Qu'est-ce que l'étiquetage des données ?
Qu'est-ce que l'étiquetage des données ?
Dans l'apprentissage automatique, l'étiquetage des données est le processus qui consiste à identifier les données brutes (images, fichiers texte, vidéos, etc.) et à ajouter une ou plusieurs étiquettes significatives et informatives pour fournir un contexte afin qu'un modèle d'apprentissage automatique puisse en tirer des leçons. Les étiquettes peuvent, par exemple, indiquer si une photo contient un oiseau ou une voiture, quels mots ont été prononcés dans un enregistrement audio ou si une radiographie comporte une tumeur. L'étiquetage des données est requis pour divers cas d'utilisation, notamment la vision par ordinateur, le traitement du langage naturel et la reconnaissance vocale.
Comment fonctionne l'étiquetage des données ?
Aujourd'hui, la plupart des modèles pratiques de machine learning utilisent l'apprentissage supervisé, qui applique un algorithme pour mapper une entrée à une sortie. Pour que l'apprentissage supervisé fonctionne, vous avez besoin d'un jeu de données étiqueté dont le modèle peut tirer des leçons pour prendre les bonnes décisions. L'étiquetage des données commence généralement par demander aux humains de porter un jugement sur une donnée non étiquetée. Par exemple, les étiqueteurs peuvent être invités à baliser toutes les images d'un jeu de données où « la photo contient un oiseau ». Le balisage peut être aussi approximatif qu'un simple oui/non ou aussi précis que l'identification des pixels spécifiques de l'image associée à l'oiseau. Le modèle de machine learning utilise des étiquettes fournies par les humains pour apprendre les modèles sous-jacents dans le cadre d'un processus appelé « entraînement de modèle ». Il en découle un modèle entraîné qui peut être utilisé pour faire des prédictions sur de nouvelles données.
Dans le domaine du machine learning, un jeu de données correctement étiqueté que vous utilisez comme norme objective pour entraîner et évaluer un modèle donné est souvent appelé « vérité terrain ». La précision de votre modèle entraîné dépendra de la précision de votre vérité terrain. Il est donc essentiel de consacrer du temps et des ressources pour garantir un étiquetage des données très précis.
Quels sont les types courants d'étiquetage des données ?
Aide visuelle par ordinateur
Lorsque vous créez un système de vision par ordinateur, vous devez d'abord étiqueter des images, des pixels ou des points clés, ou créer une bordure qui entoure entièrement une image numérique, appelée cadre de délimitation, pour générer votre jeu de données d'entraînement. Par exemple, vous pouvez classer les images par type de qualité (comme les images de produits ou de style de vie) ou par contenu (le contenu réel de l'image elle-même), ou vous pouvez segmenter une image au niveau des pixels. Vous pouvez ensuite utiliser ces données d'entraînement pour créer un modèle de vision par ordinateur qui peut être utilisé pour classer automatiquement les images, détecter l'emplacement des objets, identifier les points clés d'une image ou segmenter une image.
Traitement du langage naturel
Pour le traitement du langage naturel, vous devez d'abord identifier manuellement les sections de texte importantes ou baliser le texte avec des étiquettes spécifiques pour générer votre jeu de données d'entraînement. Par exemple, vous souhaiterez peut-être identifier le sentiment ou l'intention d'un texte de présentation, identifier les parties du discours, classer les noms propres tels que les lieux et les personnes, et identifier le texte dans des images, des PDF ou d'autres fichiers. Pour ce faire, vous pouvez dessiner des cadres de délimitation autour du texte, puis transcrire manuellement le texte dans votre jeu de données d'entraînement. Les modèles de traitement du langage naturel sont utilisés pour l'analyse des sentiments, la reconnaissance des noms d'entités et la reconnaissance optique de caractères.
Traitement audio
Le traitement audio convertit tous les types de sons tels que la parole, les bruits d'animaux (aboiements, sifflements ou gazouillis) et les sons de bâtiments (bris de verre, scans ou alarmes) dans un format structuré qui peut être utilisé dans le cadre du machine learning. Le traitement audio nécessite souvent que vous le transcriviez d'abord manuellement en texte écrit. À partir de là, vous pouvez découvrir des informations plus détaillées sur l'audio en ajoutant des balises et en le classant par catégories. Cet audio classé devient votre jeu de données d'entraînement.
Quelles sont les bonnes pratiques en matière d'étiquetage des données ?
Il existe de nombreuses techniques pour améliorer l'efficacité et la précision de l'étiquetage des données. On compte parmi elles :
- les interfaces de tâches intuitives et rationalisées pour aider à minimiser la charge cognitive et le changement de contexte pour les étiqueteurs humains ;
- les consensus des étiqueteurs pour aider à contrer les erreurs/biais des annotateurs individuels. Le consensus des étiqueteurs consiste à envoyer chaque objet de jeu de données à plusieurs annotateurs, puis à rassembler leurs réponses (appelées « annotations ») dans une seule étiquette.
