- Amazon SageMaker AI
- Amazon SageMaker HyperPod
- Fonctionnalités
Fonctionnalités Amazon SageMaker HyperPod
Mettez à l’échelle et accélérez le développement de modèles d’IA générative à l’aide de milliers d’accélérateurs d’IA
Entraînement sans point de contrôle
L’entraînement sans point de contrôle sur Amazon SageMaker HyperPod permet une reprise automatique en cas de défaillance d’infrastructure, en quelques minutes seulement et sans intervention manuelle. Il évite le redémarrage des tâches basé sur des points de contrôle souvent nécessaire pour assurer la reprise en cas de défaillance. Ce type de redémarrage fastidieux nécessite de mettre en pause l’ensemble du cluster, de résoudre les problèmes, puis de reprendre à partir d’un point de contrôle enregistré. L’entraînement sans point de contrôle maintient la progression de l’entraînement malgré les défaillances. SageMaker HyperPod remplace automatiquement les composants défectueux et reprend l’entraînement en utilisant un transfert peer-to-peer des états du modèle et de l’optimiseur depuis des accélérateurs d’IA sains. La solution permet d’atteindre plus de 95 % de rendement effectif de l’entraînement sur des clusters de milliers d’accélérateurs d’IA. Grâce à l’entraînement sans point de contrôle, vous pouvez économiser des millions en coûts de calcul, mettre à l’échelle l’entraînement sur des milliers d’accélérateurs d’IA et déployer vos modèles en production plus rapidement.
Entraînement élastique
L’entraînement élastique sur Amazon SageMaker HyperPod met automatiquement à l’échelle les tâches d’entraînement en fonction des ressources de calcul disponibles. Il vous fait gagner plusieurs heures d’ingénierie chaque semaine, auparavant consacrées à la reconfiguration manuelle de ces tâches. La demande en accélérateurs d’IA fluctue constamment. Elle suit le trafic des charges de travail d’inférence, la libération de ressources après les expériences terminées, et l’arrivée de nouvelles tâches d’entraînement qui modifient les priorités en matière de charge de travail. SageMaker HyperPod étend de manière dynamique les tâches d’entraînement en cours pour exploiter les accélérateurs d’IA inactifs et maximiser l’utilisation de l’infrastructure. Lorsque des charges de travail hautement prioritaires, comme l’inférence ou l’évaluation, ont besoin de ressources, l’entraînement est réduit verticalement pour continuer avec moins de ressources, sans jamais s’arrêter complètement. Cela permet de libérer la capacité nécessaire selon les priorités définies par les politiques de gouvernance des tâches. Grâce à l’entraînement élastique, vous pouvez accélérer le développement de vos modèles d’IA tout en minimisant les coûts liés aux ressources de calcul sous-utilisées.
Gouvernance des tâches
Plans d’entraînement flexibles
Instances Spot Amazon SageMaker HyperPod
Les instances Spot sur SageMaker HyperPod vous permettent d’accéder à une capacité de calcul à des coûts considérablement réduits. Les instances Spot sont idéales pour les charges de travail tolérantes aux pannes, telles que les tâches d’inférence par lots. Les prix varient selon la région et le type d’instance, offrant généralement une réduction pouvant aller jusqu’à 90 % par rapport à la tarification à la demande de SageMaker HyperPod. La tarification relative aux instances Spot est définie par Amazon EC2 et ajustée graduellement en fonction des tendances à long terme en matière d’offre et de demande de capacité d’instance Spot. Vous payez le tarif Spot en vigueur pendant la période d’exécution de vos instances, sans engagement préalable requis. Pour en savoir plus sur les prix estimés des instances Spot et leur disponibilité, consultez la page de tarification des instances Spot EC2. Notez que seules les instances également prises en charge sur HyperPod sont disponibles pour une utilisation Spot sur HyperPod.
Recettes optimisées pour personnaliser des modèles
Grâce aux recettes SageMaker HyperPod, les scientifiques des données et les développeurs, quel que soit leur niveau de compétences, bénéficient de performances de pointe et peuvent démarrer en quelques minutes l’entraînement et le peaufinage de modèles de fondation disponibles publiquement, y compris les modèles Llama, Mixtral, Mistral et DeepSeek. En outre, vous pouvez personnaliser les modèles Amazon Nova, notamment Nova Micro, Nova Lite et Nova Pro, en utilisant un ensemble de techniques, telles que le peaufinage supervisé (SFT), la distillation des connaissances, l’optimisation directe des préférences (DPO), l’optimisation proximale de politique et l’entraînement préalable continu. Vous bénéficiez également de la prise en charge des options d’entraînement efficaces en paramètres et portant sur l’ensemble du modèle, pour le SFT, la distillation et la DPO. Chaque recette contient une pile d’entraînement testée par AWS, éliminant ainsi des semaines de travail fastidieux à tester différentes configurations de modèles. Vous pouvez basculer entre les instances basées sur GPU et les instances basées sur AWS Trainium en modifiant la recette en une seule ligne, activer la création de points de contrôle automatique des modèles pour améliorer la résilience de l’entraînement et exécuter des charges de travail en production sur SageMaker HyperPod.
