- 생성형 AI›
- Amazon Bedrock›
- 평가
Amazon Bedrock 평가 도구 세트
사용자 지정 모델 및 가져온 모델을 비롯해서 파운데이션 모델을 평가하여 요구 사항에 맞는 모델을 찾을 수 있습니다. 또한 Amazon Bedrock Knowledge Bases에서 검색 또는 엔드 투 엔드 RAG 워크플로를 평가할 수 있습니다.
개요
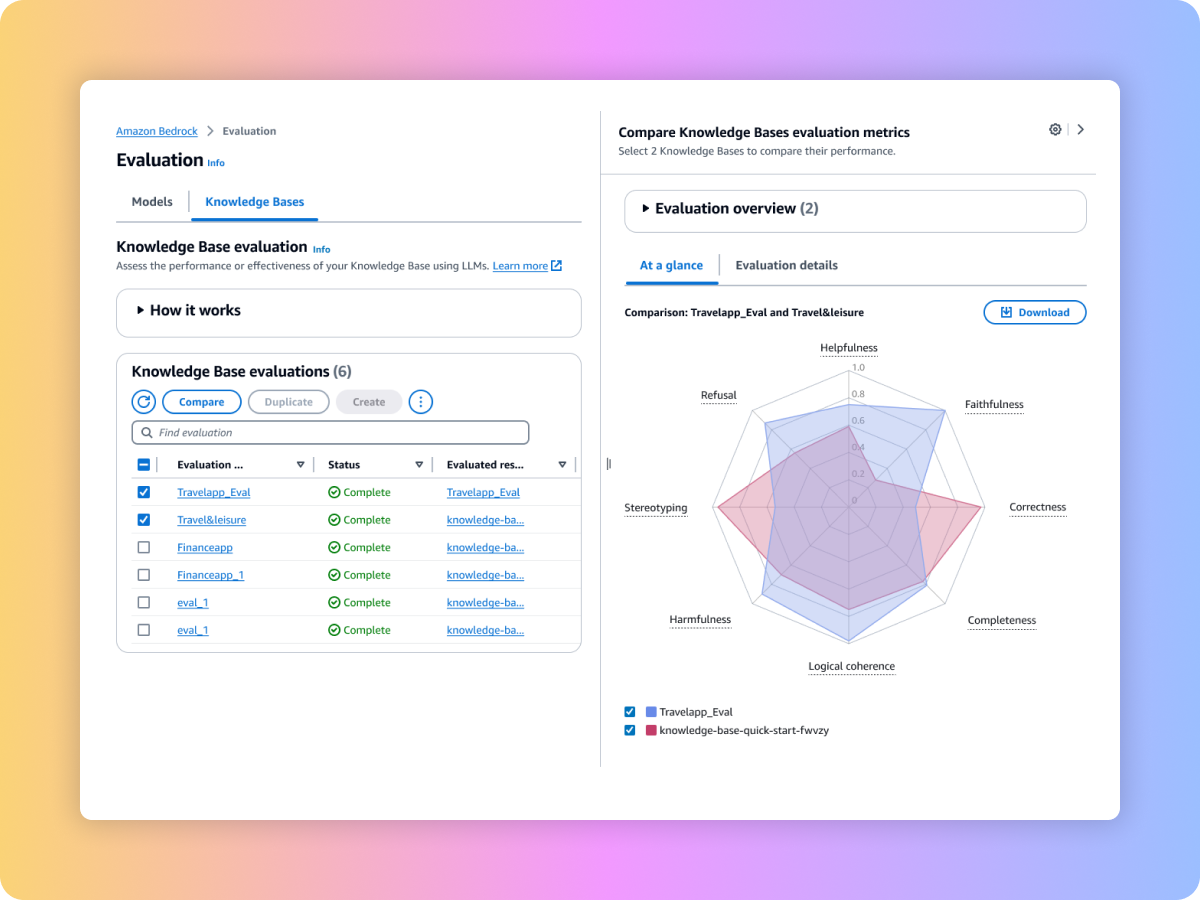
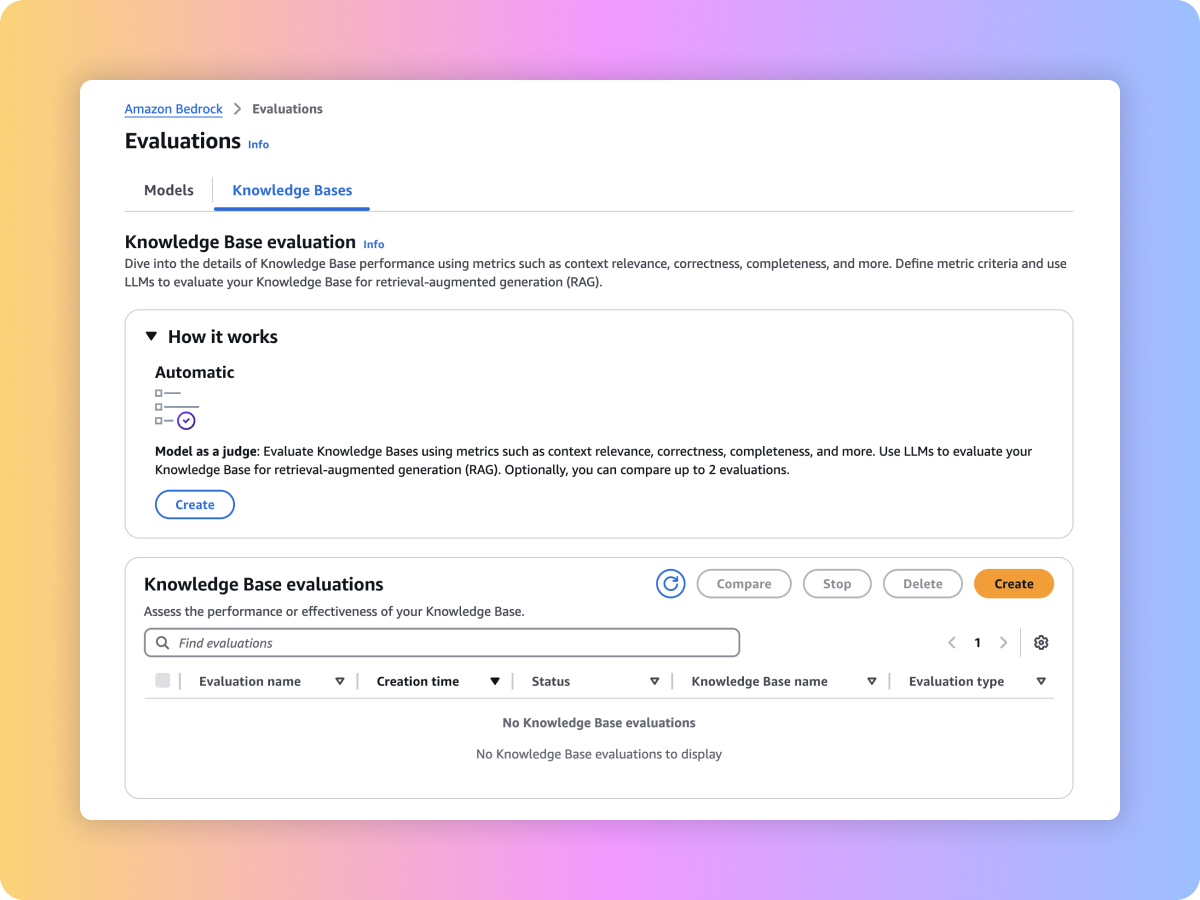
Amazon Bedrock은 생성형 AI 애플리케이션의 도입을 가속화할 수 있는 평가 도구를 제공합니다. 모델 평가를 통해 사용 사례에 맞는 파운데이션 모델을 평가, 비교 및 선택할 수 있습니다. 검색 함수 또는 검색 및 생성 기능을 평가하여 Amazon Bedrock Knowledge Bases 또는 사용자 지정 RAG 시스템에 구축된 프로덕션에 사용할 RAG 애플리케이션을 준비하세요.
평가 유형
평가형 LLM을 사용하여 정확성, 완전성, 유해성과 같은 지표가 포함된 사용자 지정 프롬프트 데이터세트로 모델 출력을 평가할 수 있습니다.
