How was this content?
Serverless Retrieval Augmented Generation (RAG) on AWS
In the evolving landscape of generative AI, integrating external, up-to-date information into large language models (LLMs) presents a significant advancement. In this post, we’re going to build up to a truly serverless Retrieval Augmented Generation (RAG) solution, facilitating the creation of applications that produce more accurate and contextually relevant responses. Our goal is to help you create your GenAI powered application as fast as possible, keeping an eye on your costs, and making sure you don’t pay for compute you’re not using.
Serverless RAG: an overview
Serverless RAG combines the advanced language processing capabilities of foundational models with the agility and cost-effectiveness of serverless architecture. This integration allows for the dynamic retrieval of information from external sources—be it databases, the internet, or custom knowledge bases—enabling the generation of content that is not only accurate and contextually rich but also up-to-date with the latest information.
Amazon Bedrock simplifies the deployment of serverless RAG applications, offering developers the tools to create, manage, and scale their GenAI projects without the need for extensive infrastructure management. In addition to that, developers can harness the power of AWS services like Lambda and S3, alongside innovative open-source vector databases such as LanceDB, to build responsive and cost-effective AI-driven solutions.
Ingesting documents
The journey to your serverless RAG solution involves several key steps, each tailored to ensure the seamless integration of foundational models with external knowledge.
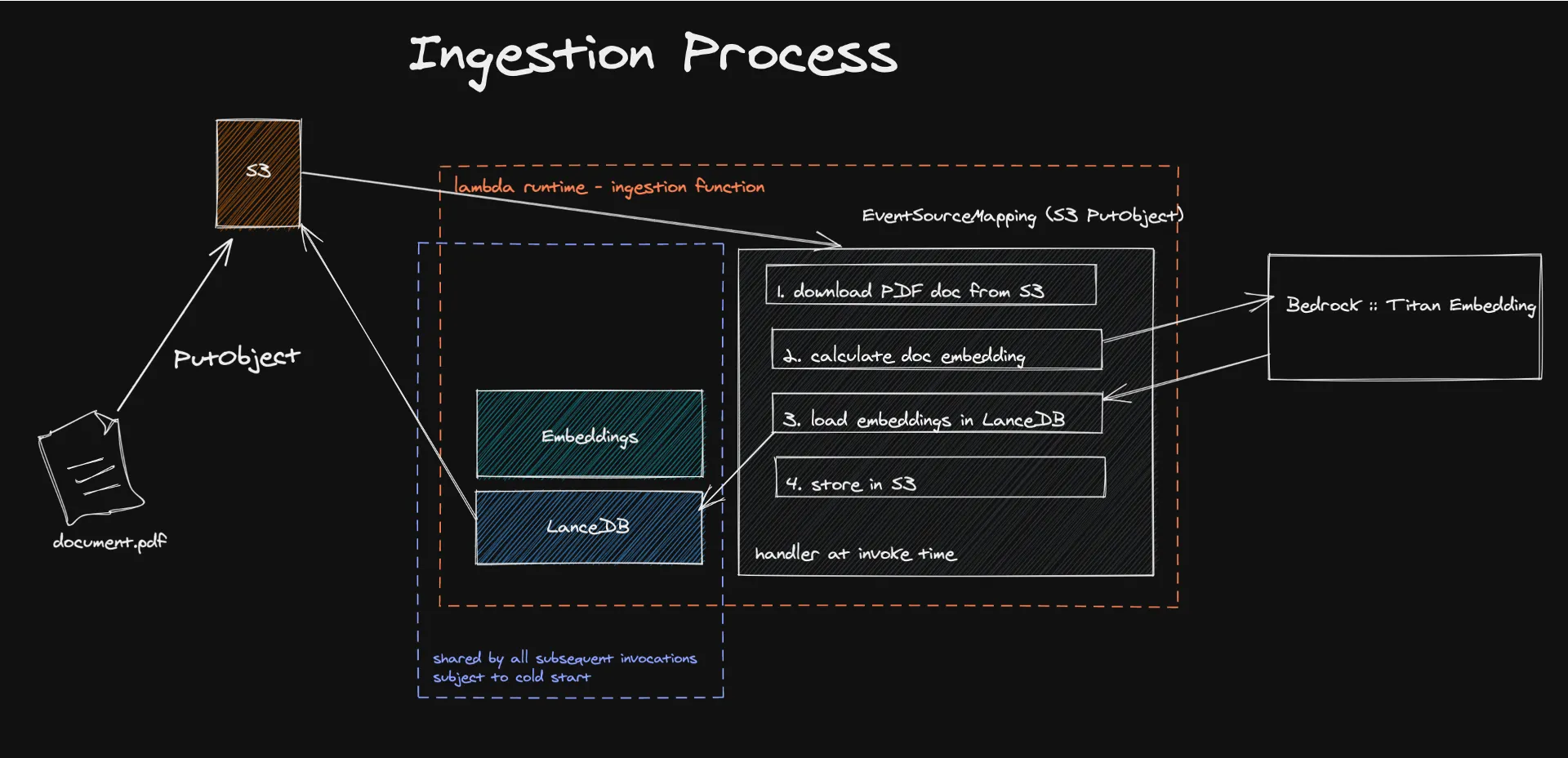
The process starts with the ingestion of documents into a serverless architecture, where event-driven mechanisms trigger the extraction and processing of textual content to generate embeddings. These embeddings, created using models like Amazon Titan, transform the content into numerical vectors that machines can easily understand and process.
Storing these vectors in LanceDB, a serverless vector database backed by Amazon S3, facilitates efficient retrieval and management, ensuring that only relevant information is used to augment the LLM's responses. This approach not only enhances the accuracy and relevance of generated content but also significantly reduces operational costs by leveraging a pay-for-what-you-use model.
Have a look at the code here.
What are embeddings?
In the realm of Natural Language Processing (NLP), embeddings are a pivotal concept that enable the translation of textual information into numerical form that machines can understand and process. It’s a way to translate semantic relationships into geometric relationships, something that computers can understand way better than human language. Essentially, through embedding, we’ll transform the content of a document into vectors in a high dimensional space. This way, geometric distance in this space assumes a semantic meaning. In this space, vectors representing different concepts will be far from each other, and similar concepts will be grouped together.
This is achieved through models like Amazon Titan Embedding which employs neural networks trained on massive corpora of text to calculate the likelihood of groups of words to appear together in various contexts.
Luckily you don’t have to build this system from scratch. Bedrock is there to provide access to embedding models, as well as to other foundational models.
I’ve embedded my knowledge base, now what?
You need to store them somewhere! A vector database, to be precise. And this is where the truly serverless magic happens.
LanceDB is an open-source vector database designed for vector-search with persistent storage, simplifying retrieval, filtering, and management of embeddings. The standout feature for us was the ability to connect LanceDB directly to S3. This way we don’t need idle computing. We’ll use the database only while the lambda function is running. Our load tests have shown that we can ingest documents up to 500MB in size without LanceDB, Bedrock, or Lambda breaking a sweat.
A known limitation of this system are Lambda cold starts, but we have measured that the process that takes the majority of time is actually the calculation of embeddings, which happens outside of Lambda. We have measured that our userbase is affected by cold start only in 10% of the cases. To mitigate this, you can think of creating batch jobs in a next phase of an MVP and potentially make use of other serverless AWS services such as Batch or ECS Fargate, taking advantage of Spot pricing too to save even further.
Querying
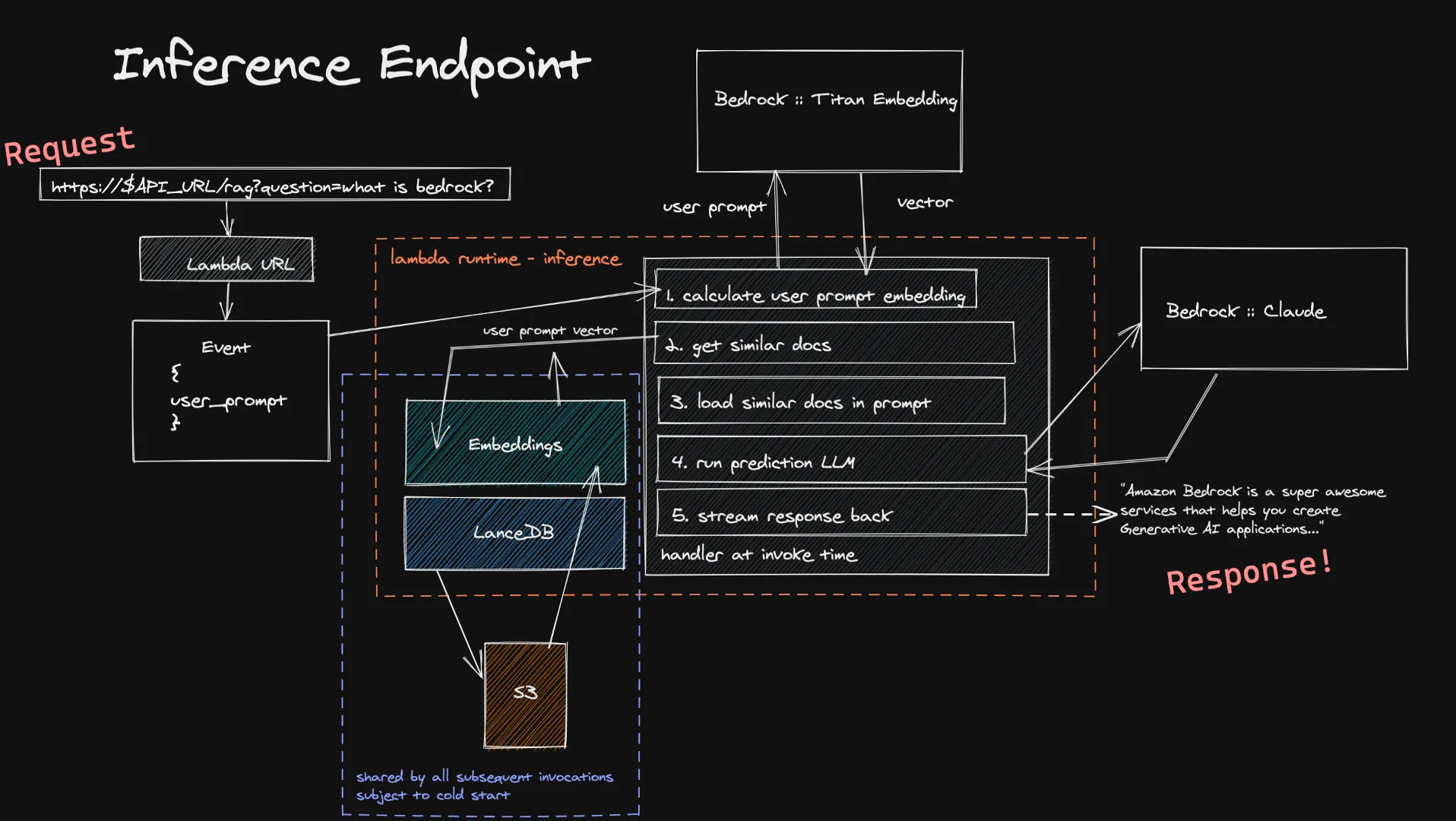
Users can forward their input to our Inference function via Lambda URL. This is fed into Titan Embedding model via Bedrock, which calculates a vector. We then use this vector to source a handful of similar documents in our vector databases, and we add them to the final prompt. We send the final prompt to the LLM the user chose and, if it supports streaming, the response is streamed back in real time to the user. Again we do not have long-running idle computation here, and because the user input is usually smaller than the documents we ingest, you can expect shorter times for the calculation of its embedding.
A known limitation of this inference system is cold-starting-up our vector database within a new Lambda function. Since LanceDB references a database stored in S3, when a new Lambda execution environment is created - we have to load in the database to be able to make our vector searches. This only happens when you’re scaling up or nobody has asked a question in awhile, which means it’s a rather small trade-off for the cost-savings of a fully serverless architecture.
Have a look at the code here.
Navigating the Economics of Serverless RAG
Understanding the cost implications is crucial for adopting serverless RAG. Amazon Bedrock's pricing model, based on token usage and serverless resource consumption, allows developers to estimate costs accurately. Whether processing documents for embedding or querying the model for responses, the pay-as-you-go pricing ensures that costs are directly tied to usage, so that you pay only for what you use.

Ingestion Economics
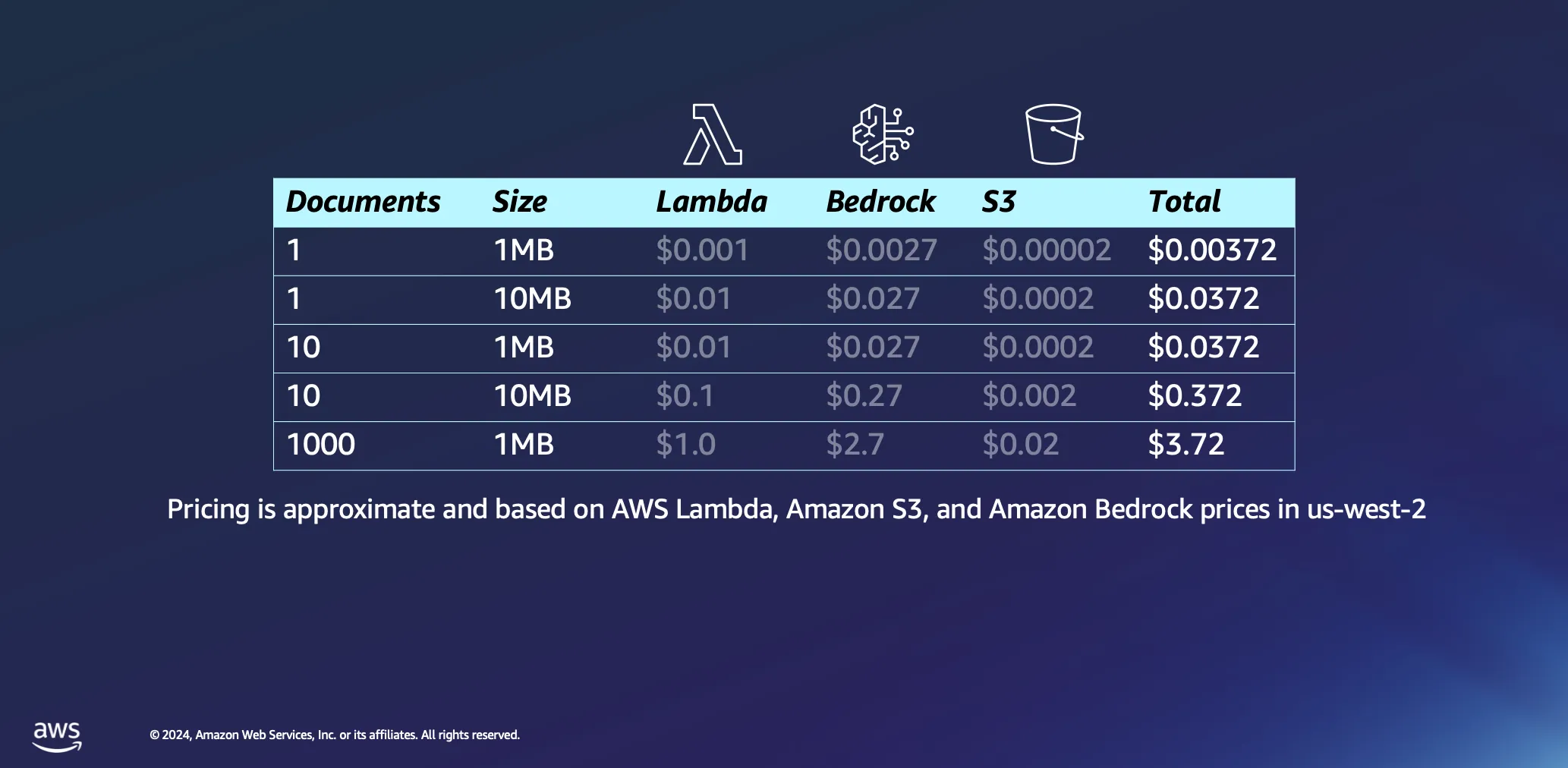
Let’s dive a bit deeper into the economics of using serverless architectures for document processing. We base our calculations on a couple of assumptions: processing time is roughly estimated at 1 minute per megabyte of data, and a document of this size typically contains just under 30,000 tokens. While these figures provide a baseline, the reality is often more favorable, with many documents being processed significantly quicker.
Processing a single 1MB document incurs a minimal expense, less than half a cent in most cases. When scaling up to a thousand documents, each 1MB in size, the total cost remains remarkably low, under $4. This example not only demonstrates the cost-effectiveness of serverless architectures for document processing but also highlights the efficiency of the token-based pricing model used in platforms like Amazon Bedrock. This is also a one-off process: once you have processed your documents, they’ll live in your vector database until you decide to delete them.
Querying Economics
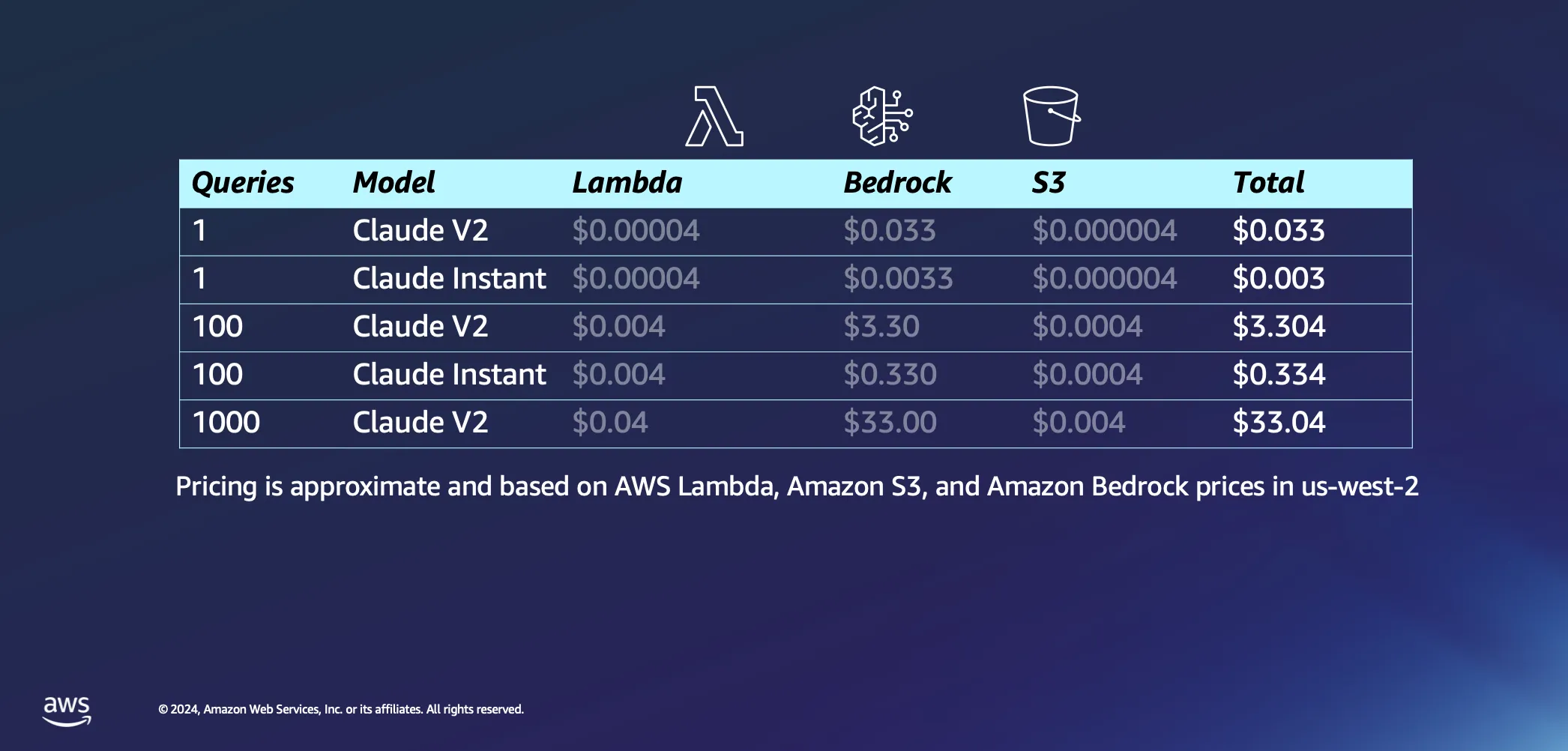
Switching gears to the interactive part of our setup, let's talk about what happens when you actually start asking your AI some questions. Here are a few of our assumptions: we're thinking it'll take about 20 seconds for AWS Lambda to embed our prompt get back to you with an answer, and we're assuming each question and its answer to be about 1000 tokens each. Compared to the inference cost, the charges associated with requests to S3 are negligible.
With assumptions out of the way, let's dive into the costs. Firing off a single query to the Claude V2 model by Anthropic is going to cost about 3 cents. If you opt for something a bit lighter, like Claude Instant, the cost drops dramatically to just a fraction of a cent per query. Ramp that up to 1000 queries with Claude V2, and you're looking at an overall expense of around $33. This covers the whole journey—sending your question over to the LLM, pulling similar documents from your database to enrich and bound your query to contextual documents, and getting a tailored answer.
The real cherry on top with this whole setup is how it's designed to work on a per-request basis, thanks to its serverless nature. This means you're only ever paying for what you use.
Expanding Horizons with Serverless RAG
Looking ahead, the potential applications of serverless RAG extend far beyond current use cases. By incorporating additional strategies such as re-ranking models for relevance, embedding adapters for enhanced semantic search, and exploring multimodal information integration, developers can further refine and expand their GenAI applications.
Amazon Bedrock's support for serverless RAG opens up new avenues for innovation in the field of generative AI. By reducing the barriers to entry and offering a scalable, cost-effective platform, AWS is empowering developers to explore the full potential of AI-driven applications. As we continue to explore and expand the capabilities of serverless RAG, the possibilities for creating more intelligent, responsive, and relevant AI solutions are boundless. Join us on this journey and discover how serverless RAG on Amazon Bedrock can transform your AI projects into reality.
Resources

Giuseppe Battista
Giuseppe Battista is a Senior Solutions Architect at Amazon Web Services. He leads soultions architecture for Early Stage Startups in UK and Ireland. He hosts the Twitch Show "Let's Build a Startup" on twitch.tv/aws and he's head of Unicorn's Den accelerator.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison is a Senior Solutions Architect at Amazon Web Services. He's helped hundreds of startups get off the ground quickly and up into the cloud. Kevin focuses on helping the earliest stage of founders with code samples and Twitch live streams.
How was this content?