Amazon Nova Forge est un programme unique en son genre qui offre aux entreprises le moyen le plus simple et le plus rentable de créer leurs propres modèles de pointe à l’aide de Nova. Accédez aux points de contrôle intermédiaires des modèles Nova et reprenez l’entraînement à partir de ces points. Combinez les jeux de données sélectionnés par Amazon avec des données exclusives pendant l’entraînement et utilisez les recettes SageMaker HyperPod pour entraîner vos propres modèles. Avec Nova Forge, vous pouvez utiliser vos propres données pour bénéficier d’une intelligence spécifique à vos cas d’utilisation ainsi que des améliorations de performance et de coût pour vos tâches.
Entraînement distribué haute performance
Outils avancés d’observabilité et d’expérimentation
L’observabilité de SageMaker HyperPod fournit un tableau de bord unifié et préconfiguré dans Amazon Managed Grafana, les données de surveillance étant automatiquement publiées dans un espace de travail Amazon Managed Prometheus. Vous pouvez consulter les métriques de performance en temps réel, l’utilisation des ressources et l’état du cluster dans une vue unique, ce qui permet aux équipes de détecter rapidement les goulots d’étranglement, d’éviter des retards coûteux et d’optimiser les ressources de calcul. SageMaker HyperPod est également intégré à Amazon CloudWatch Container Insights, ce qui fournit des données analytiques plus détaillées sur les performances, l’état et l’utilisation des clusters. Le TensorBoard géré dans SageMaker vous permet de gagner du temps sur le développement en visualisant l’architecture du modèle afin d’identifier et de résoudre les problèmes de convergence. MLflow géré dans SageMaker vous permet de gérer efficacement les expériences à grande échelle.
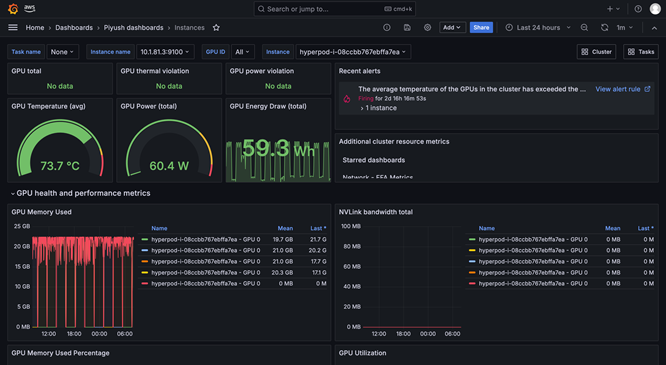
Planification et orchestration des charges de travail
Surveillance de l’état et réparation du cluster automatiques
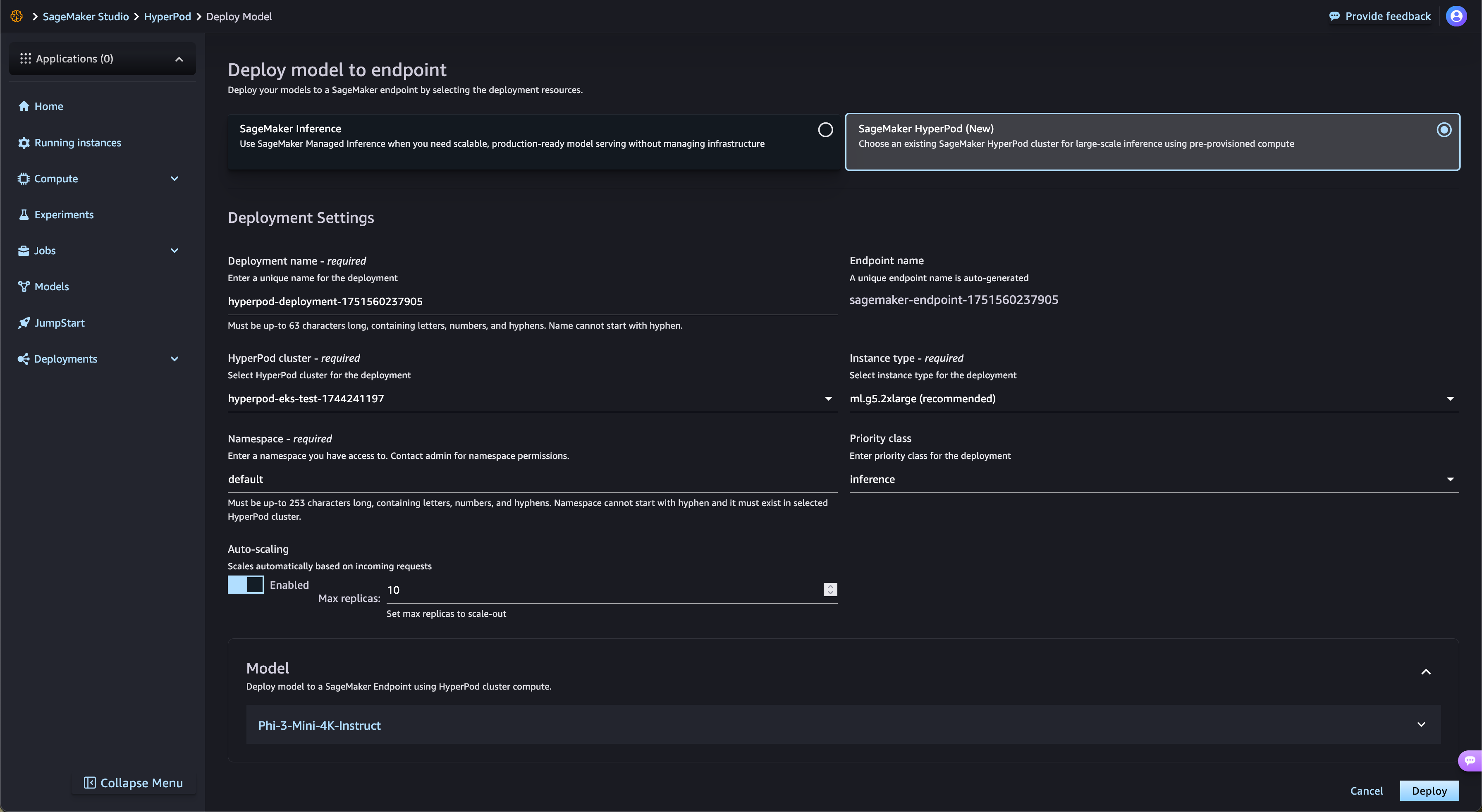
Accélérez les déploiements de modèles à poids ouvert à partir de SageMaker Jumpstart
SageMaker HyperPod rationalise automatiquement le déploiement des modèles de fondation à poids ouvert issus de SageMaker JumpStart et des modèles peaufinés issus d’Amazon S3 et d’Amazon FSx. SageMaker HyperPod provisionne l’infrastructure requise et configure les points de terminaison automatiquement, éliminant ainsi le provisionnement manuel. Grâce à la gouvernance des tâches SageMaker HyperPod, le trafic des points de terminaison est surveillé en permanence et ajuste de manière dynamique les ressources de calcul, tout en publiant simultanément des métriques de performance complètes sur le tableau de bord d’observabilité pour une surveillance et une optimisation en temps réel.