기존의 자연어 알고리즘과 BERT Score, F1 등의 지표와 기타 정확한 매칭 기법을 통해 내장된 프롬프트 데이터세트를 사용하거나 직접 가져와 모델 출력을 평가합니다.
자체 인력과 함께 모델 출력을 평가하거나, 기본 제공 또는 사용자 지정 지표를 사용하여 사용자 지정 프롬프트 데이터세트 관련 응답에 대한 평가를 AWS에서 관리하도록 할 수 있습니다.
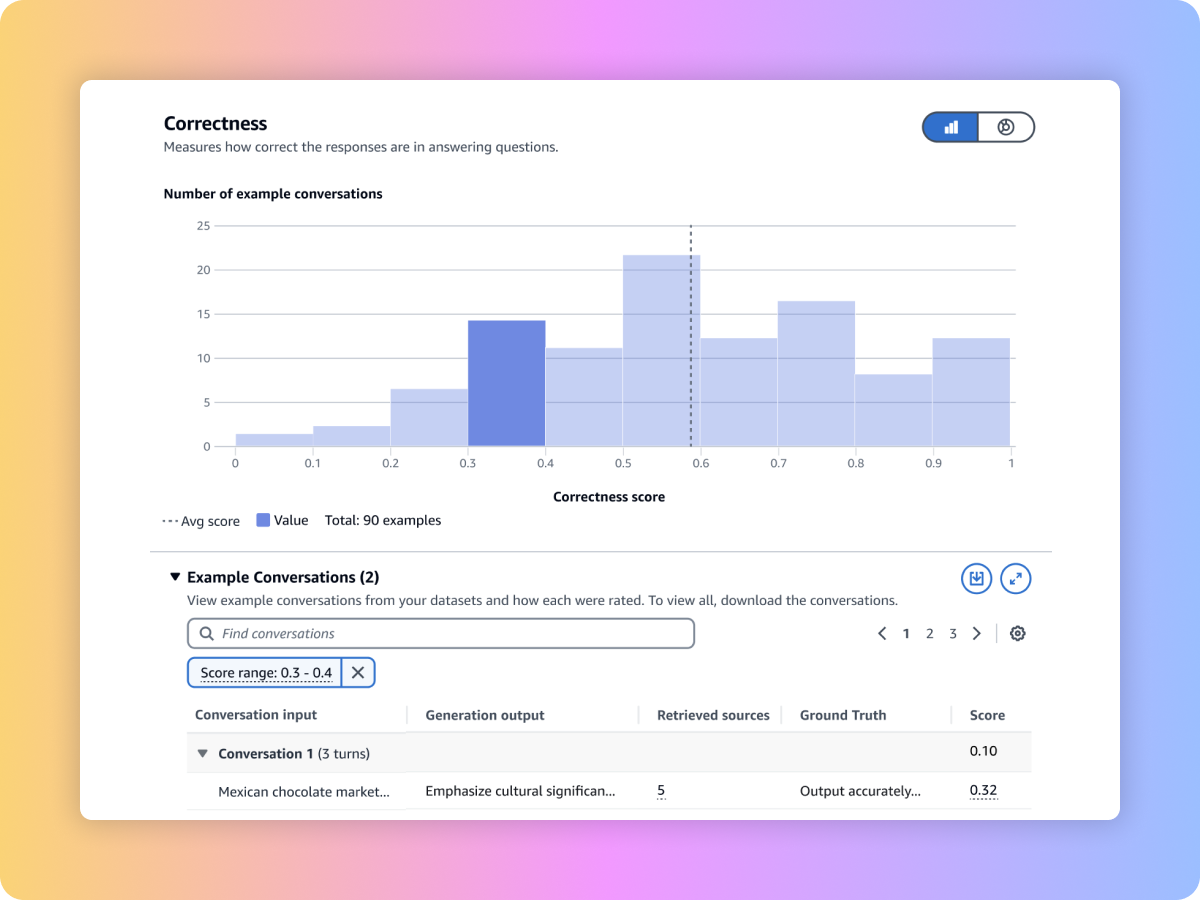
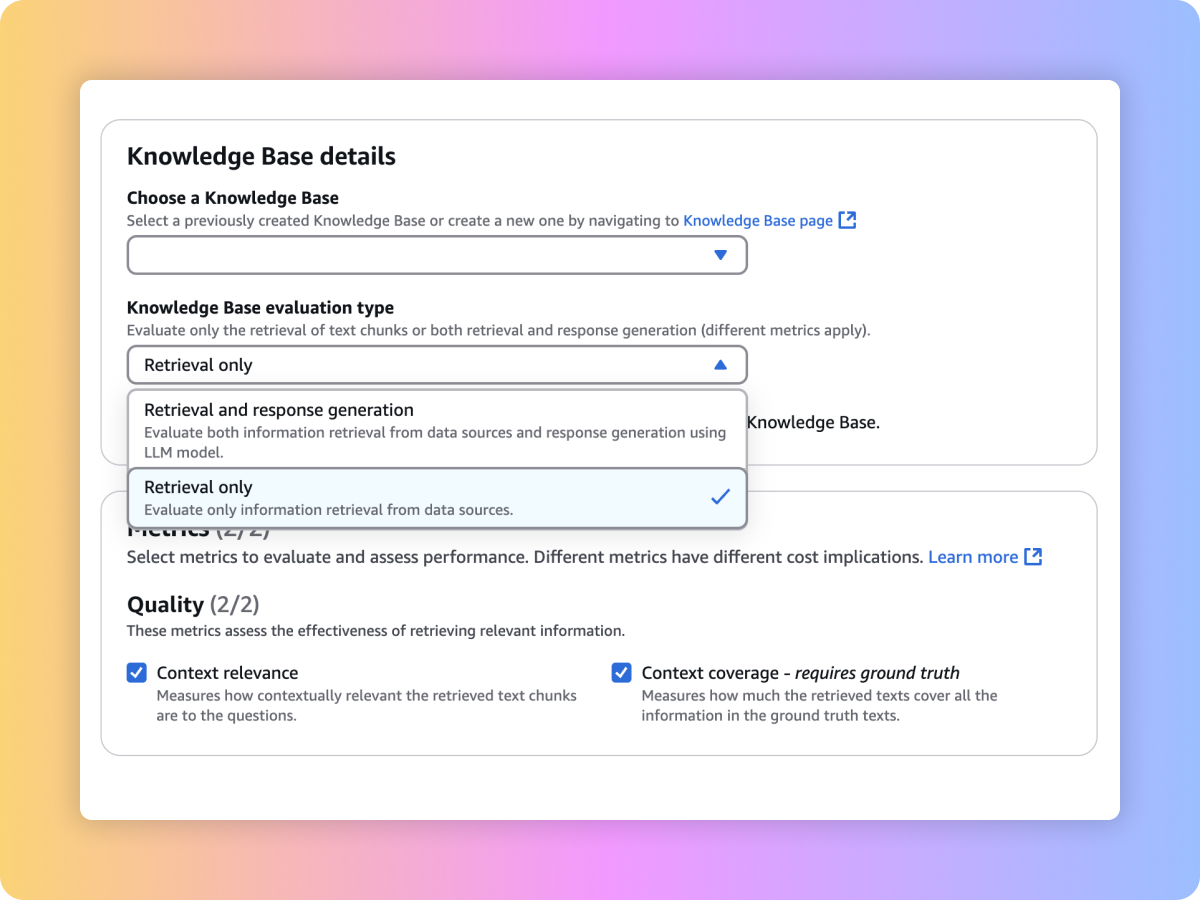
컨텍스트 관련성 및 컨텍스트 범위 같은 프롬프트와 지표를 사용하여 사용자 지정 RAG 시스템 또는 Amazon Bedrock Knowledge Bases의 검색 품질을 평가할 수 있습니다.
사용자 지정 RAG 파이프라인 또는 Amazon Bedrock Knowledge Bases에서 엔드 투 엔드 RAG 워크플로의 생성된 콘텐츠를 평가할 수 있습니다. 사용자 자체 프롬프트 및 충실도(할루시네이션 탐지), 정확성, 완전성 등과 같은 지표를 사용해 보세요.
엔드 투 엔드 RAG 워크플로 평가
RAG 시스템에서 완전하고 연관성 높은 검색 보장
FM을 평가하여 사용 사례에 가장 적합한 FM 선택
여러 평가 작업의 결과를 비교하여 더 빠르게 결정을 내릴 수 있습니다.