Bagaimana konten ini?
Retrieval Augmented Generation (RAG) Nirserver di AWS
Dalam lanskap AI generatif yang berkembang, mengintegrasikan informasi eksternal dan terkini ke dalam model bahasa besar (LLM) menghadirkan kemajuan yang signifikan. Dalam posting ini, kita akan membangun solusi Retrieval Augmented Generation (RAG) nirserver, memfasilitasi pembuatan aplikasi yang menghasilkan respons yang lebih akurat dan relevan secara kontekstual. Tujuan kami adalah membantu Anda membuat aplikasi bertenaga GenAI secepat mungkin, mengawasi biaya Anda, dan memastikan Anda tidak membayar untuk komputasi yang tidak Anda gunakan.
RAG nirserver: ikhtisar
RAG nirserver menggabungkan kemampuan pemrosesan bahasa canggih dari model dasar dengan ketangkasan dan efektivitas biaya arsitektur nirserver. Integrasi ini memungkinkan pengambilan informasi secara dinamis dari sumber eksternal — baik itu basis data, internet, atau basis pengetahuan khusus — memungkinkan pembuatan konten yang tidak hanya akurat dan kaya secara kontekstual tetapi juga terkini dengan informasi terbaru.
Amazon Bedrock menyederhanakan deployment aplikasi RAG nirserver, menawarkan pengembang alat untuk membuat, mengelola, dan menskalakan proyek GenAI mereka tanpa perlu manajemen infrastruktur yang ekstensif. Selain itu, pengembang dapat memanfaatkan kekuatan layanan AWS seperti Lambda dan S3, bersama basis data vektor open-source inovatif seperti LanceDB, untuk membangun solusi berbasis AI yang responsif dan hemat biaya.
Menyerap dokumen
Perjalanan ke solusi RAG nirserver Anda melibatkan beberapa langkah utama, masing-masing disesuaikan untuk memastikan integrasi model dasar yang mulus dengan pengetahuan eksternal.
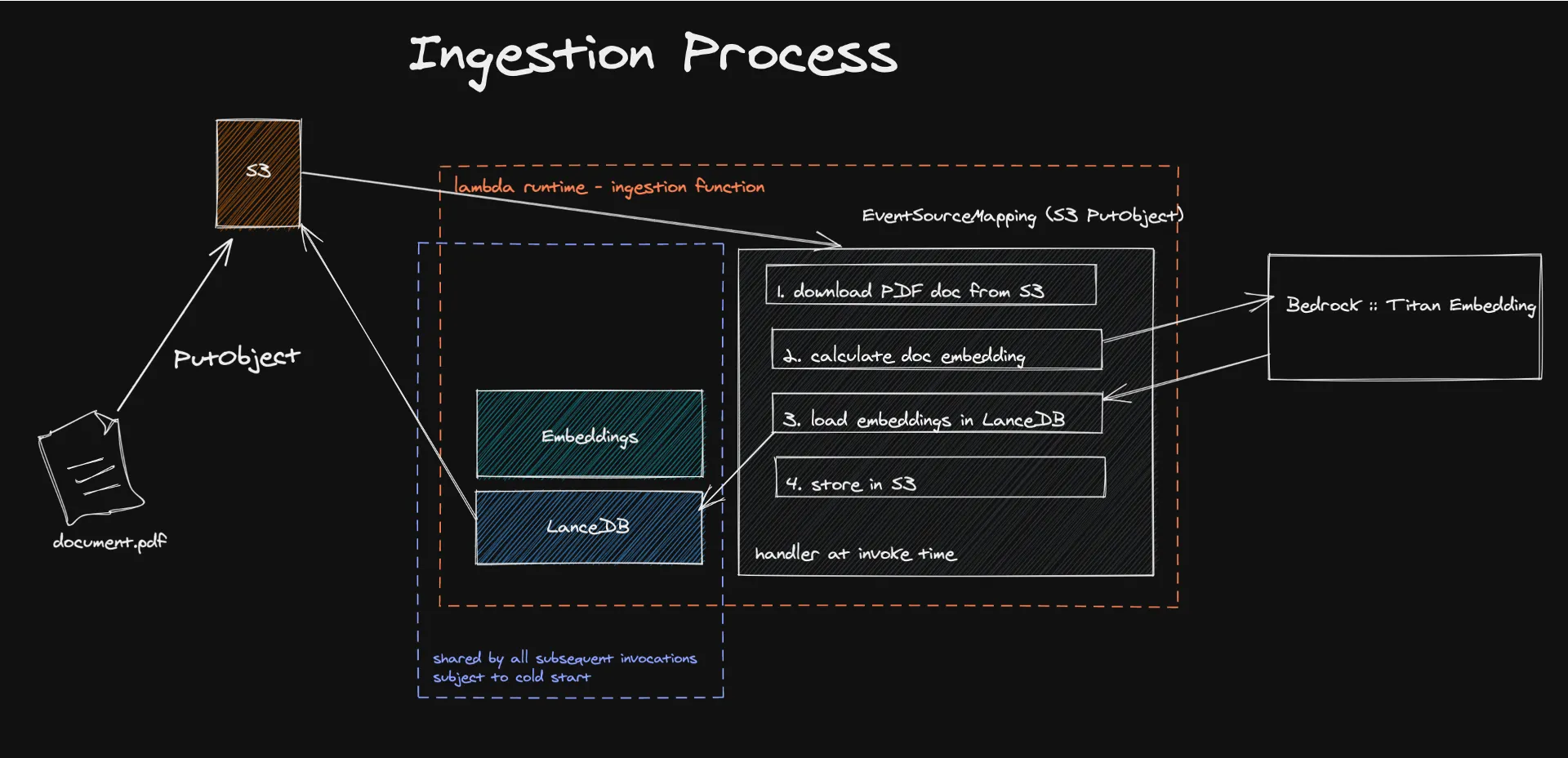
