sie die Modellarchitektur visualisieren, um Konvergenzprobleme zu identifizieren und zu beheben. Mit Managed MLflow in SageMaker können Sie Experimente in großem Umfang effizient verwalten.
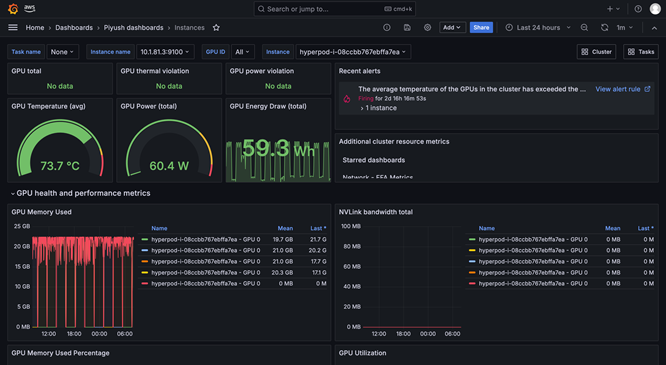
Workload-Planung und -Orchestrierung
Automatische Zustandsprüfung und Reparatur von Clustern
Bereitstellung von Open-Weights-Modellen mit SageMaker Jumpstart beschleunigen
SageMaker HyperPod optimiert automatisch die Bereitstellung von Open-Weights-Basismodellen aus SageMaker JumpStart und optimierten Modellen aus Amazon S3 und Amazon FSx. SageMaker HyperPod stellt automatisch die erforderliche Infrastruktur bereit und konfiguriert Endpunkte, wodurch manuelle Bereitstellungen entfallen. Mit der SageMaker-HyperPod-Aufgaben-Governance wird der Endpunkt-Datenverkehr kontinuierlich überwacht und die Rechenressourcen dynamisch angepasst, während gleichzeitig umfassende Leistungsmetriken zur Echtzeitüberwachung und -optimierung im Dashboard für Beobachtbarkeit veröffentlicht werden.
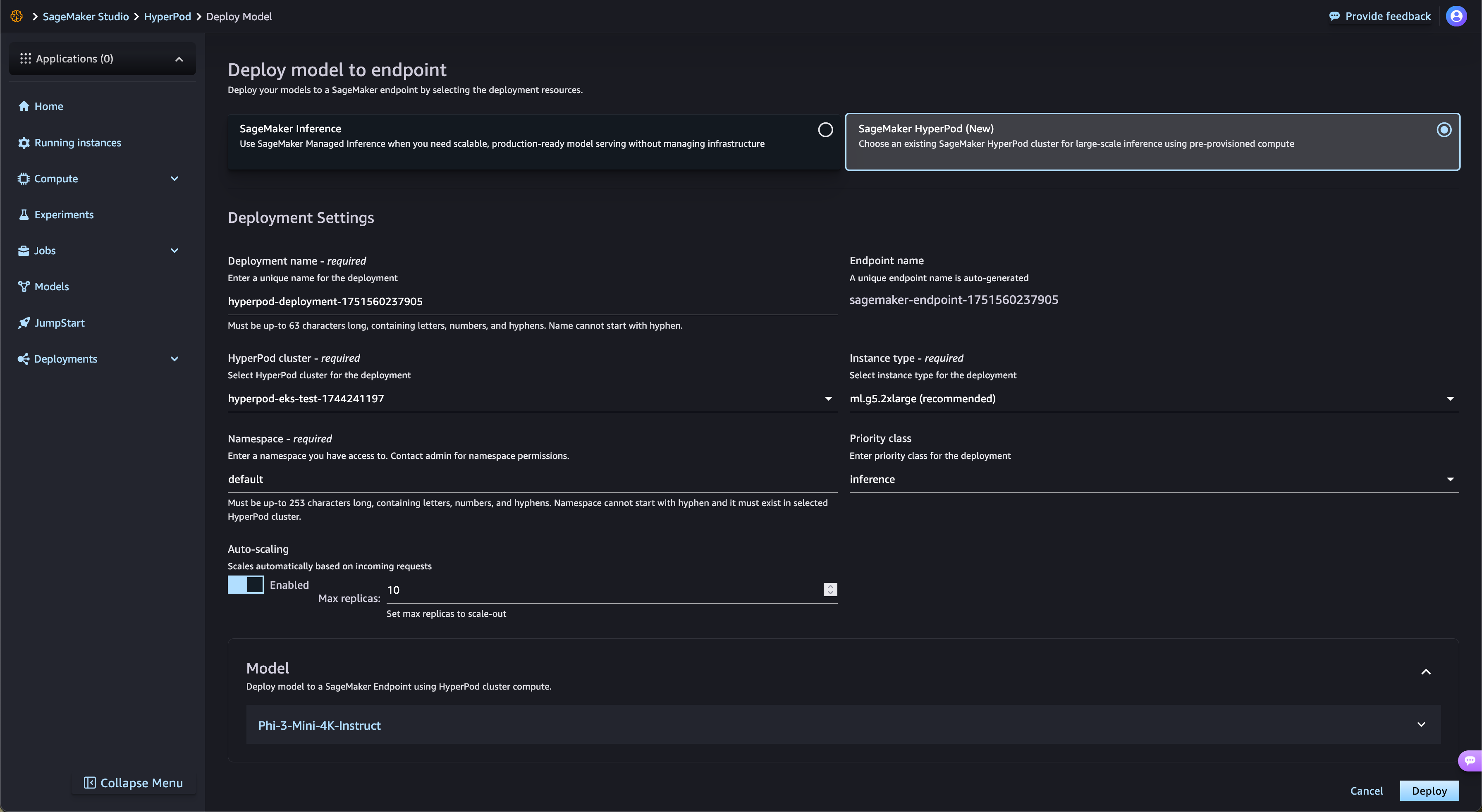
Verwaltete mehrstufige Kontrollpunkte
SageMaker HyperPod Managed Tiered Checkpointing nutzt den CPU-Speicher, um häufige Kontrollpunkte für eine schnelle Wiederherstellung zu speichern, während Daten regelmäßig in Amazon Simple Storage Service (Amazon S3) gespeichert werden, um eine langfristige Haltbarkeit zu gewährleisten. Dieser hybride Ansatz minimiert den Trainingsverlust und verkürzt die Zeit bis zur Wiederaufnahme