Como estava esse conteúdo?
Geração aumentada de recuperação sem servidor (RAG) na AWS
No cenário em evolução da IA generativa, a integração de informações externas e atualizadas em grandes modelos de linguagem (LLMs) representa um avanço significativo. Neste post, vamos desenvolver uma solução de Retrieval Augmented Generation (RAG) autenticamente sem servidor, facilitando a criação de aplicações que produzem respostas mais precisas e contextualmente relevantes. Nosso objetivo é ajudar você a criar sua aplicação de IA generativa o mais rápido possível, prestando atenção aos seus custos e garantindo que você não pague por recursos de computação que não está usando.
RAG sem servidor: uma visão geral
O RAG sem servidor combina os recursos avançados de processamento de linguagem dos modelos de base com a agilidade e a economia da arquitetura da tecnologia sem servidor. Essa integração permite a recuperação dinâmica de informações de fontes externas, sejam elas bancos de dados, a Internet ou bases de conhecimento personalizadas, permitindo a geração de conteúdo que não só é preciso e contextualmente rico, como também atualizado com as informações mais recentes.
O Amazon Bedrock simplifica a implantação de aplicações de RAG sem servidor, oferecendo aos desenvolvedores as ferramentas ideais para criar, gerenciar e escalar seus projetos de IA generativa sem a necessidade de um amplo gerenciamento da infraestrutura. Além disso, os desenvolvedores podem aproveitar o poder dos serviços da AWS, como o Lambda e o S3, junto com inovadores bancos de dados de vetores de código aberto, como o LanceDB, para criar soluções responsivas e econômicas orientadas por IA.
Ingestão de documentos
A jornada até a sua solução de RAG sem servidor envolve várias etapas importantes, cada uma adaptada para garantir a integração perfeita de modelos de base com o conhecimento externo.
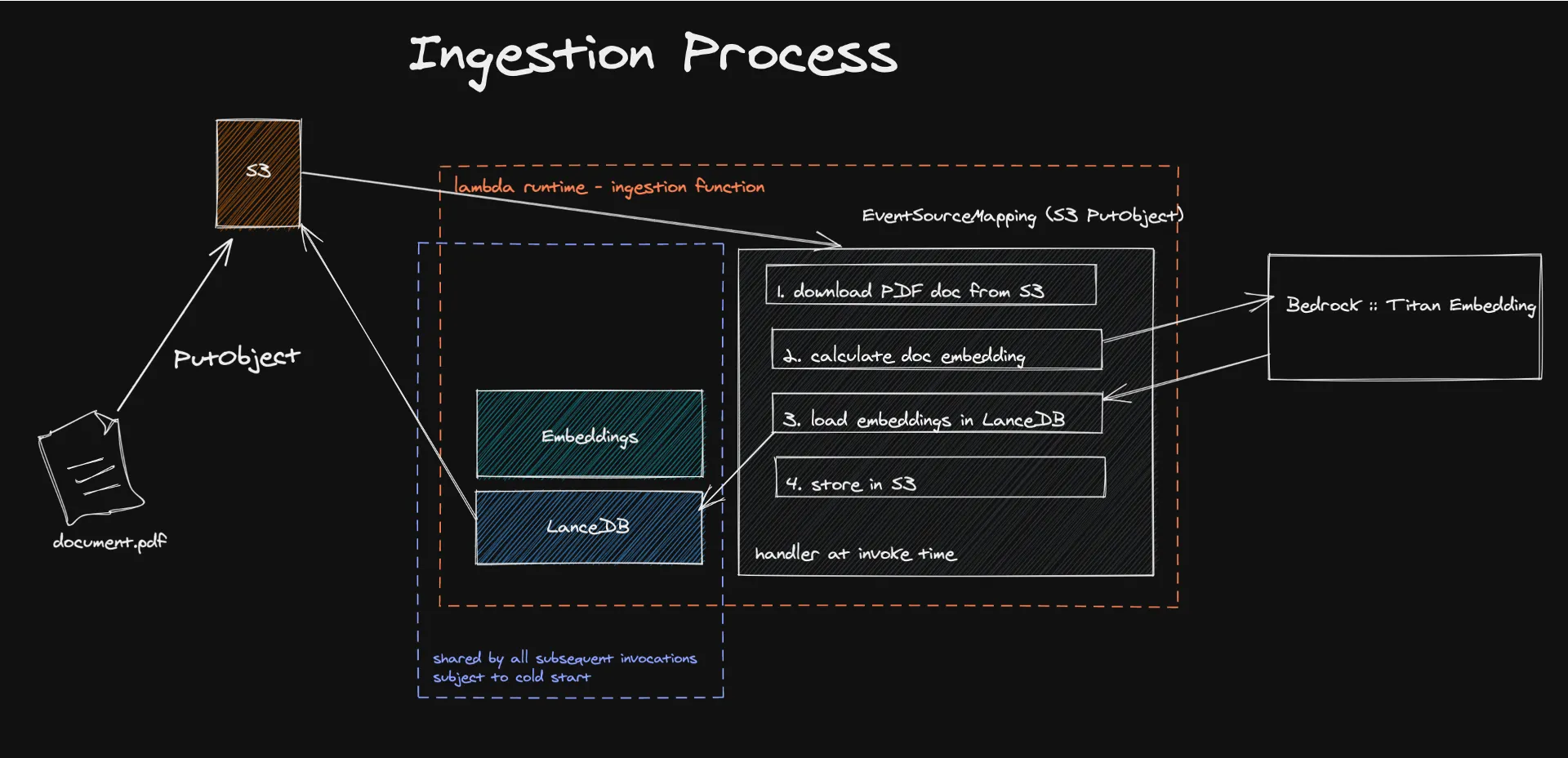
O processo começa com a ingestão de documentos em uma arquitetura sem servidor, na qual mecanismos orientados por eventos acionam a extração e o processamento de conteúdo textual para gerar incorporações. Essas incorporações, criadas usando modelos como o Amazon Titan, transformam o conteúdo em vetores numéricos que as máquinas são capazes de entender e processar facilmente.
Armazenar esses vetores no LanceDB, um banco de dados de vetores sem servidor e respaldado pelo Amazon S3, facilita a recuperação e o gerenciamento eficientes, garantindo que somente informações relevantes sejam usadas para elaborar as respostas do LLM. Essa abordagem não só aumenta a precisão e a relevância do conteúdo gerado, como também reduz significativamente os custos operacionais ao aproveitar um modelo de pagamento por uso.