Prosesnya dimulai dengan penyerapan dokumen ke dalam arsitektur nirserver, di mana mekanisme yang digerakkan oleh peristiwa memicu ekstraksi dan pemrosesan konten tekstual untuk menghasilkan penyematan. Penyematan ini, dibuat menggunakan model seperti Amazon Titan, mengubah konten menjadi vektor numerik yang dapat dengan mudah dipahami dan diproses oleh mesin.
Menyimpan vektor-vektor ini di LanceDB, basis data vektor nirserver yang didukung oleh Amazon S3, memfasilitasi pengambilan dan manajemen yang efisien, memastikan bahwa hanya informasi yang relevan yang digunakan untuk menambah respons LLM. Pendekatan ini tidak hanya meningkatkan akurasi dan relevansi konten yang dihasilkan tetapi juga secara signifikan mengurangi biaya operasional dengan memanfaatkan model bayar untuk apa yang Anda gunakan.
Lihatlah kodenya di sini.
Apa itu penyematan?
Dalam bidang Pemrosesan Bahasa Alami (NLP), penyematan adalah konsep penting yang memungkinkan terjemahan informasi tekstual ke dalam bentuk numerik yang dapat dipahami dan diproses oleh mesin. Ini adalah cara untuk menerjemahkan hubungan semantik ke dalam hubungan geometris, sesuatu yang komputer dapat memahami jauh lebih baik daripada bahasa manusia. Pada dasarnya, melalui penyematan, kita akan mengubah konten dokumen menjadi vektor dalam ruang dimensi tinggi. Dengan cara ini, jarak geometris dalam ruang ini mengasumsikan makna semantik. Dalam ruang ini, vektor yang mewakili konsep yang berbeda akan jauh dari satu sama lain, dan konsep serupa akan dikelompokkan bersama.
Ini dicapai melalui model seperti Amazon Titan Embedding yang menggunakan jaringan neural yang dilatih pada korpus teks besar untuk menghitung kemungkinan kelompok kata muncul bersama dalam berbagai konteks.
Untungnya Anda tidak perlu membangun sistem ini dari awal. Bedrock ada untuk menyediakan akses ke model embedding, serta model dasar lainnya.
