- Machine Learning
- Amazon SageMaker AI
- Amazon SageMaker avec MLflow
Accélérez le développement de l’IA générative avec Amazon SageMaker AI et MLflow
Suivez les expériences, évaluez les modèles et tracez les applications d’IA sans gestion d’infrastructure
Pourquoi utiliser Amazon SageMaker AI avec MLflow ?
La création et la personnalisation de modèles d’IA sont un processus itératif qui implique des centaines de sessions de formation pour trouver le meilleur algorithme, la meilleure architecture et les meilleurs paramètres pour une précision de modèle optimale. Amazon SageMaker AI propose une fonctionnalité MLflow gérée et sans serveur qui permet aux développeurs d’IA de suivre facilement les expériences, d’observer le comportement et d’évaluer les performances de leurs modèles et applications d’IA sans avoir à gérer d’infrastructure. SageMaker AI avec MLflow est également intégré à des outils de développement de modèles SageMaker AI familiers tels que SageMaker AI JumpStart, un registre de modèles, des pipelines et à des fonctionnalités de personnalisation de modèles sans serveur pour vous aider à connecter chaque étape du cycle de vie de l’IA, de l’expérimentation au déploiement.
Avantages d’Amazon SageMaker AI avec MLflow
Commencez à suivre les expériences et à suivre les applications d’IA sans infrastructure à provisionner et sans serveurs de suivi à configurer. Les développeurs d’IA bénéficient d’un accès instantané à une fonctionnalité MLflow sans serveur qui permet à votre équipe de se concentrer sur la création d’applications d’IA plutôt que sur la gestion de l’infrastructure.
SageMaker AI avec MLflow se met à l’échelle automatiquement à vos besoins, que vous meniez une seule expérience ou que vous gériez des centaines de tâches de peaufinage en parallèle. MLflow met à l’échelle votre infrastructure pendant les périodes d’expérimentation intensives et la réduit pendant les périodes calmes sans intervention manuelle, tout en maintenant des performances constantes sans la charge opérationnelle liée à la gestion des serveurs.
Grâce à une interface unique, vous pouvez visualiser les tâches d’entraînement en cours, collaborer avec les membres de l’équipe pendant les expérimentations et gérer le contrôle des versions pour chaque modèle et application. MLflow propose également des fonctionnalités de traçage avancées pour vous aider à identifier rapidement la source des bogues ou des comportements inattendus.
Au fur et à mesure de l’évolution du projet MLflow, les clients de SageMaker AI continueront de bénéficier de l’innovation de la communauté open source tout en bénéficiant de la prise en charge sans serveur d’AWS.
Amazon SageMaker AI avec MLflow passe automatiquement à la dernière version de MLflow, ce qui vous permet d’accéder aux fonctionnalités et capacités les plus récentes sans fenêtres de maintenance ni effort de migration.
Simplifiez la personnalisation des modèles d’IA
Avec MLflow sur SageMaker AI, vous pouvez suivre, organiser et comparer les expériences afin d’identifier les modèles les plus performants. MLflow est intégré aux fonctionnalités de personnalisation des modèles sans serveur Amazon SageMaker AI pour les modèles les plus populaires tels qu’Amazon Nova, Llama, Qwen, DeepSeek et GPT-OSS, vous permettant de visualiser les tâches d’entraînement en cours et les évaluations via une interface unique.

Maintenez la cohérence grâce à une invite rapide
Vous pouvez rationaliser la gestion et l’ingénierie de requête dans vos applications d’IA grâce à MLflow Prompt Registry, une puissante fonctionnalité qui vous permet de versionner, de suivre et de réutiliser les invites au sein de votre organisation, ce qui contribue à maintenir la cohérence et à améliorer la collaboration dans le cadre d’un développement rapide.