Confira o código aqui.
O que são incorporações?
No campo do Processamento de linguagem natural (PLN), incorporações são um conceito fundamental que permite a conversão de informações textuais em formato numérico que as máquinas são capazes de entender e processar. É uma maneira de traduzir relações semânticas em relações geométricas, algo que os computadores podem entender muito melhor do que a linguagem humana. Essencialmente, por meio de incorporações, transformamos o conteúdo de um documento em vetores em um espaço de alta dimensão. Dessa forma, a distância geométrica nesse espaço assume um significado semântico. Nesse espaço, vetores representando conceitos diferentes estão distantes uns dos outros, enquanto conceitos semelhantes ficam agrupados.
Isso pode ser feito por meio de modelos como o Amazon Titan Embedding, que emprega redes neurais treinadas em corpora de texto enormes para calcular a probabilidade de grupos de palavras aparecerem juntos em vários contextos.
Felizmente, você não precisa criar esse sistema do zero. O Bedrock existe para fornecer acesso a modelos de incorporação, bem como a outros modelos de base.
Incorporei minha base de conhecimento, e agora?
Você precisa armazená-la em algum lugar, para ser mais preciso, em um banco de dados de vetores. E é aqui que a verdadeira mágica da tecnologia sem servidor acontece.
O LanceDB é um banco de dados de vetores de código aberto projetado para pesquisa vetorial com armazenamento persistente, simplificando a recuperação, a filtragem e o gerenciamento de incorporações. O recurso de maior destaque para nós foi a capacidade de conectar o LanceDB diretamente ao S3. Dessa maneira, não precisamos de computação ociosa. Usaremos o banco de dados somente enquanto a função do lambda estiver em execução. Nossos testes de carga mostraram que podemos ingerir documentos de até 500 MB sem sobrecarregar o LanceDB, o Bedrock ou o Lambda.
Uma limitação conhecida desse sistema são as inicializações a frio do Lambda. Porém, medimos que o processo que consome a maior parte do tempo é, na verdade, o cálculo de incorporações, que acontece fora do Lambda. Medimos que nossa base de usuários é afetada pela inicialização a frio apenas em 10% dos casos. Para mitigar isso, você pode pensar em criar trabalhos em lote em uma próxima fase de um MVP e, potencialmente, usar outros serviços sem servidor da AWS, como o Batch ou o ECS Fargate, aproveitando também os preços spot para economizar ainda mais.