Saya telah menanamkan basis pengetahuan saya, sekarang apa?
Anda harus menyimpannya di suatu tempat! Sebuah basis data vektor, tepatnya. Dan di sinilah keajaiban nirserver benar-benar terjadi.
LanceDB adalah basis data vektor sumber terbuka yang dirancang untuk pencarian vektor dengan penyimpanan persisten, menyederhanakan pengambilan, pemfilteran, dan pengelolaan penyematan. Fitur yang menonjol bagi kami adalah kemampuan untuk menghubungkan LanceDB langsung ke S3. Dengan cara ini kita tidak perlu komputasi idle. Kita akan menggunakan basis data hanya saat fungsi lambda sedang berjalan. Tes beban kami menunjukkan bahwa kami dapat menelan dokumen hingga ukuran 500 MB tanpa LanceDB, Bedrock, atau Lambda berkeringat.
Keterbatasan yang diketahui dari sistem ini adalah start dingin Lambda, tetapi kami telah mengukur bahwa proses yang memakan sebagian besar waktu sebenarnya adalah perhitungan penyematan, yang terjadi di luar Lambda. Kami telah mengukur bahwa basis pengguna kami dipengaruhi oleh start dingin hanya pada 10% kasus. Untuk mengurangi ini, Anda dapat berpikir untuk membuat pekerjaan batch di fase berikutnya dari MVP dan berpotensi memanfaatkan layanan AWS nirserver lainnya seperti Batch atau ECS Fargate, memanfaatkan harga Spot juga untuk menghemat lebih jauh.
Mengkueri
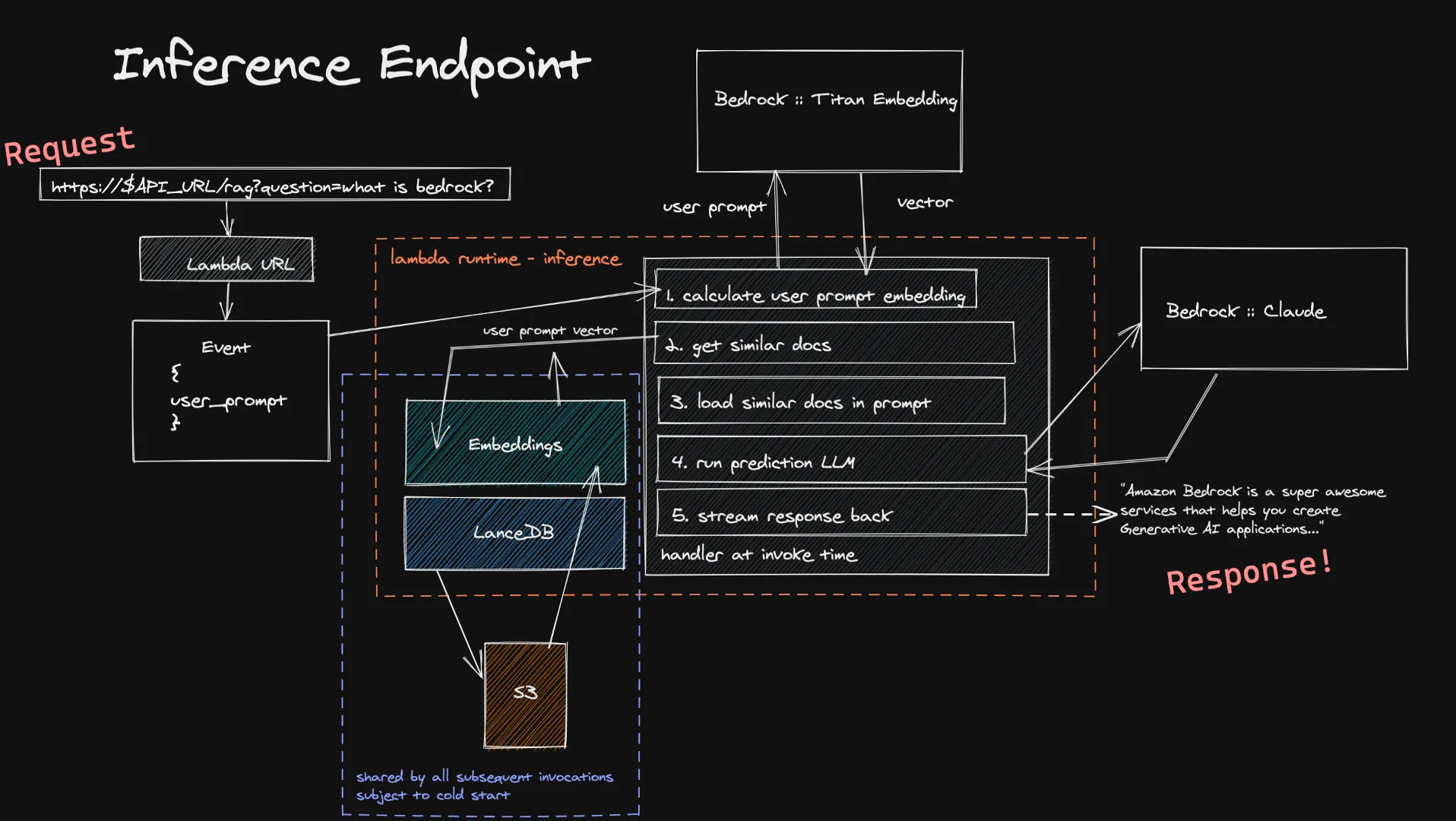
Pengguna dapat meneruskan masukan mereka ke fungsi Inferensi kami melalui URL Lambda. Ini dimasukkan ke dalam model Titan Embedding melalui Bedrock, yang menghitung vektor. Kami kemudian menggunakan vektor ini untuk mendapatkan beberapa dokumen serupa di basis data vektor kami, dan kami menambahkannya ke prompt terakhir. Kami mengirim prompt terakhir ke LLM yang dipilih pengguna dan, jika mendukung streaming, respons dialirkan kembali secara real time kepada pengguna. Sekali lagi kami tidak memiliki komputasi idle yang berjalan lama di sini, dan karena input pengguna biasanya lebih kecil dari dokumen yang kami konsumsi, Anda dapat mengharapkan waktu yang lebih pendek untuk perhitungan penyematannya.
Keterbatasan yang diketahui dari sistem inferensi ini adalah memulai dengan dingin basis data vektor kami dalam fungsi Lambda baru. Karena LanceDB mereferensikan basis data yang disimpan di S3, ketika lingkungan pelaksanaan Lambda baru dibuat - kita harus memuat dalam basis data untuk dapat melakukan pencarian vektor kita. Ini hanya terjadi ketika Anda meningkatkan skala atau tidak ada yang mengajukan pertanyaan untuk sementara waktu, yang berarti ini adalah pertukaran yang agak kecil untuk penghematan biaya arsitektur nirserver sepenuhnya.
Lihatlah kodenya di sini.
Menavigasi Ekonomi RAG Nirserver
Memahami implikasi biaya sangat penting untuk mengadopsi RAG nirserver. Model penetapan harga Amazon Bedrock, berdasarkan penggunaan token dan konsumsi sumber daya nirserver, memungkinkan pengembang memperkirakan biaya secara akurat. Baik memproses dokumen untuk menyematkan atau menanyakan model untuk tanggapan, harga bayar sesuai pemakaian memastikan bahwa biaya terkait langsung dengan penggunaan, sehingga Anda hanya membayar untuk apa yang Anda gunakan.

Ekonomi Penyerapan
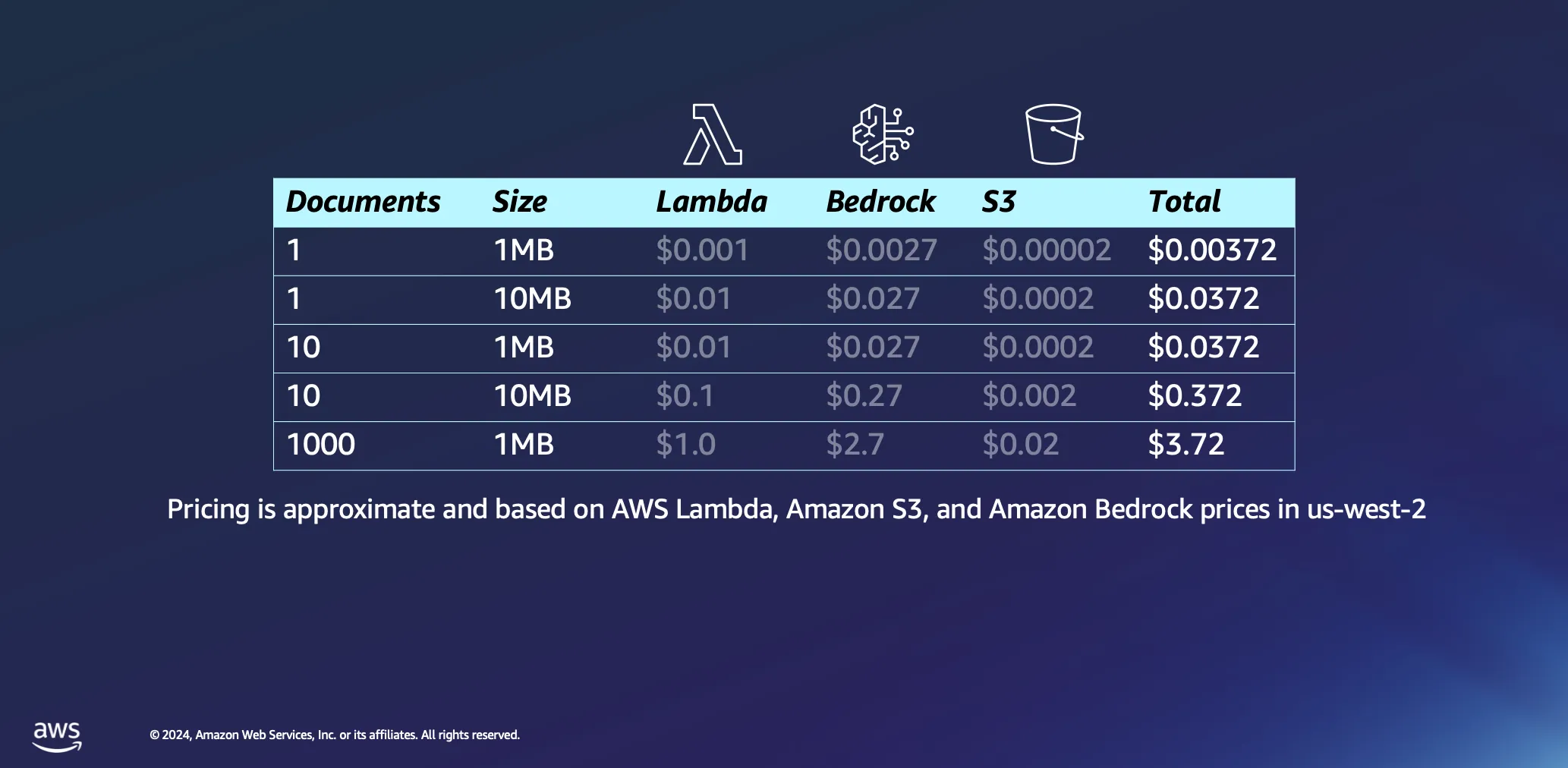
Mari selami sedikit lebih dalam ekonomi menggunakan arsitektur nirserver untuk pemrosesan dokumen. Kami mendasarkan perhitungan kami pada beberapa asumsi: waktu pemrosesan kira-kira diperkirakan 1 menit per megabyte data, dan dokumen dengan ukuran ini biasanya berisi hanya di bawah 30.000 token. Sementara angka-angka ini memberikan dasar, kenyataannya seringkali lebih menguntungkan, dengan banyak dokumen diproses secara signifikan lebih cepat.