Gestion hiérarchisée des points de contrôle
La gestion hiérarchisée des points de contrôle de SageMaker HyperPod utilise la mémoire CPU pour stocker les points de contrôle fréquents afin d’assurer une reprise rapide, tout en enregistrant périodiquement les données sur Amazon Simple Storage Service (Amazon S3) pour une durabilité à long terme. Cette approche hybride minimise les pertes d’entraînement et réduit considérablement le temps nécessaire pour reprendre l’entraînement après une défaillance. Les clients peuvent configurer la fréquence des points de contrôle et les politiques de conservation sur les niveaux de stockage en mémoire et persistant. En stockant fréquemment des données en mémoire, les clients peuvent effectuer une reprise rapide tout en minimisant les coûts de stockage. Avec l’intégration au point de contrôle distribué (DCP) de PyTorch, les clients peuvent facilement implémenter la gestion des points de contrôle avec seulement quelques lignes de code, tout en bénéficiant des avantages en termes de performances du stockage en mémoire.
Maximisez l’utilisation des ressources avec le partitionnement de GPU
SageMaker HyperPod permet aux administrateurs de partitionner les ressources GPU en unités de calcul plus petites et isolées afin de maximiser l’utilisation du GPU. Vous pouvez exécuter diverses tâches d’IA générative sur un seul GPU au lieu de dédier des GPU entiers à des tâches qui n’utilisent qu’une fraction des ressources. Avec des métriques de performance en temps réel et le suivi de l’utilisation des ressources à travers les partitions GPU, vous obtenez une visibilité complète sur la manière dont les tâches utilisent les ressources de calcul. Cette allocation optimisée et cette configuration simplifiée accélèrent le développement de l’IA générative, améliorent l’utilisation des GPU et permettent une utilisation efficace des ressources GPU pour l’ensemble des tâches et à grande échelle.
Avez-vous trouvé les informations que vous recherchiez ?
Faites-nous part de vos commentaires afin que nous puissions améliorer le contenu de nos pages