Consultas
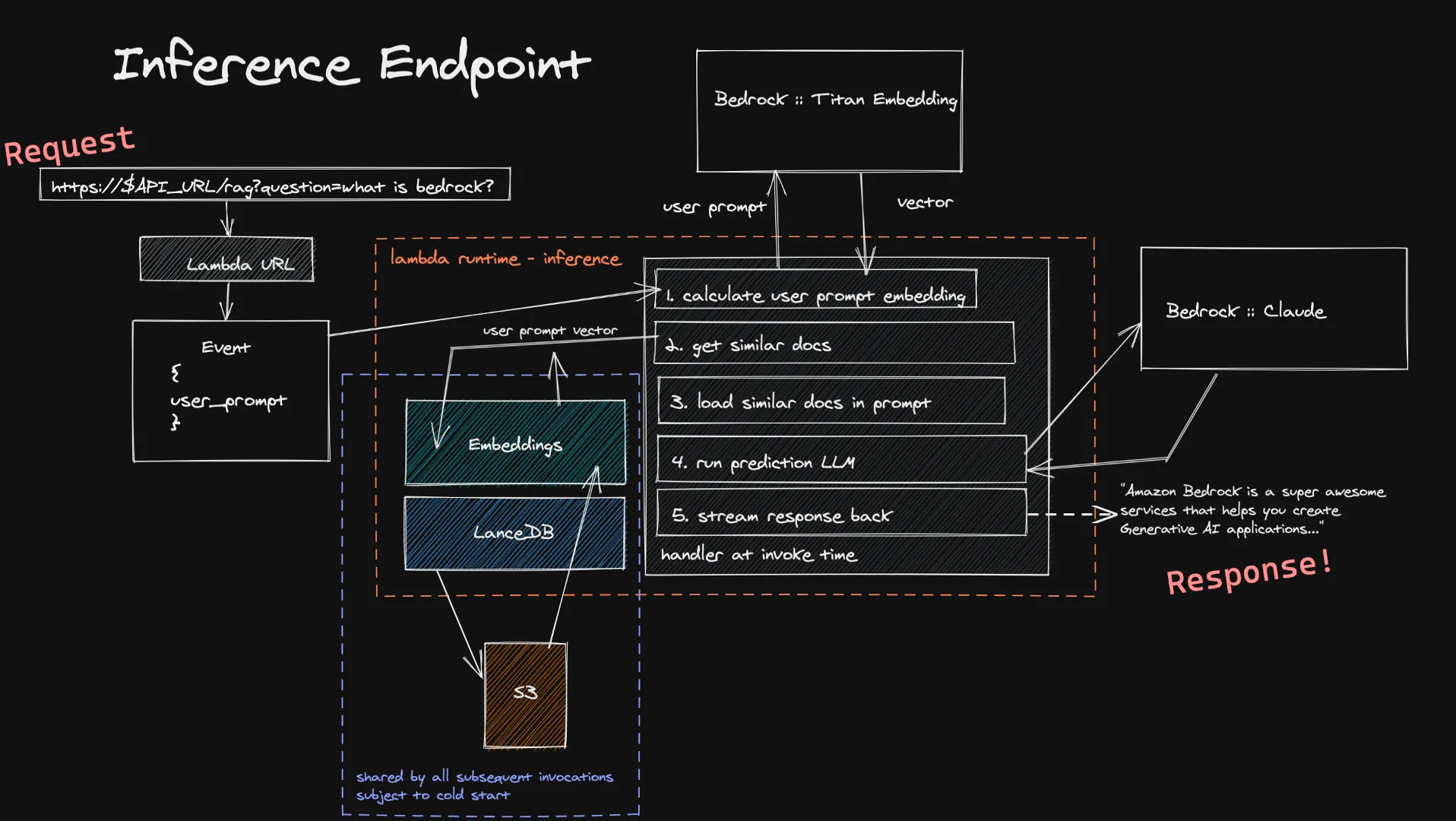
Os usuários podem encaminhar suas entradas à nossa função de inferência por meio de um URL do Lambda. Isso é inserido no modelo Titan Embedding por meio do Bedrock, que calcula um vetor. Em seguida, usamos esse vetor para obter vários documentos semelhantes em nossos bancos de dados de vetores e os adicionamos ao prompt final. Enviamos o prompt final ao LLM escolhido pelo usuário e, caso ele seja compatível com streaming, a resposta é transmitida de volta em tempo real ao usuário. Novamente, não temos computação ociosa de longa duração e, como a entrada do usuário é geralmente menor que os documentos que ingerimos, você pode esperar tempos mais curtos para o cálculo de sua incorporação.
