Amazon Redshift 데이터 공유
데이터를 복사하지 않고 웨어하우스 간에 안전하게 데이터를 공유
장점
-
Amazon Redshift 데이터베이스의 데이터를 여러 웨어하우스에서 사용할 수 있습니다. 하나의 웨어하우스를 사용하여 데이터를 추출, 전환, 적재(ETL)하여 조직 내부 및 AWS 리전 전체에서 데이터에 액세스할 수 있습니다. 데이터를 여러 곳으로 이동시키는 여러 파이프라인을 구축하고 유지할 필요가 없습니다.
-
다양한 크기(노드 또는 RPU), 유형(프로비저닝된 인스턴스와 서버리스), 요금제(온디맨드 인스턴스와 예약형 인스턴스) 등 원하는 컴퓨팅으로 데이터에 액세스할 수 있습니다. 팀, 애플리케이션 또는 워크로드의 가격 대비 성능 요구 사항을 기반으로 웨어하우스를 선택하세요. 팀별 사용량 추적 및 모니터링을 통해 비용을 관리하고 투명성을 개선
-
데이터를 한 위치에서 다른 위치로 이동하거나 복사할 필요가 없으므로 데이터 사일로와 데이터 중복이 제거됩니다. 소스 지점에서 라이브 데이터로 협업하여 데이터에 대한 조치를 신속하게 취할 수 있습니다. 액세스는 AWS Lake Formation을 통해 중앙에서 관리되므로 세분화된 액세스 제어가 가능합니다.
-
수동 라이선스 프로세스를 거치거나 웨어하우스에서 ETL 작업을 수행할 필요 없이 서드 파티 제공업체의 데이터에 안전하고 쉽게 액세스할 수 있습니다. Amazon Redshift에서 AWS Data Exchange의 데이터 세트를 구독하기만 하면 됩니다. 데이터 제공업체는 클릭 몇 번으로 고객 웨어하우스에서 데이터를 사용할 수 있게 함으로써 데이터로 수익을 창출하고 고객에게 가치를 제공할 수 있습니다.
Amazon Redshift 데이터 공유
Amazon Redshift 데이터 공유를 사용하면 데이터를 이동하거나 복사하지 않고도 조직, AWS 리전 및 타사 제공업체 내부와 간에 데이터를 공유할 수 있습니다. 여러 데이터 웨어하우스를 사용하여 동일한 Redshift 데이터베이스에서 읽고 쓸 수 있으며 Amazon Redshift가 제공하는 사용 편의성, 성능 및 비용 이점을 다중 웨어하우스, 데이터 메시 아키텍처로 확장합니다. 조직 내부 및 조직 전체에서 실시간 최신 데이터에 즉시 액세스할 수 있도록 하여 여러 추출, 전환, 적재(ETL) 파이프라인을 제거하고, 데이터에 대한 협업을 활성화하고, 인사이트 확보 시간을 단축할 수 있습니다. 또한 ETL에 다양한 유형/크기의 여러 웨어하우스를 사용할 수 있으므로 쓰기 워크로드의 가격 대비 성능 요구 사항에 따라 웨어하우스를 조정할 수 있습니다. Amazon Redshift 사용자는 수천 개의 타사 데이터 세트를 수용하는 AWS Marketplace인 AWS Data Exchange와의 통합을 통해 쉽고 안전하게 타사 데이터 세트에 라이선스를 부여하여 Redshift 데이터베이스의 데이터와 결합함으로써 전체적인 분석을 수행하고 새로운 데이터 수익 창출 기회를 창출할 수 있습니다.
사용 사례
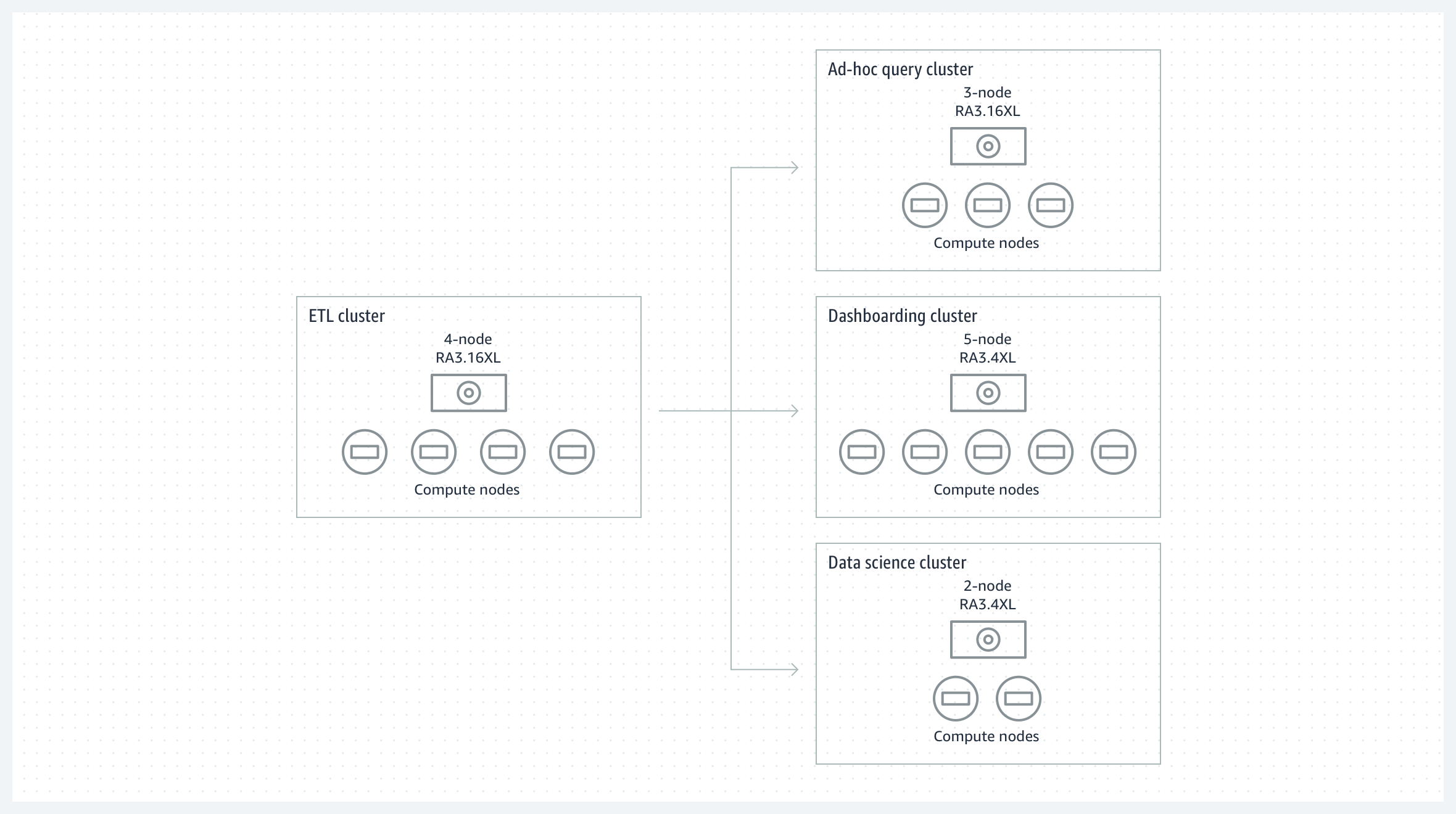
워크로드 격리 및 요금 부과
ETL 클러스터의 데이터를 허브-스포크 아키텍처에 있는 다수의 격리된 BI 및 분석 클러스터와 공유하여 읽기 워크로드 격리와 선택적 요금 차지백을 제공할 수 있습니다. 각 분석 클러스터의 크기를 가성비 요구 사항에 따라 조정할 수 있고 새 워크로드를 손쉽게 온보딩할 수 있습니다.