Memproses satu dokumen 1 MB menimbulkan biaya minimal, kurang dari setengah sen dalam banyak kasus. Saat menskalakan hingga seribu dokumen, masing-masing berukuran 1 MB, total biaya tetap sangat rendah, di bawah 4 USD. Contoh ini tidak hanya menunjukkan efektivitas biaya arsitektur nirserver untuk pemrosesan dokumen tetapi juga menyoroti efisiensi model penetapan harga berbasis token yang digunakan dalam platform seperti Amazon Bedrock. Ini juga merupakan proses satu kali: setelah Anda memproses dokumen Anda, mereka akan tinggal di basis data vektor Anda sampai Anda memutuskan untuk menghapusnya.
Ekonomi Kueri
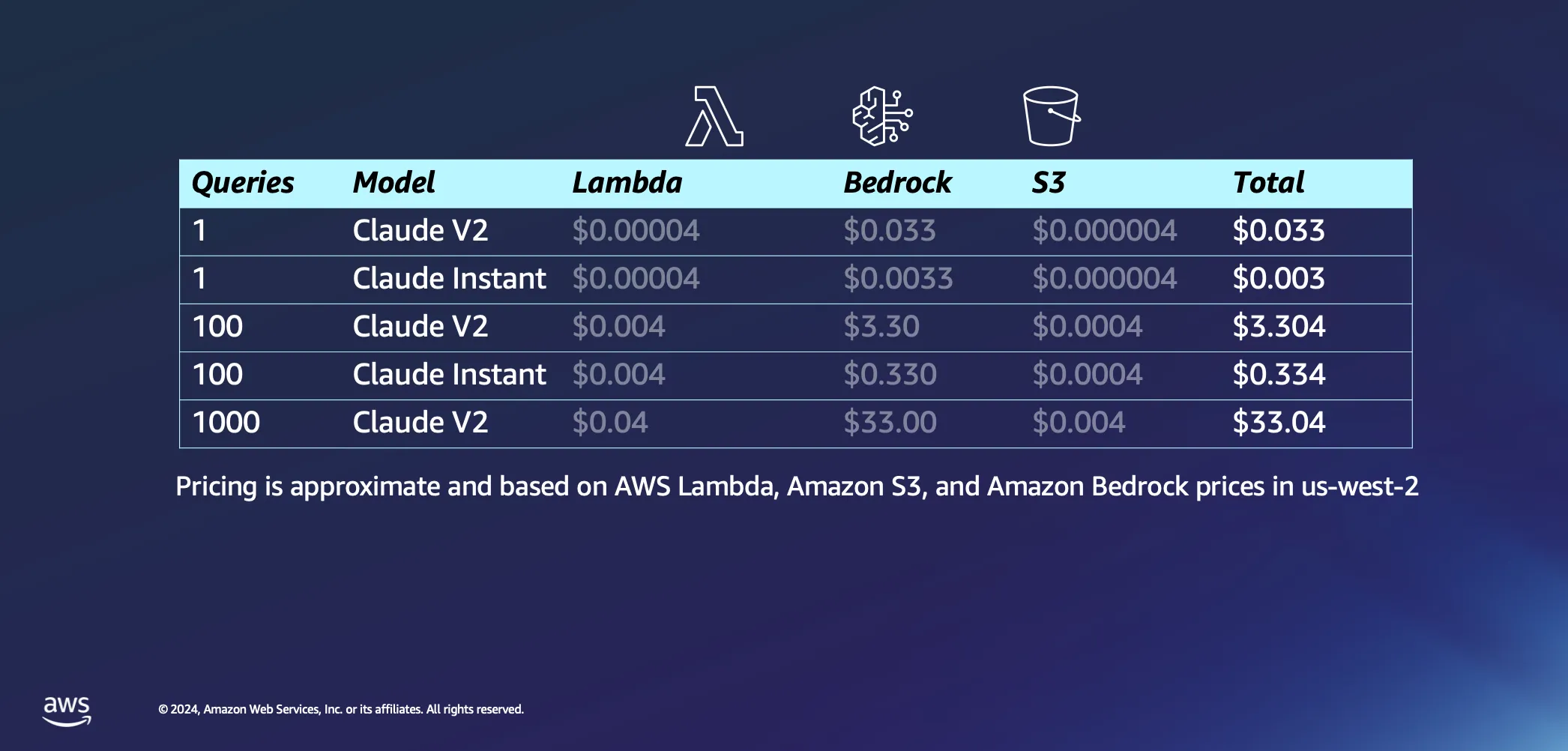
Beralih ke bagian interaktif dari pengaturan kami, mari kita bicara tentang apa yang terjadi ketika Anda benar-benar mulai mengajukan beberapa pertanyaan kepada AI Anda. Berikut adalah beberapa asumsi kami: kami pikir akan memakan waktu sekitar 20 detik bagi AWS Lambda untuk menyematkan prompt kami kembali kepada Anda dengan jawaban, dan kami mengasumsikan setiap pertanyaan dan jawabannya masing-masing sekitar 1000 token. Dibandingkan dengan biaya inferensi, biaya yang terkait dengan permintaan ke S3 dapat diabaikan.