Uma limitação conhecida desse sistema de inferência é a inicialização a frio do nosso banco de dados de vetores dentro de uma nova função do Lambda. Como o LanceDB faz referência a um banco de dados armazenado no S3, quando um novo ambiente de execução do Lambda é criado, precisamos carregar o banco de dados para poder fazer nossas pesquisas de vetores. Isso apenas acontece quando você está aumentando a escala verticalmente ou quando ninguém faz uma pergunta há algum tempo, ou seja, uma troca bastante pequena pela economia de custos de uma arquitetura totalmente sem servidor.
Confira o código aqui.
Sobre os aspectos econômicos do RAG sem servidor
Compreender as implicações de custos é essencial para a adoção do RAG sem servidor. O modelo de preços do Amazon Bedrock, baseado no uso de tokens e no consumo de recursos sem servidor, permite que os desenvolvedores façam estimativas de custos com precisão. Seja processando documentos para incorporação ou consultando o modelo para obter respostas, o preço conforme o uso garante que os custos estejam diretamente vinculados ao uso, permitindo que você pague somente pelo que usa.

Aspectos econômicos da ingestão
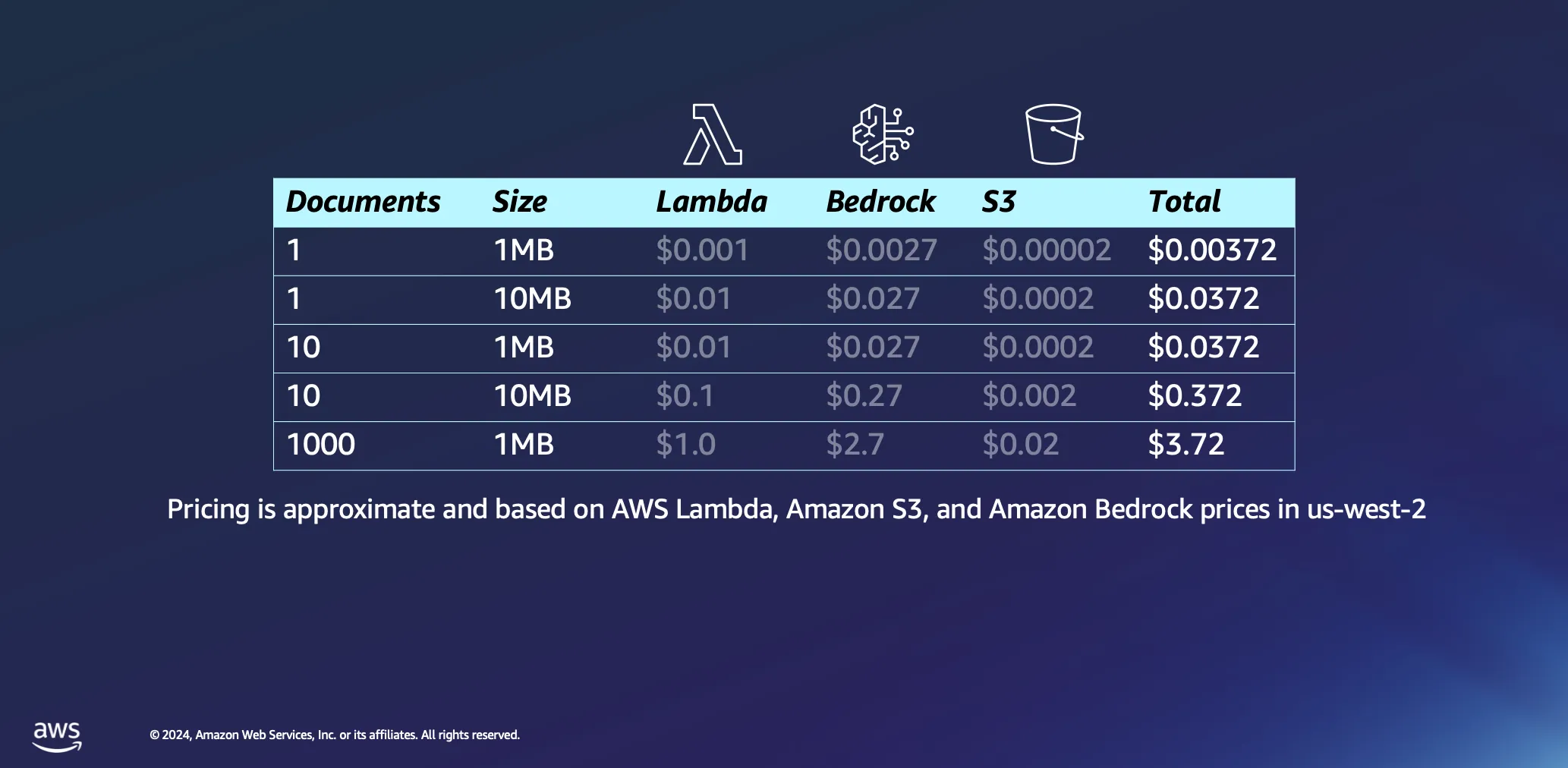
Vamos nos aprofundar um pouco mais nos aspectos econômicos do uso de arquiteturas sem servidor para processamento de documentos. Baseamos nossos cálculos em algumas suposições: o tempo de processamento é estimado em aproximadamente 1 minuto por megabyte de dados, e um documento desse tamanho normalmente contém pouco menos de 30.000 tokens. Embora esses números forneçam uma linha de base, a realidade geralmente é mais favorável, e muitos documentos são processados de maneira significativamente mais rápida.