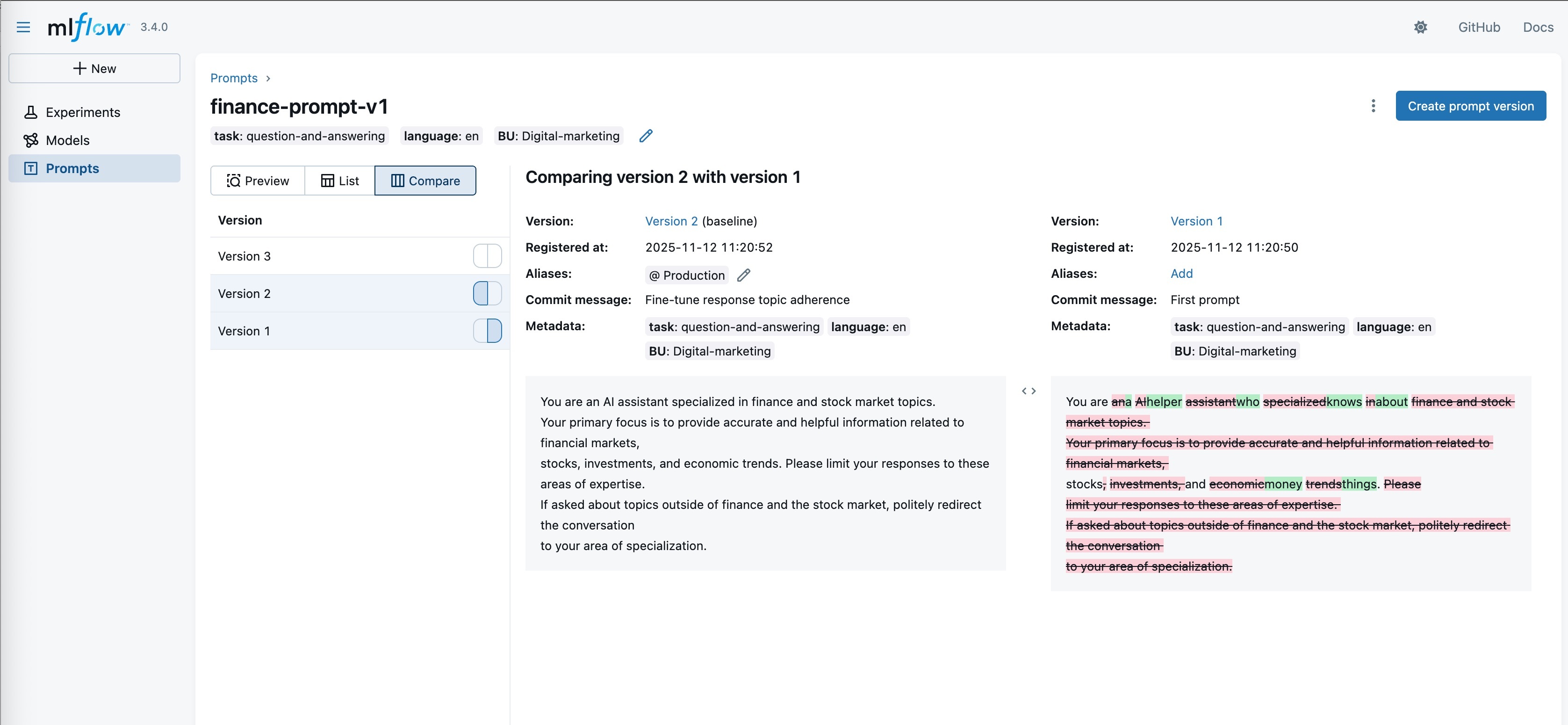
Suivez les applications et les agents d’IA en temps réel
SageMaker AI avec MLflow enregistre les entrées, les sorties et les métadonnées à chaque étape du développement de l’IA afin d’identifier rapidement les bogues ou les comportements inattendus. Grâce au traçage avancé pour les flux de travail agentiques et les applications en plusieurs étapes, vous bénéficierez de la visibilité dont vous avez besoin pour déboguer des systèmes d’IA générative complexes et optimiser les performances.
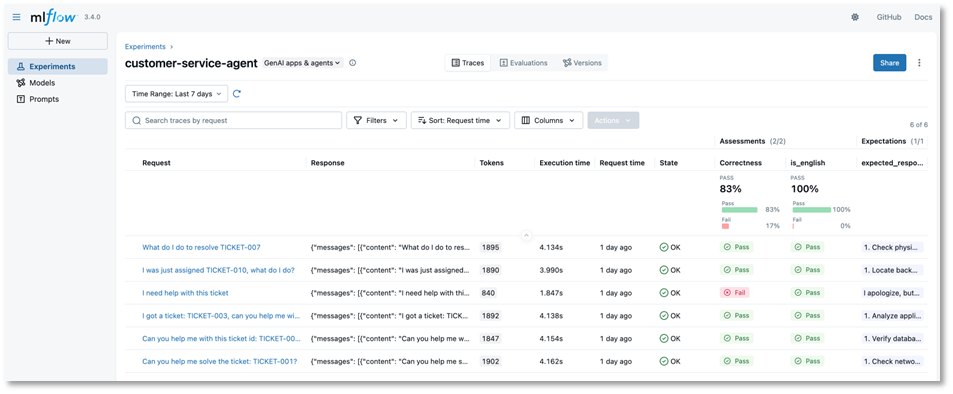
Centralisez la gouvernance des modèles avec le registre de modèles SageMaker
Les entreprises ont besoin d’un moyen simple de suivre tous les modèles candidats au sein des équipes de développement afin de prendre des décisions éclairées quant aux modèles à mettre en production. MLflow géré inclut une intégration spécialement conçue qui synchronise automatiquement les modèles enregistrés dans MLflow avec le registre de modèles SageMaker. Cela permet aux équipes de développement de modèles d’IA d’utiliser des outils distincts pour leurs tâches respectives : MLflow pour l’expérimentation et le registre de modèles SageMaker pour gérer le cycle de vie de production avec un lignage complet des modèles.
