Wie war dieser Inhalt?
Serverless Retrieval Augmented Generation (RAG) auf AWS
In der sich entwickelnden Landschaft der generativen KI stellt die Integration externer, aktueller Informationen in große Sprachmodelle (LLMs) einen bedeutenden Fortschritt dar.In diesem Beitrag werden wir eine wirklich serverlose Retrieval Augmented Generation (RAG)-Lösung entwickeln, die die Erstellung von Anwendungen erleichtert, die genauere und kontextbezogene Antworten liefern. Unser Ziel ist es, Ihnen dabei zu helfen, Ihre GenAI-gestützte Anwendung so schnell wie möglich zu erstellen und dabei Ihre Kosten im Auge zu behalten und sicherzustellen, dass Sie nicht für nicht genutzte Rechenleistung bezahlen.
Serverless RAG: ein Überblick
Serverless RAG kombiniert die fortschrittlichen Sprachverarbeitungsfunktionen der Basismodelle mit der Agilität und Kosteneffizienz der serverlosen Architektur. Diese Integration ermöglicht den dynamischen Abruf von Informationen aus externen Quellen - seien es Datenbanken, das Internet oder benutzerdefinierte Wissensdatenbanken – und damit die Generierung von Inhalten, die nicht nur präzise und kontextbezogen sind, sondern auch die neuesten Informationen enthalten.
Amazon Bedrock vereinfacht die Bereitstellung von Serverless-RAG-Anwendungen und bietet Entwicklern die Tools zum Erstellen, Verwalten und Skalieren ihrer Projekte mit generativer KI, ohne dass ein umfangreiches Infrastrukturmanagement erforderlich ist. Darüber hinaus können Entwickler die Leistung von AWS-Diensten wie Lambda und S3 sowie innovative Open-Source-Vektordatenbanken wie LanceDB nutzen, um reaktionsschnelle und kostengünstige KI-gesteuerte Lösungen zu erstellen.
Dokumente zuführen
Der Weg zu Ihrer Serverless-RAG-Lösung umfasst mehrere wichtige Schritte, die jeweils darauf zugeschnitten sind, die nahtlose Integration der grundlegenden Modelle mit externem Wissen zu gewährleisten.
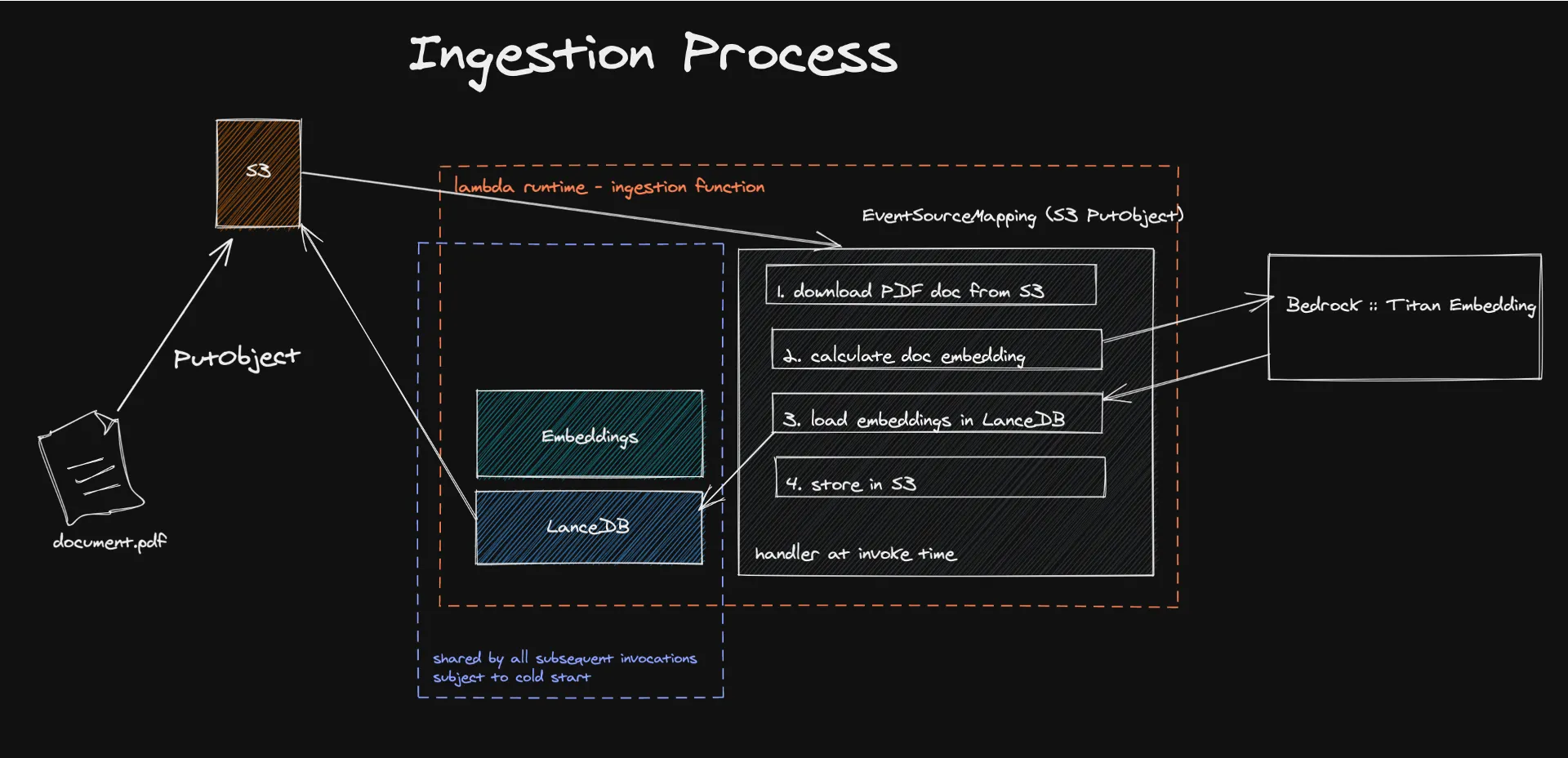