O processamento de um único documento de 1 MB gera uma despesa mínima de menos de meio centavo de dólar na maioria dos casos. Ao escalar até mil documentos, cada um com 1 MB de tamanho, o custo total permanece extremamente baixo, abaixo de USD 4. Esse exemplo não só demonstra a relação custo-benefício das arquiteturas sem servidor para processamento de documentos, como também destaca a eficiência do modelo de preços baseado em tokens usado em plataformas como o Amazon Bedrock. Também é um processo único: depois de processar seus documentos, eles permanecerão no seu banco de dados de vetores até que você decida excluí-los.
Aspectos econômicos das consultas
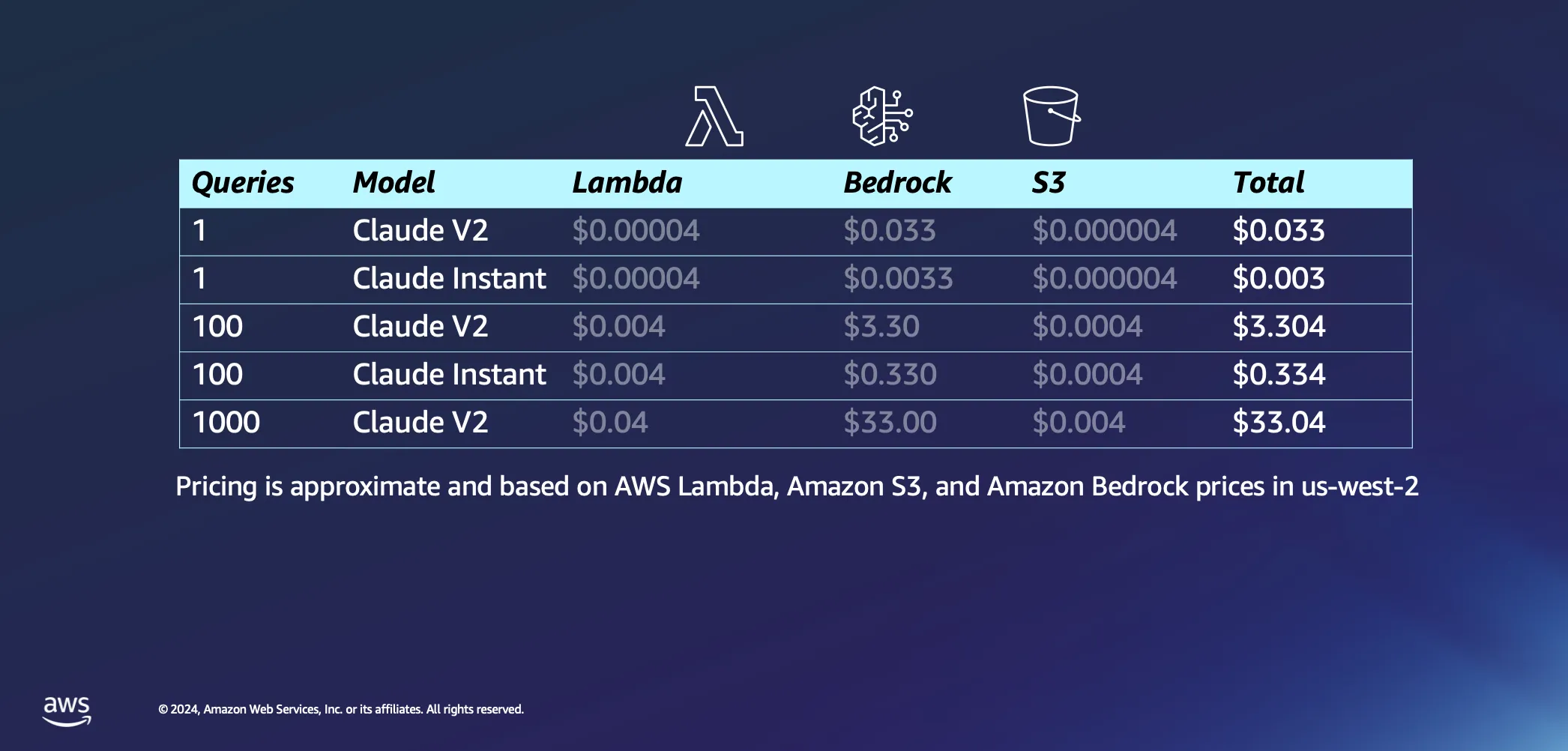
Passando para a parte interativa da nossa configuração, vamos falar sobre o que acontece quando você realmente começa a fazer algumas perguntas para a sua IA. Aqui estão algumas das nossas suposições: acreditamos que levará cerca de 20 segundos para o AWS Lambda incorporar nosso prompt e retornar uma resposta e presumimos que cada pergunta e sua respectiva resposta tenham cerca de 1000 tokens cada. Em comparação com o custo da inferência, as cobranças associadas às solicitações ao S3 são insignificantes.
Com as suposições fora do caminho, vamos nos aprofundar nos custos. Acionar uma única consulta para o modelo Claude V2 da Anthropic custa cerca de USD 0,03. Se você optar por algo um pouco mais leve, como o Claude Instant, o custo cairá drasticamente para apenas uma fração de centavo de dólar por consulta. Aumente esse número para 1.000 consultas com o Claude V2, e você terá uma despesa total de cerca de USD 33. Isso cobre toda a jornada: envio da pergunta para o LLM, extração de documentos semelhantes do seu banco de dados para enriquecer e vincular sua consulta a documentos contextuais e receber uma resposta personalizada.