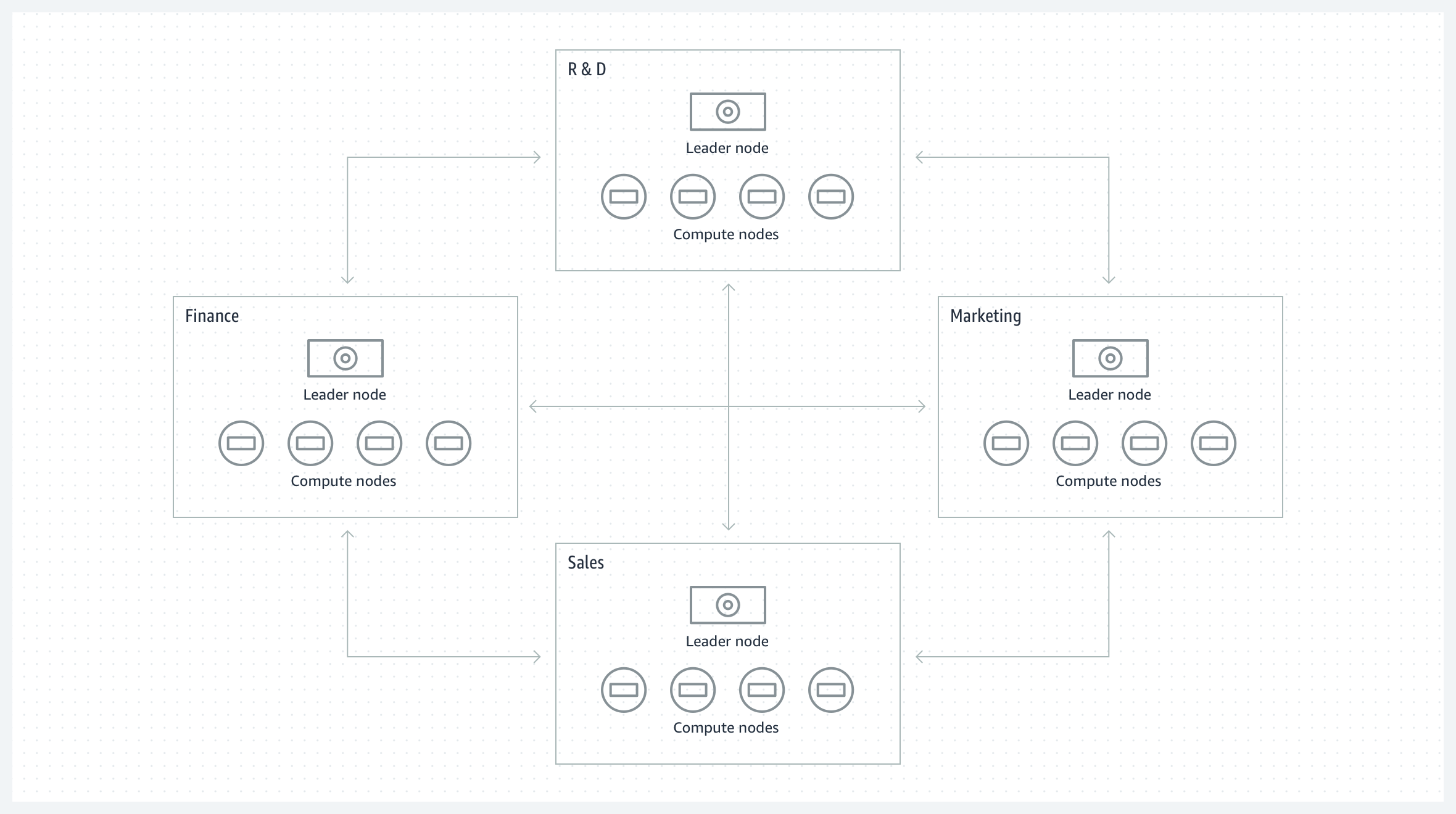
그룹 간 협업
개별 Amazon Redshift 클러스터를 유지 관리하는 여러 비즈니스 그룹 간에 데이터를 공유하여 더 넓은 범위의 분석 및 데이터 과학 작업에서 협업할 수 있습니다. 각 Amazon Redshift 클러스터를 일부 데이터의 생산자로 사용하고 다른 데이터 집합의 소비자로 사용할 수 있습니다.
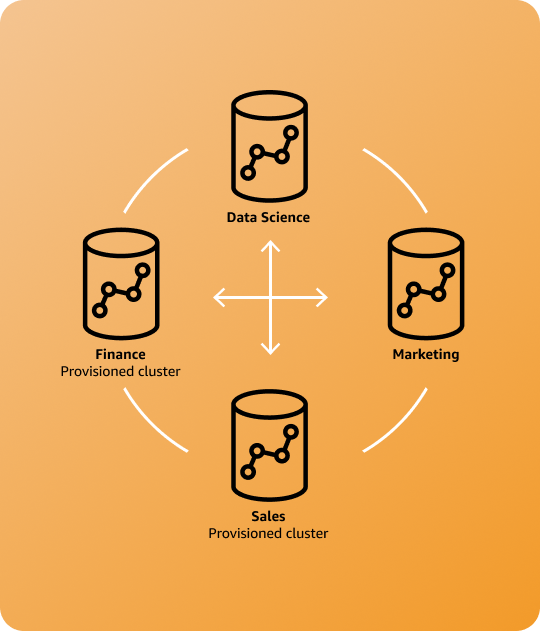
서비스형 데이터 및 분석
조직의 여러 그룹 및 조직 경계 외부의 외부 당사자와 데이터를 서비스 형태로 공유할 수 있습니다.

개발 민첩성
몇 번의 클릭만으로 다양한 유형과 크기의 다양한 프로비저닝된 클러스터와 서버리스 워크그룹 간에 데이터를 읽고 쓸 수 있습니다.