des Trainings nach einem Ausfall erheblich. Kunden können die Häufigkeit von Kontrollpunkten und Aufbewahrungsrichtlinien sowohl für den Arbeitsspeicher als auch für persistente Speicherebenen konfigurieren. Durch die häufige Speicherung im Arbeitsspeicher können Kunden schnell Daten wiederherstellen und gleichzeitig die Speicherkosten minimieren. Durch die Integration mit Distributed Checkpoint (DCP) von PyTorch können Kunden die Überprüfung mit nur wenigen Zeilen Code einfach implementieren und gleichzeitig die Leistungsvorteile der In-Memory-Speicherung nutzen.
Maximierung der Ressourcennutzung durch GPU-Partitionierung
Mit SageMaker HyperPod können Administratoren GPU-Ressourcen in kleinere, isolierte Recheneinheiten aufteilen, um die GPU-Auslastung zu maximieren. Sie können verschiedene generative KI-Aufgaben auf einer einzigen GPU ausführen, anstatt ganze GPUs für Aufgaben zu reservieren, die nur einen Bruchteil der Ressourcen benötigen. Dank Leistungsmetriken in Echtzeit und Überwachung der Ressourcenauslastung über GPU-Partitionen hinweg erhalten Sie einen Überblick darüber, wie Aufgaben die Rechenressourcen nutzen. Diese optimierte Zuweisung und vereinfachte Einrichtung beschleunigt die Entwicklung generativer KI, verbessert die GPU-Auslastung und sorgt für eine effiziente Nutzung der GPU-Ressourcen für alle Aufgaben in großem Maßstab.
Haben Sie die gewünschten Informationen gefunden?
Ihr Feedback hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern.