- Amazon SageMaker AI
- Amazon SageMaker HyperPod
- Funzionalità
Funzionalità di Amazon SageMaker HyperPod
Scala e velocizza lo sviluppo di modelli di IA generativa su migliaia di acceleratori di IA
Addestramento senza checkpoint
L'addestramento senza checkpoint su Amazon SageMaker HyperPod consente il ripristino automatico dai guasti dell'infrastruttura in pochi minuti senza alcun intervento manuale. Riduce la necessità di un riavvio a livello di processo basato su checkpoint per il ripristino dei guasti, che normalmente richiede la sospensione dell'intero cluster, la risoluzione dei problemi e il ripristino da un checkpoint salvato. L'addestramento senza checkpoint mantiene i progressi dell'addestramento nonostante i guasti, poiché SageMaker HyperPod sostituisce automaticamente i componenti difettosi e riprende l'addestramento utilizzando il trasferimento peer-to-peer degli stati del modello e dell'ottimizzatore da acceleratori IA integri. Consente di addestrare oltre il 95% del goodput su cluster con migliaia di acceleratori di intelligenza artificiale. Con l'addestramento senza checkpoint, risparmierai milioni sui costi di elaborazione, adatterai l'addestramento a migliaia di acceleratori di intelligenza artificiale e porterai i tuoi modelli in produzione più velocemente.
Addestramento elastico
L'addestramento elastico su Amazon SageMaker HyperPod scala automaticamente i job di addestramento in base alla disponibilità di risorse di calcolo, risparmiando ore di progettazione a settimana che in precedenza venivano impiegate per riconfigurare i job di addestramento. La domanda di acceleratori di intelligenza artificiale oscilla costantemente man mano che i carichi di lavoro di inferenza si adattano ai modelli di traffico, gli esperimenti completati rilasciano risorse e i nuovi job di addestramento spostano le priorità dei carichi di lavoro. SageMaker HyperPod espande dinamicamente i job di addestramento in esecuzione per assorbire gli acceleratori IA inattivi, massimizzando l'utilizzo dell'infrastruttura. Quando i carichi di lavoro con priorità più alta, come l'inferenza o la valutazione, richiedono risorse, l'addestramento viene ridotto verticalmente in modo da continuare con meno risorse senza fermarsi completamente, ottenendo la capacità richiesta in base alle priorità stabilite attraverso policy di governance delle attività. L'addestramento elastico ti aiuta ad accelerare lo sviluppo del modello di intelligenza artificiale riducendo al contempo i costi eccessivi dovuti all'elaborazione sottoutilizzata.
Governance delle attività
Piani di addestramento flessibili
Istanze spot di Amazon SageMaker HyperPod
Le istanze spot su SageMaker HyperPod consentono di accedere alla capacità di calcolo a costi notevolmente ridotti. Le istanze Spot sono ideali per carichi di lavoro a tolleranza di guasti, come i processi di inferenza in batch. I prezzi variano in base all'area geografica e al tipo di istanza e in genere offrono uno sconto fino al 90% rispetto ai prezzi on demand di SageMaker HyperPod. I prezzi delle istanze Spot sono stabiliti da Amazon EC2 e regolati in modo graduale in base ai trend a lungo termine dell'offerta e della domanda di capacità dell'istanza Spot. Pagherai il prezzo dell'istanza spot in vigore per il periodo di tempo in cui sono in esecuzione le istanze, senza alcun impegno iniziale. Per saperne di più sui prezzi stimati e sulla disponibilità delle istanze spot, visita la pagina dei prezzi delle istanze Spot EC2. Tieni presente che solo le istanze supportate anche su HyperPod sono disponibili per l'utilizzo di spot su HyperPod.
Ricette ottimizzate per la personalizzazione dei modelli
Le ricette di SageMaker HyperPod consentono ai data scientist e agli sviluppatori in possesso di tutte le competenze di beneficiare di prestazioni all'avanguardia, mentre iniziano rapidamente ad addestrare ed eseguire il fine-tuning dei modelli di IA generativa disponibili al pubblico, tra cui Llama, Mixtral, Mistral e and DeepSeek. Inoltre, è possibile personalizzare i modelli di Amazon Nova, tra cui Nova Micro, Nova Lite e Nova Pro con l'utilizzo di una suite di tecniche tra cui Supervised Fine-Tuning (SFT), Knowledge Distillation, Direct Preference Optimization (DPO), Proximal Policy Optimization e Continued Pre-Training, avendo a disposizione il supporto sia per l'efficienza dei parametri sia per opzioni di addestramento dei modelli completo durante l'esecuzione di SFT, Distillation e DPO. Ogni ricetta include uno stack di addestramento che è stato testato da AWS e consente di risparmiare settimane di noioso lavoro testando diverse configurazioni di modelli. Puoi passare da istanze basate su GPU a istanze basate su AWS Trainium con una modifica di ricetta di una riga e abilitare il checkpoint automatico dei modelli per una migliore resilienza di addestramento, oltre ad eseguire carichi di lavoro in produzione su SageMaker HyperPod.
Amazon Nova Forge è un programma unico nel suo genere che offre alle organizzazioni il modo più semplice ed economico per creare i propri modelli di frontiera utilizzando Nova. Accedi ed esegui l'addestramento da checkpoint intermedi dei modelli Nova, combina set di dati curati da Amazon con dati proprietari durante l'addestramento e usa le ricette SageMaker HyperPod per addestrare i tuoi modelli. Con Nova Forge puoi utilizzare i tuoi dati aziendali per sbloccare informazioni specifiche sui casi d'uso e miglioramenti del rapporto prezzo/prestazioni per le tue attività.
Librerie di addestramento distribuite ad alte prestazioni
Strumenti avanzati di osservabilità e sperimentazione
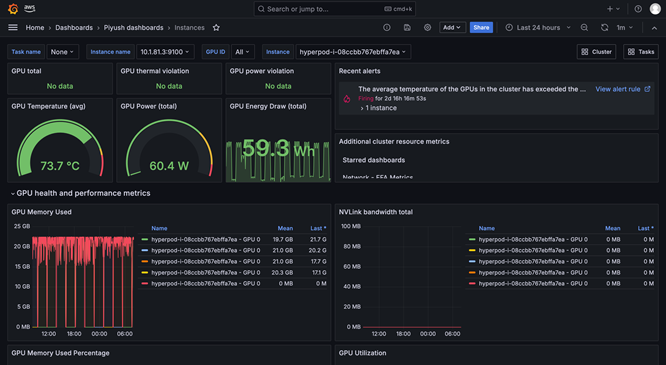
L'osservabilità di SageMaker HyperPod fornisce una dashboard unificata preconfigurata in Grafana gestito da Amazon, dove i dati di monitoraggio pubblicati automaticamente in uno spazio di lavoro Amazon Managed Prometheus. Puoi vedere i parametri delle prestazioni in tempo reale, l'utilizzo delle risorse e lo stato dei cluster in un'unica visualizzando e ciò consente ai team di individuare rapidamente i colli di bottiglia, impedire ritardi costosi e ottimizzare le risorse di calcolo. SageMaker HyperPod si integra anche con gli approfondimenti sui container Amazon CloudWatch, offrendo informazioni più approfondite sulle prestazioni, sull'integrità e sull'utilizzo del cluster. Managed TensorBoard in SageMaker ti aiuta a risparmiare tempo di sviluppo tramite la visualizzazione dell'architettura del modello per identificare e risolvere i problemi di convergenza. Managed MLflow in SageMaker aiuta a gestire in modo efficiente gli esperimenti su vasta scala.
Pianificazione e orchestrazione del carico di lavoro
Controllo dell'integrità e riparazione automatici del cluster
Accelera l'implementazione dei modelli a peso aperto con SageMaker Jumpstart
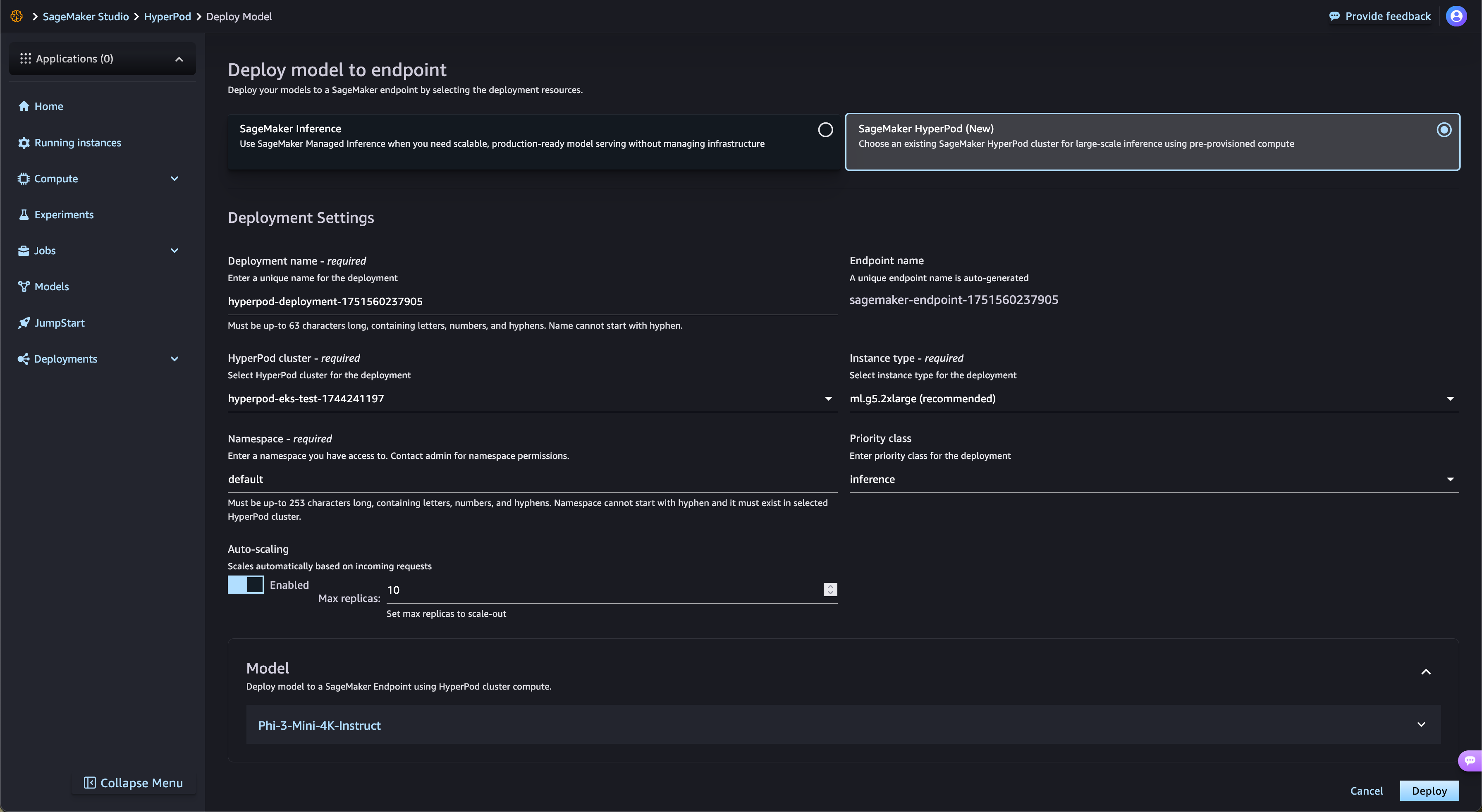
SageMaker HyperPod semplifica in modo automatico l'implementazione dei modelli di fondazione a peso aperto di SageMaker JumpStart e dei modelli ottimizzati con fine-tuning di Amazon S3 e Amazon FSx. SageMaker HyperPod esegue automaticamente il provisioning dell'infrastruttura richiesta e configura gli endpoint, eliminando il provisioning manuale. Con la governance delle attività di SageMaker HyperPod, il traffico degli endpoint viene monitorato continuamente e regola in modo dinamico le risorse di calcolo, pubblicando al contempo metriche complete sulle prestazioni nella dashboard di osservabilità, per il monitoraggio e l'ottimizzazione in tempo reale.
Checkpoint gestito su più livelli
Il checkpointing gestito su più livelli di SageMaker HyperPod utilizza la memoria CPU per archiviare checkpoint frequenti che consentono un ripristino rapido, salvando periodicamente i dati su Amazon Simple Storage Service (Amazon S3) per garantire durabilità a lungo termine. Questo approccio ibrido riduce al minimo la perdita dei progressi di addestramento e diminuisce significativamente il tempo necessario per riprendere le sessioni interrotte. I clienti possono configurare la frequenza dei checkpoint e i criteri di conservazione sia per i livelli di archiviazione in memoria che per quelli persistenti. Archiviando frequentemente i dati in memoria, i clienti possono garantire un ripristino immediato e ridurre al minimo i costi di archiviazione. Integrato con il Checkpoint distribuito (DCP) di PyTorch, i clienti possono implementare facilmente il checkpointing con poche righe di codice, beneficiando al contempo delle prestazioni elevate dell'archiviazione in memoria.
Massimizza l'utilizzo delle risorse con il partizionamento della GPU
SageMaker HyperPod consente agli amministratori di partizionare le risorse GPU in unità di calcolo più piccole e isolate per massimizzare l'utilizzo della GPU. Puoi eseguire diverse attività di IA generativa su una singola GPU invece di dedicare GPU complete ad attività che richiedono solo una frazione delle risorse. Con i parametri delle prestazioni in tempo reale e il monitoraggio dell'utilizzo delle risorse su tutte le partizioni GPU, ottieni visibilità su come le attività utilizzano le risorse di calcolo. Questa allocazione ottimizzata e la configurazione semplificata accelerano lo sviluppo dell'IA generativa, migliorano l'utilizzo della GPU e offrono un utilizzo efficiente delle risorse GPU tra le attività su larga scala.
Hai trovato quello che cercavi?
Facci sapere la tua opinione in modo da migliorare la qualità dei contenuti delle nostre pagine