- le contrôle des étiquettes pour vérifier leur exactitude et les mettre à jour si nécessaire ;
- l'apprentissage actif pour rendre l'étiquetage des données plus efficace en utilisant le machine learning afin d'identifier les données les plus utiles à étiqueter par les humains.
Comment l'étiquetage des données peut-il être effectué de manière efficace ?
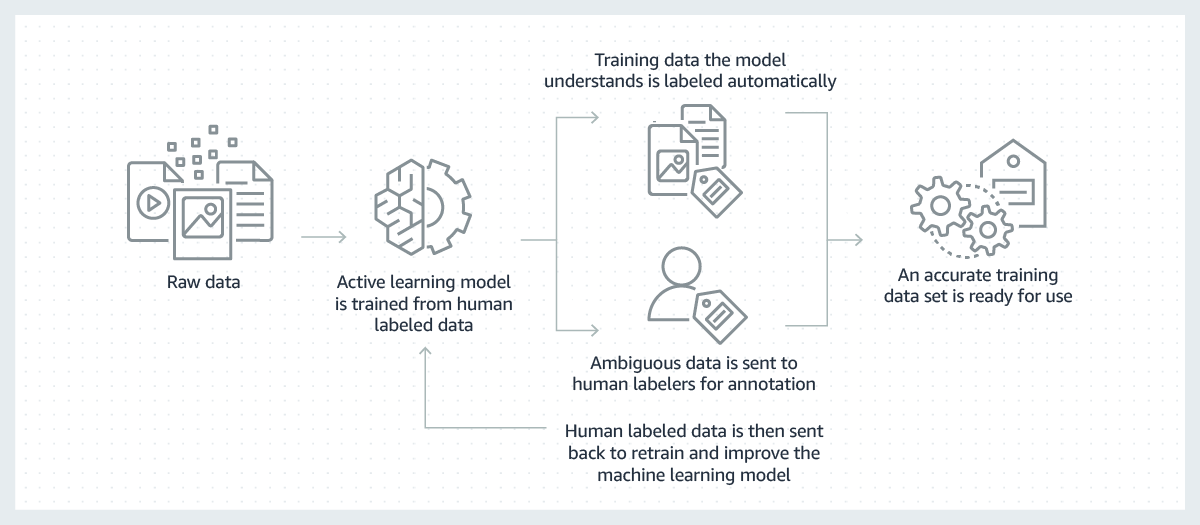
Les modèles de machine learning performants reposent sur de larges volumes de données de formation de haute qualité. Cependant, le processus de création des données de formation nécessaires à la construction de ces modèles est souvent coûteux, compliqué et prend beaucoup de temps. La majorité des modèles créés aujourd'hui nécessitent un utilisateur pour étiqueter manuellement les données de manière à lui permettre d'apprendre à prendre les bonnes décisions. Pour surmonter ce défi, l'étiquetage peut être rendu plus efficace en utilisant un modèle de machine learning pour étiqueter automatiquement les données.
Au cours de ce processus, un modèle de machine learning pour l'étiquetage des données est d'abord entraîné sur un sous-ensemble de vos données brutes qui ont été étiquetées par des humains. Lorsque le modèle d'étiquetage a une grande confiance dans ses résultats, sur la base de ce qu'il a appris jusqu'à présent, il appliquera automatiquement les étiquettes aux données brutes. Lorsque le modèle d'étiquetage a une confiance moindre dans ses résultats, il transmettra les données aux humains pour qu’ils effectuent l'étiquetage. Les étiquettes générées par les humains sont ensuite renvoyées au modèle d'étiquetage afin que celui-ci puisse en tirer des leçons et améliorer sa capacité à étiqueter automatiquement le prochain jeu de données brutes. Au fil du temps, le modèle peut étiqueter de plus en plus de données automatiquement et considérablement accélérer la création de jeux de données d'entraînement.
Comment AWS peut-il prendre en charge vos besoins en matière d'étiquetage des données ?
Amazon SageMaker Ground Truth réduit considérablement le temps et les efforts nécessaires pour créer des jeux de données pour l'entraînement. SageMaker Ground Truth offre un accès aux étiqueteurs humains publiques et privés et leur fournit des flux de travail intégrés ainsi que des interfaces pour les tâches d'étiquetage courantes. Il est facile de commencer à utiliser SageMaker Ground Truth. Le didacticiel de mise en route peut être utilisé pour créer votre première tâche d'étiquetage en quelques minutes.
Démarrer avec l'étiquetage des données sur AWS en créant un compte dès aujourd'hui.
Prochaines étapes sur AWS
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages