このコンテンツはいかがでしたか?
- 学ぶ
- Serverless Retrieval Augmented Generation (RAG) on AWS
Serverless Retrieval Augmented Generation (RAG) on AWS
生成 AI が進化し続ける中で、外部の最新情報を大規模言語モデル (LLM) に統合することは、大きな進歩をもたらします。この記事では、真のサーバーレス検索拡張生成 (RAG) ソリューションを構築し、より正確でコンテキスト的に関連した応答を生成するアプリケーションの作成を容易にします。私たちの目標は、お客様がコストに目を光らせて、使用していないコンピューティング料金を支払わなくてもよいようにしつつ、GenAI を活用したアプリケーションを可能な限り迅速に作成できるようにサポートすることです。
サーバーレス RAG: 概要
サーバーレス RAG は、基盤モデルの高度な言語処理機能と、サーバーレスアーキテクチャの俊敏性およびコスト効率を兼ね備えています。この統合により、データベース、インターネット、カスタムナレッジベースなどの外部ソースからの情報の動的な取得が可能となり、正確でコンテキスト的にリッチであるだけでなく、最新の情報を含むコンテンツを生成できます。
Amazon Bedrock は、サーバーレス RAG アプリケーションのデプロイを簡素化し、広範なインフラストラクチャ管理を必要とすることなく、GenAI プロジェクトを作成、管理、スケールするためのツールをデベロッパーに提供します。それに加えて、デベロッパーは Lambda や S3 などの AWS サービスと、LanceDB などの革新的なオープンソースのベクトルデータベースを活用して、応答性とコスト効率の高い AI 駆動型のソリューションを構築できます。
ドキュメントの取り込み
サーバーレス RAG ソリューションを採用するための取り組みには、いくつかの重要なステップが含まれており、各ステップは基盤モデルと外部の知識のシームレスな統合を実現するように調整されています。