A verdadeira pérola de toda essa configuração é como ela foi projetada para funcionar em cada solicitação, graças à sua natureza sem servidor. Isso significa que você só paga pelo que usa.
Expansão de horizontes com o RAG sem servidor
Contemplando o futuro, as aplicações potenciais do RAG sem servidor vão muito além dos casos de uso atuais. Ao incorporar estratégias adicionais, como reclassificação de modelos de relevância, incorporação de adaptadores para pesquisa semântica aprimorada e exploração da integração de informações multimodais, os desenvolvedores podem refinar e expandir ainda mais suas aplicações de IA generativa.
O suporte do Amazon Bedrock para o RAG sem servidor abre novos caminhos para a inovação no campo da IA generativa. Ao reduzir as barreiras de entrada e oferecer uma plataforma escalável e econômica, a AWS está capacitando os desenvolvedores a explorar todo o potencial das aplicações orientadas por IA. À medida que continuamos explorando e expandindo os recursos do RAG sem servidor, as possibilidades de criar soluções de IA mais inteligentes, responsivas e relevantes são ilimitadas. Junte-se a nós nessa jornada e descubra como o RAG sem servidor no Amazon Bedrock é capaz de transformar seus projetos de IA em realidade.
Recursos

Giuseppe Battista
Giuseppe Battista é arquiteto sênior de soluções na Amazon Web Services. Ele lidera a arquitetura de soluções para startups em estágio inicial no Reino Unido e na Irlanda, apresenta o programa do Twitch “Let's Build a Startup” (twitch.tv/aws) e é chefe do acelerador Unicorn's Den.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison é arquiteto sênior de soluções na Amazon Web Services. Ele ajudou centenas de startups a decolar rapidamente e entrar na nuvem. Kevin se concentra em ajudar fundadores em estágio inicial com exemplos de código e transmissões ao vivo pelo Twitch.
Como estava esse conteúdo?