Der Prozess beginnt mit der Zuführung von Dokumenten in eine Serverless-Architektur, in der ereignisgesteuerte Mechanismen die Extraktion und Verarbeitung von Textinhalten auslösen, um Einbettungen zu generieren. Diese Einbettungen, die mit Modellen wie Amazon Titan erstellt wurden, wandeln den Inhalt in numerische Vektoren um, die Maschinen leicht verstehen und verarbeiten können.
Das Speichern dieser Vektoren in LanceDB, einer Serverless-Vektordatenbank, die von Amazon S3 unterstützt wird, erleichtert das effiziente Abrufen und Verwalten und stellt sicher, dass nur relevante Informationen zur Erweiterung der Antworten des LLM verwendet werden. Dieser Ansatz verbessert nicht nur die Genauigkeit und Relevanz der generierten Inhalte, sondern reduziert auch die Betriebskosten erheblich, da ein Pay-for-What-You-Use-Modell genutzt wird.
Hier können Sie sich den Code ansehen.
Was sind Einbettungen?
Im Bereich der natürlichen Sprachverarbeitung (NLP) sind Einbettungen ein zentrales Konzept, das die Übersetzung von Textinformationen in eine numerische Form ermöglicht, die Maschinen verstehen und verarbeiten können. Sie sind eine Möglichkeit, semantische Beziehungen in geometrische Beziehungen zu übersetzen, etwas, das Computer viel besser verstehen können als menschliche Sprache. Im Wesentlichen wandeln wir durch die Einbettung den Inhalt eines Dokuments in Vektoren in einer hochdimensionalen Umgebung um. Auf diese Weise erhält der geometrische Abstand in dieser Umgebung eine semantische Bedeutung. In dieser Umgebung sind Vektoren, die unterschiedliche Konzepte repräsentieren, weit voneinander entfernt, und ähnliche Konzepte werden in Gruppen zusammengefasst.
Dies wird durch Modelle wie Amazon Titan Embedding erreicht, das neuronale Netzwerke einsetzt, die auf umfangreichen Textkorpora trainiert wurden, um die Wahrscheinlichkeit zu berechnen, dass Wortgruppen in verschiedenen Kontexten zusammen auftreten.