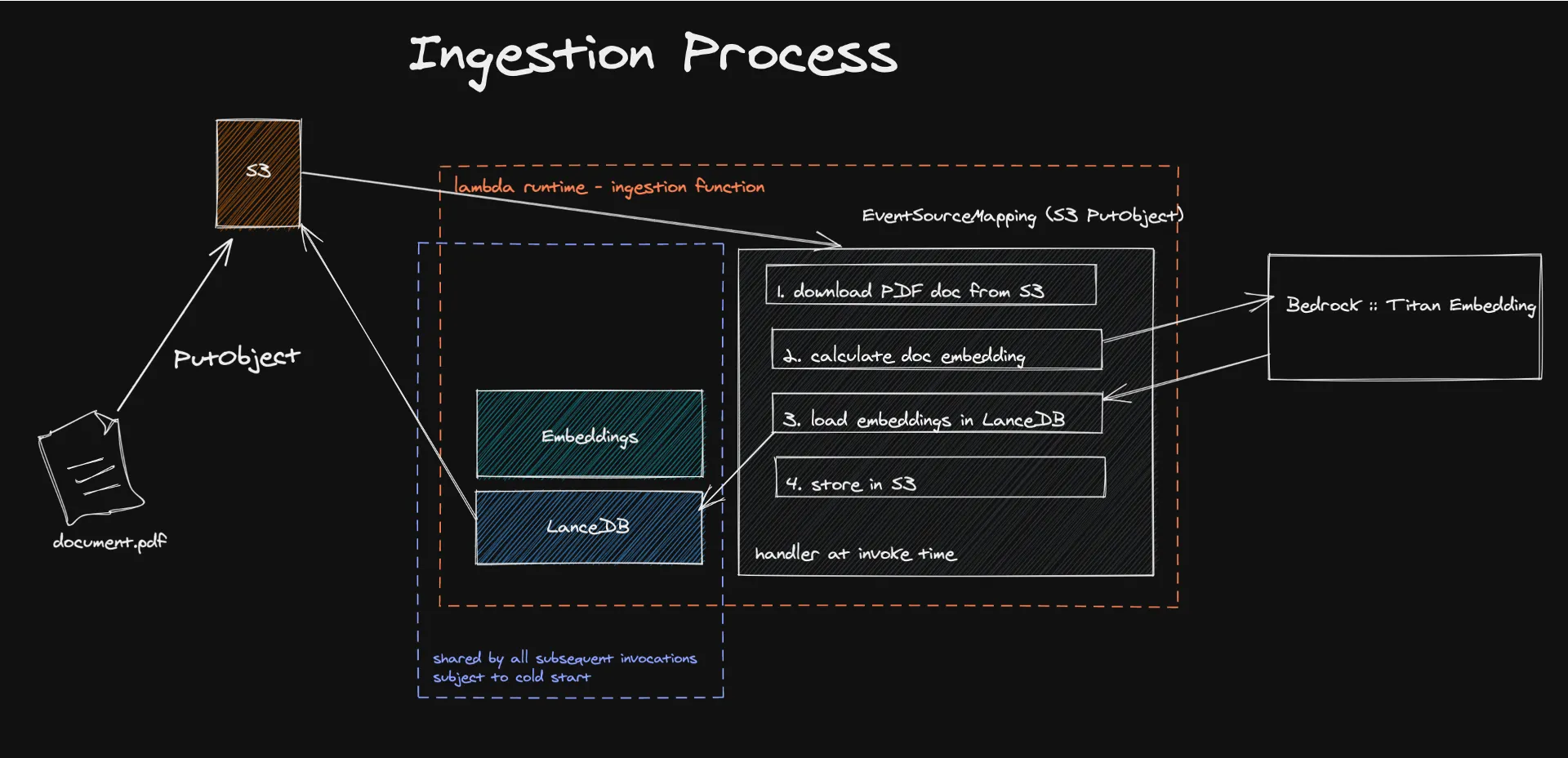
このプロセスは、サーバーレスアーキテクチャへのドキュメントの取り込みから始まり、イベント駆動型のメカニズムがテキストコンテンツの抽出と処理をトリガーして、埋め込みを生成します。Amazon Titan などのモデルを使用して作成されたこれらの埋め込みは、機械が容易に理解して処理できる数値ベクトルにコンテンツを変換します。
Amazon S3 を利用したサーバーレスベクトルデータベースである LanceDB にこれらのベクトルを保存すると、効率的な検索と管理が容易になり、LLM の応答を強化するために関連する情報のみが使用されるようになります。このアプローチでは、生成されたコンテンツの精度と関連性が高まるだけでなく、従量制料金モデルを活用することで運用コストも大幅に削減されます。
こちらのコードをご覧ください。
埋め込みとは何ですか?
自然言語処理 (NLP) の領域では、埋め込みは、機械が理解して処理できる数値形式にテキスト情報を変換できるようにする極めて重要な概念です。これは意味関係を幾何学的関係に変換する方法であり、コンピュータはこれを人間の言語よりもはるかに良く理解できます。基本的には、埋め込みを通じて、ドキュメントのコンテンツを高次元空間のベクトルに変換します。これにより、この空間内の幾何学的距離は意味論的な意味を持ちます。この空間では、異なる概念を表すベクトルは互いに遠く離れ、類似した概念はグループ化されます。
これは、大量のテキストコーパスでトレーニングされたニューラルネットワークを採用し、さまざまなコンテキストで単語のグループが一緒に出現する可能性を計算する Amazon Titan Embedding などのモデルを通じて実現されます。
幸いなことに、このシステムを最初から構築する必要はありません。Bedrock は、埋め込みモデルや他の基盤モデルへのアクセスを提供します。
ナレッジベースを埋め込みました。次はどうすればよいですか?