Dengan asumsi terselesaikan, mari kita selami biayanya. Memulai satu kueri ke model Claude V2 oleh Anthropic akan menelan biaya sekitar 3 sen. Jika Anda memilih sesuatu yang sedikit lebih ringan, seperti Claude Instant, biayanya turun secara dramatis menjadi hanya sebagian kecil persen per kueri. Tingkatkan hingga 1000 kueri dengan Claude V2, dan Anda melihat biaya keseluruhan sekitar 33 USD. Ini mencakup seluruh perjalanan—mengirim pertanyaan Anda ke LLM, menarik dokumen serupa dari basis data Anda untuk memperkaya dan mengikat kueri Anda ke dokumen kontekstual, dan mendapatkan jawaban yang disesuaikan.
Yang paling menarik dari seluruh pengaturan ini adalah bagaimana ia dirancang untuk bekerja berdasarkan permintaan, berkat sifat nirservernya. Ini berarti Anda hanya membayar untuk apa yang Anda gunakan.
Memperluas Cakrawala dengan RAG Nirserver
Ke depannya, aplikasi potensial RAG nirserver jauh melampaui kasus penggunaan saat ini. Dengan menggabungkan strategi tambahan seperti peringkat ulang model untuk relevansi, menyematkan adaptor untuk pencarian semantik yang ditingkatkan, dan mengeksplorasi integrasi informasi multimodal, pengembang dapat lebih menyempurnakan dan memperluas aplikasi GenAI mereka.
Dukungan Amazon Bedrock untuk RAG nirserver membuka jalan baru untuk inovasi di bidang AI generatif. Dengan mengurangi hambatan masuk dan menawarkan platform yang dapat diskalakan dan hemat biaya, AWS memberdayakan pengembang untuk mengeksplorasi potensi penuh aplikasi berbasis AI. Saat kami terus mengeksplorasi dan memperluas kemampuan RAG nirserver, kemungkinan untuk menciptakan solusi AI yang lebih cerdas, responsif, dan relevan tidak terbatas. Bergabunglah dengan kami dalam perjalanan ini dan temukan bagaimana RAG nirserver di Amazon Bedrock dapat mengubah proyek AI Anda menjadi kenyataan.
Sumber Daya

Giuseppe Battista
Giuseppe Battista adalah Senior Solutions Architect di Amazon Web Services. Dia memimpin <i>solutions architecture</i> untuk Startup Tahap Awal di Inggris dan Irlandia. Dia menjadi pembawa acara Twitch Show “Let's Build a Startup” di twitch.tv/aws dan dia kepala Unicorn's Den accelerator.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison adalah Senior Solutions Architect di Amazon Web Services. Dia telah membantu ratusan startup untuk memulai dengan cepat dan naik ke <i>cloud</i>. Kevin berfokus untuk membantu tahap awal pendiri dengan sampel kode dan <i>streaming </i>langsung Twitch.
Bagaimana konten ini?