Glücklicherweise müssen Sie dieses System nicht von Grund auf neu aufbauen. Bedrock ist dazu da, den Zugang zu Einbettungsmodellen sowie zu anderen grundlegenden Modellen zu ermöglichen.
Ich habe meine Wissensdatenbank eingebettet, was nun?
Sie müssen sie irgendwo speichern! In einer Vektordatenbank, um genau zu sein. Und genau hier findet die wahre Serverless-Magie statt.
LanceDB ist eine Open-Source-Vektordatenbank für die Vektorsuche mit persistenter Speicherung, die das Abrufen, Filtern und Verwalten von Einbettungen vereinfacht. Das herausragende Merkmal für uns war die Möglichkeit, LanceDB direkt mit S3 zu verbinden. Auf diese Weise benötigen wir keine Leerlaufberechnungen. Wir verwenden die Datenbank nur, während die Lambda-Funktion ausgeführt wird. Unsere Lasttests haben gezeigt, dass wir Dokumente mit einer Größe von bis zu 500 MB einlesen können, ohne dass LanceDB, Bedrock oder Lambda ins Schwitzen geraten.
Eine bekannte Einschränkung dieses Systems sind Lambda-Kaltstarts, aber wir haben gemessen, dass der Prozess, der die meiste Zeit in Anspruch nimmt, tatsächlich die Berechnung der Einbettungen ist, die außerhalb von Lambda stattfindet. Wir haben gemessen, dass unsere Nutzerbasis nur in 10% der Fälle von Kaltstarts betroffen ist. Um dies abzumildern, können Sie in einer nächsten Phase eines MVP über die Erstellung von Batch-Aufträgen nachdenken und möglicherweise andere Serverless AWS-Services wie Batch oder ECS Fargate nutzen, wobei Sie auch die Spotpreise nutzen können, um noch mehr zu sparen.
Abfragen
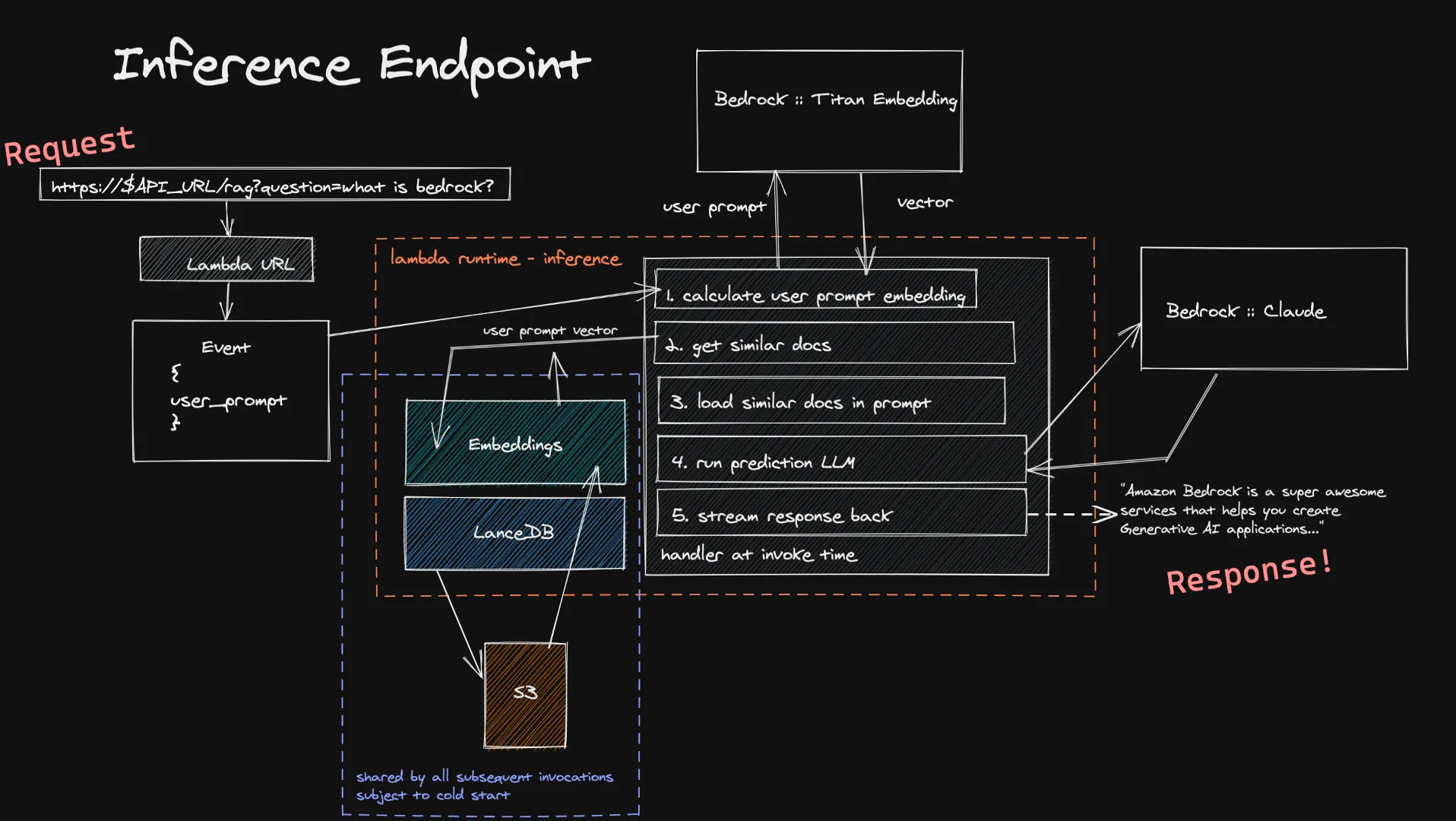