ナレッジベースをどこかに保管しておく必要があります。正確にはベクトルデータベースに保管します。そして、ベクトルデータベースは真のサーバーレスの魔法が起こる場所です。
LanceDB は、永続ストレージを使用したベクトル検索用に設計されたオープンソースのベクトルデータベースで、検索、フィルタリング、埋め込みの管理を簡素化します。私たちが特に有益だと感じたのは、LanceDB を S3 に直接接続できる機能でした。これにより、アイドル状態のコンピューティングが不要になります。Lambda 関数の実行中にのみデータベースを使用します。私たちの負荷テストでは、LanceDB、Bedrock、Lambda に大きな負荷がかかることなく、最大 500 MB のサイズのドキュメントを取り込めることがわかりました。
このシステムの既知の制限は Lambda のコールドスタートですが、大部分の時間を占めるプロセスは実際には Lambda の外部で行われる埋め込みの計算であることが測定で明らかとなりました。当社のユーザーベースがコールドスタートの影響を受けるのは事例の 10% に過ぎないことが測定によってわかりました。これを軽減するために、MVP の次のフェーズでバッチジョブを作成することを検討できるほか、Batch や ECS Fargate などの他のサーバーレス AWS サービスを利用し、スポット料金の恩恵も受けながら、さらにコストを削減することも考えられます。
クエリの実行
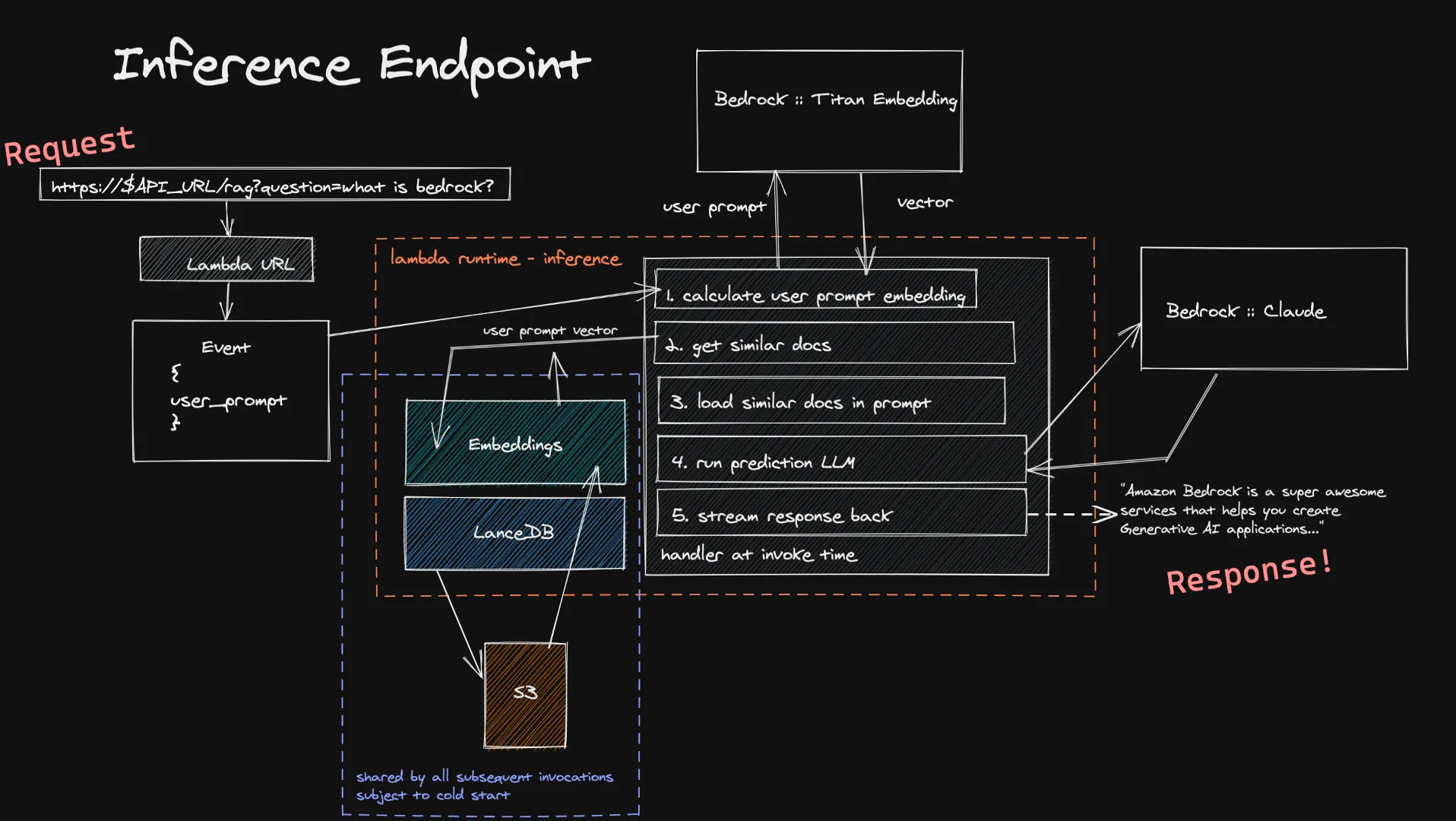
ユーザーは、Lambda URL を介して入力を推論関数に転送できます。これは、Bedrock を介して Titan Embedding モデルに入力され、このモデルはベクトルを計算します。その後、このベクトルを使用して、ベクトルデータベース内のいくつかの類似のドキュメントを取得し、それらを最終プロンプトに追加します。ユーザーが選択した LLM に最終プロンプトを送信します。LLM がストリーミングをサポートしている場合、応答はリアルタイムでユーザーにストリーミングされます。ここでも、長時間実行されるアイドル計算はありません。また、ユーザー入力のサイズは通常、取り込むドキュメントよりも小さいため、埋め込みの計算にかかる時間の短縮が期待できます。
この推論システムの既知の制限は、新しい Lambda 関数内でベクトルデータベースをコールドスタートすることです。LanceDB は S3 に保存されたデータベースを参照するため、新しい Lambda 実行環境が作成される際に、ベクトル検索を実行できるようにデータベースでロードする必要があります。これはスケールアップ中、またはしばらく誰も質問をしなかった場合にのみ発生します。これは、完全なサーバーレスアーキテクチャによるコスト削減とのトレードオフはかなり小さいということを意味します。
こちらのコードをご覧ください。
サーバーレス RAG の経済性の理解
サーバーレス RAG を採用するには、コストへの影響を理解することが重要です。Amazon Bedrock の料金モデルは、トークンの使用量とサーバーレスリソースの消費量に基づいており、デベロッパーはコストを正確に見積もることができます。ドキュメントを埋め込みのために処理する場合でも、応答を得るためにモデルに対してクエリを実行する場合でも、従量制料金により、コストは使用量に直接関連付けられるため、お支払いいただくのは使用した分の料金のみです。

取り込みの経済性
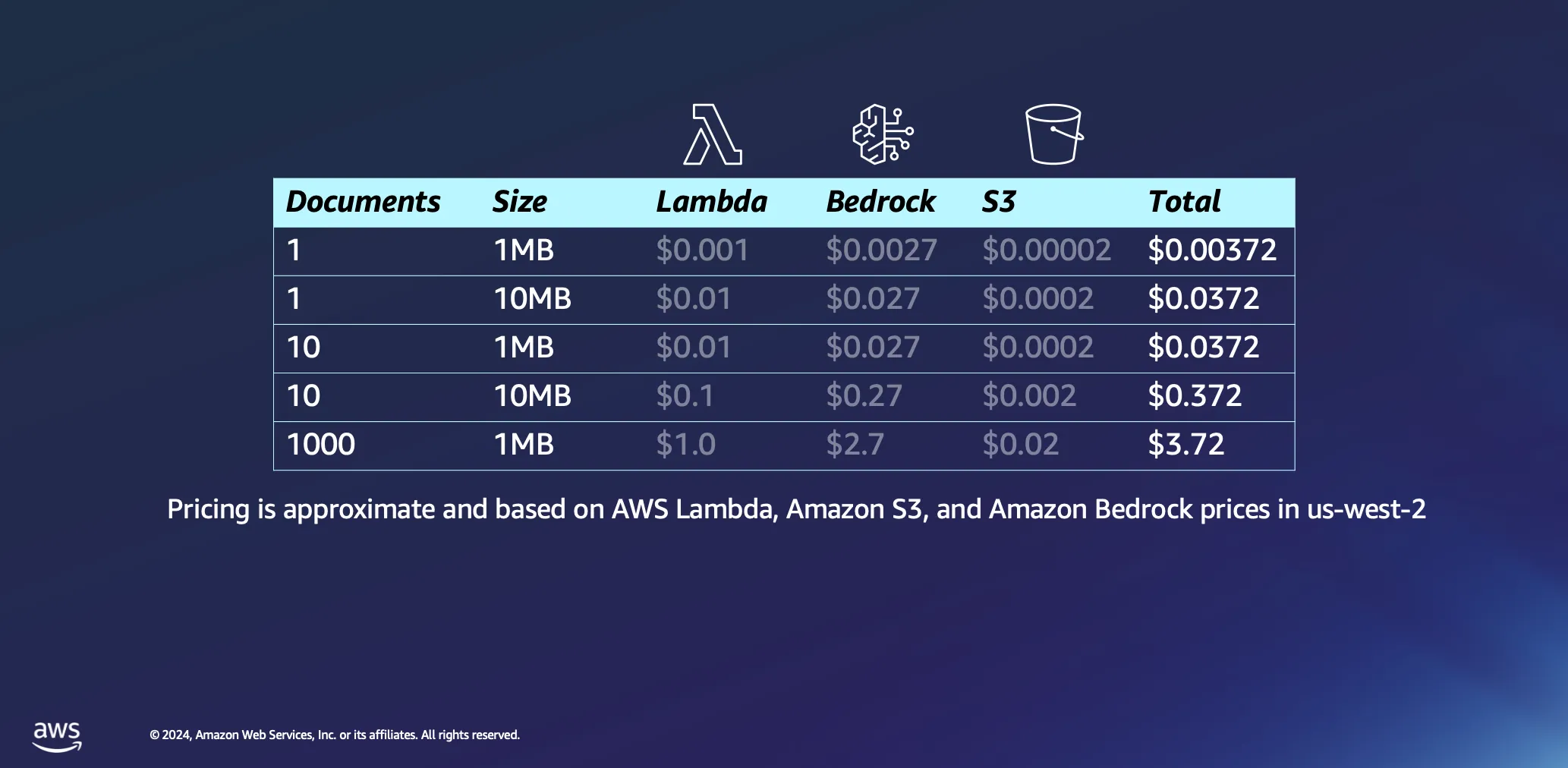
ドキュメント処理にサーバーレスアーキテクチャを使用する経済性について、もう少し詳しく見てみましょう。計算はいくつかの仮定に基づいています。処理時間はデータ 1 MB あたり 1 分と大まかに見積もられており、このサイズのドキュメントには通常 30,000 弱のトークンが含まれます。これらの数字はベースラインを提供しますが、現実では条件はより好ましい場合が多く、多くのドキュメントは大幅により迅速に処理されます。
1 個の 1 MB のドキュメントを処理するのにかかる費用はごくわずかで、ほとんどの場合は 0.5 USC 未満です。それぞれのサイズが 1 MB のドキュメントを 1,000 個までスケールアップしても、合計コストは 4 USD 未満と驚くほど低く抑えられます。この例は、ドキュメント処理におけるサーバーレスアーキテクチャの費用対効果を実証するだけでなく、Amazon Bedrock などのプラットフォームで使用されるトークンベースの料金モデルの効率性も明らかにしています。また、これは 1 回限りのプロセスです。ドキュメントを処理すると、削除するまでベクトルデータベースに保存されます。
クエリ実行の経済性
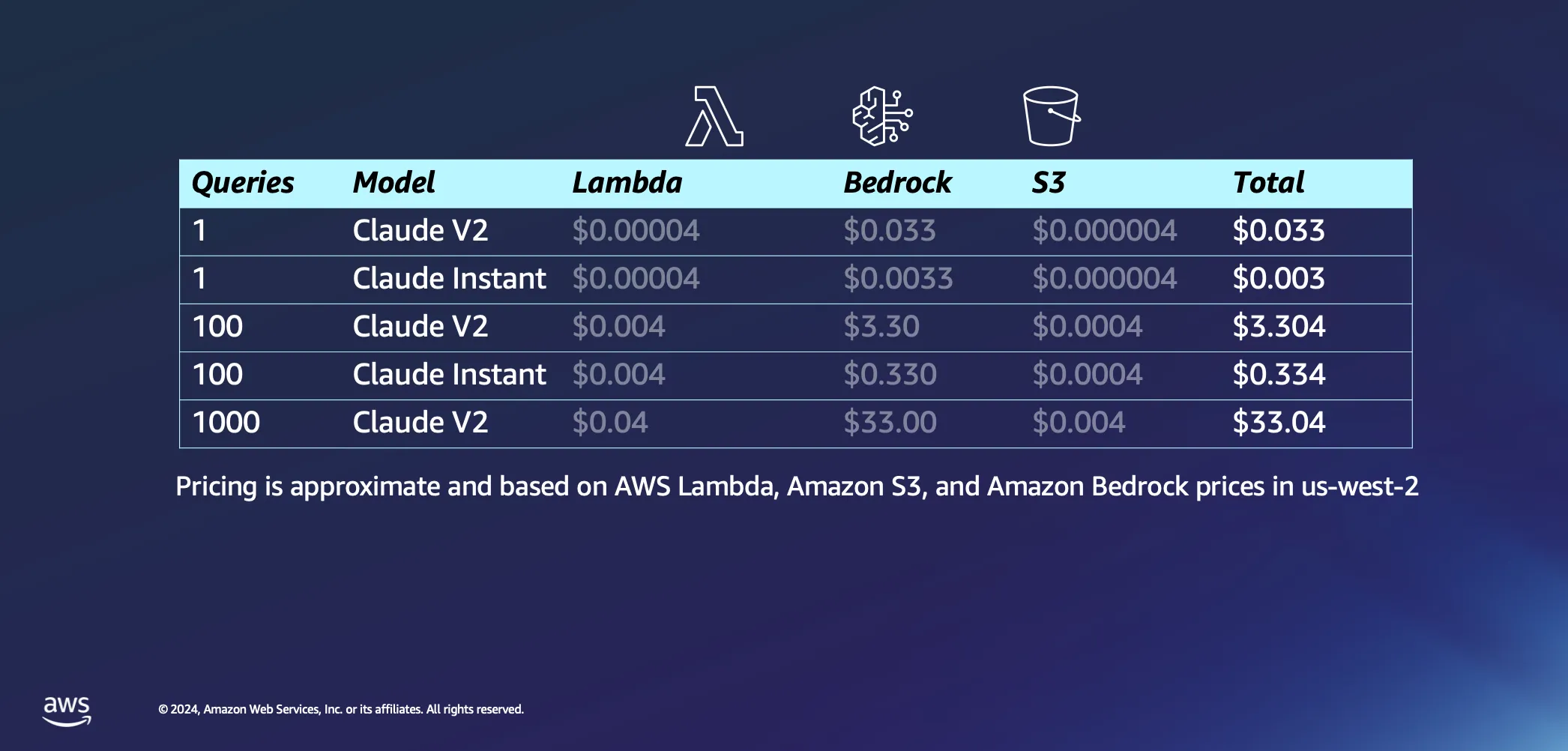
設定のインタラクティブな部分に話題を切り替えて、実際に AI にいくつかの質問をし始めると何が起こるかについて話しましょう。いくつかの仮定を次に示します。AWS Lambda がユーザーに回答を返すプロンプトを埋め込むのに約 20 秒かかると考えています。また、各質問とその回答はそれぞれ約 1,000 トークンであると想定しています。推論コストと比較すると、S3 に対するリクエストに関連する料金は無視できます。
仮定はこれくらいにして、次にコストについて詳しく見ていきましょう。Anthropic が Claude V2 モデルに対して 1 件のクエリを実行すると、約 3 USC のコストがかかります。Claude Instant のようなもう少し軽量のものを選択すると、コストはクエリあたりわずか 1 USC にまで劇的に減ります。Claude V2 を使用してクエリを 1,000 件まで増やすと、合計コストは約 33 USD になります。これは、質問を LLM に送信し、データベースから類似のドキュメントをプルしてクエリをエンリッチし、コンテキストドキュメントに結び付け、カスタマイズされた回答を得るまでのプロセス全体をカバーします。
この設定全体の極めて重要な点は、サーバーレスの性質のおかげで、リクエストごとに動作するように設計されているということです。つまり、お支払いいただくのは使用した分の料金のみとなります。
サーバーレス RAG による地平の拡張
将来に目を向けると、サーバーレス RAG の潜在的な用途は現在のユースケースをはるかに超えて広がるでしょう。高い関連性を実現するためのモデルの再ランク付け、強化されたセマンティック検索のためのアダプターの埋め込み、マルチモーダル情報統合の検討などの追加戦略を組み込むことで、デベロッパーは GenAI アプリケーションをさらに洗練し、拡張できます。
Amazon Bedrock のサーバーレス RAG のサポートは、生成 AI の分野におけるイノベーションへの新たな道を開きます。AWS は、参入障壁を軽減し、スケーラブルでコスト効率の高いプラットフォームを提供することにより、デベロッパーが AI 駆動型アプリケーションの可能性を最大限に探索できるようにしています。サーバーレス RAG の機能の探索と拡張を続ける中で、よりインテリジェントで応答性が高く、関連性の高い AI ソリューションを生み出すことができる可能性は無限にあります。このジャーニーに参加して、Amazon Bedrock でのサーバーレス RAG がどのように AI プロジェクトを現実に変換できるのかをご覧ください。
リソース

Giuseppe Battista
Giuseppe Battista は、Amazon Web Services の Senior Solutions Architect です。英国とアイルランドの初期段階のスタートアップのソリューションアーキテクチャを指揮しています。Giuseppe は twitch.tv/aws で Twitch Show の「Let's Build a Startup」を主催しており、Unicorn's Den アクセラレーターの責任者でもあります。

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison は、Amazon Web Services の Senior Solutions Architect です。Kevin は、何百ものスタートアップが迅速に軌道に乗ってクラウドに移行できるようサポートしてきました。Kevin は、コードサンプルと Twitch ライブストリームを利用して、創業者の最初期の段階をサポートすることに重点的に取り組んでいます。
このコンテンツはいかがでしたか?