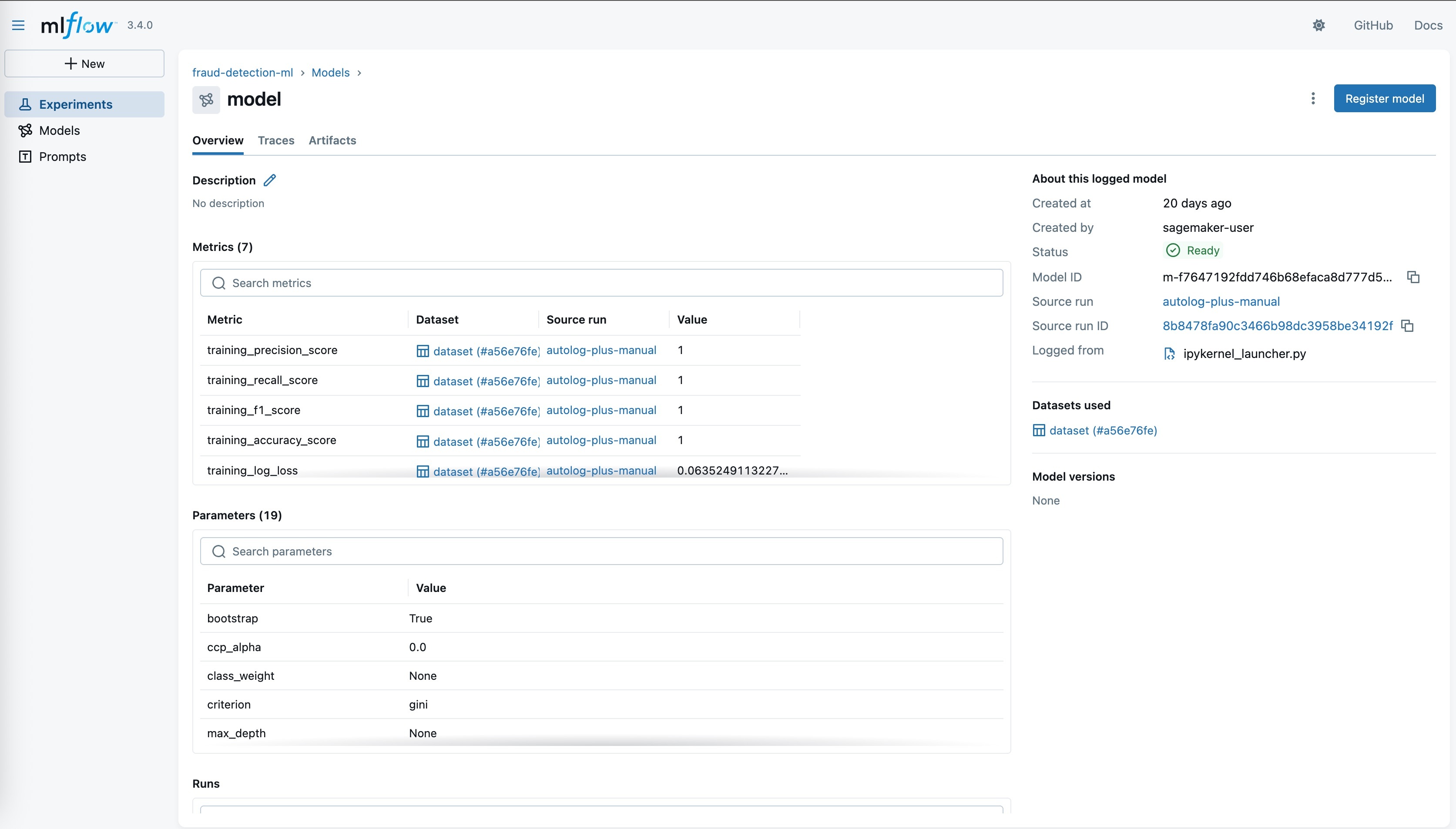
Déployez facilement des modèles sur les points de terminaison SageMaker AI
Une fois que vous avez atteint les objectifs de précision et de performance souhaités, vous pouvez déployer des modèles en production depuis le registre de modèles SageMaker en quelques clics vers les points de terminaison d’inférence SageMaker AI. Cette intégration transparente élimine le besoin de créer des conteneurs personnalisés pour le stockage des modèles et permet aux clients de tirer parti des conteneurs d’inférence optimisés de SageMaker AI tout en conservant l’expérience conviviale de MLflow pour la journalisation et l’enregistrement des modèles.
Société pour la conservation de la faune
« La WCS fait progresser la conservation des récifs coralliens mondiaux grâce à MERMAID, une plateforme open source qui utilise des modèles ML pour analyser des photos de récifs coralliens prises par des scientifiques du monde entier. Amazon SageMaker avec MLflow a amélioré notre productivité en éliminant la nécessité de configurer les serveurs de suivi MLflow ou de gérer la capacité en fonction de l’évolution de nos besoins en matière d’infrastructure. En permettant à notre équipe de se concentrer entièrement sur l’innovation des modèles, nous accélérons le délai de déploiement afin de fournir des informations critiques basées sur le cloud aux scientifiques et aux gestionnaires marins. »
Kim Fisher, MERMAID
Ingénieur logiciel en chef, WCS