Benutzer können ihre Eingaben über Lambda URL an unsere Inferenzfunktion weiterleiten. Diese wird über Bedrock in das Titan Embedding-Modell eingespeist, das einen Vektor berechnet. Anhand dieses Vektors suchen wir dann in unseren Vektordatenbanken nach einer Handvoll ähnlicher Dokumente und fügen sie dem endgültigen Prompt hinzu. Wir senden die endgültige Eingabeaufforderung an das LLM, das der Benutzer ausgewählt hat, und wenn es Streaming unterstützt, wird die Antwort in Echtzeit an den Benutzer zurückgestreamt. Auch hier gibt es keine langwierigen Leerlaufberechnungen, und da die Benutzereingaben in der Regel kleiner sind als die Dokumente, die wir einlesen, können Sie mit kürzeren Zeiten für die Berechnung der Einbettung rechnen.
Eine bekannte Einschränkung dieses Inferenzsystems ist das Kaltstarten unserer Vektordatenbank innerhalb einer neuen Lambda-Funktion. Da LanceDB auf eine in S3 gespeicherte Datenbank verweist, müssen wir bei der Erstellung einer neuen Lambda-Ausführungsumgebung die Datenbank laden, um unsere Vektorsuchen durchführen zu können. Dies geschieht nur dann, wenn Sie die Skalierung erhöhen oder eine Zeit lang niemand eine Frage gestellt hat, d. h. es ist ein eher kleiner Kompromiss für die Kosteneinsparungen einer vollständig Serverless-Architektur.
Hier können Sie sich den Code ansehen.
Überblick über die Wirtschaftlichkeit von Serverless-RAG
Für die Einführung von Serverless RAG ist es entscheidend, die Kostenfolgen zu verstehen. Das Preismodell von Amazon Bedrock, das auf der Token-Nutzung und dem Serverless-Ressourcenverbrauch basiert, ermöglicht es Entwicklern, die Kosten genau abzuschätzen. Ganz gleich, ob es um die Verarbeitung von Dokumenten für die Einbettung oder um die Abfrage des Modells für Antworten geht, die nutzungsabhängige Preisberechnung stellt sicher, dass die Kosten direkt an die Nutzung gebunden sind, so dass Sie nur für das bezahlen, was Sie auch nutzen.

Ökonomie der Zuführung
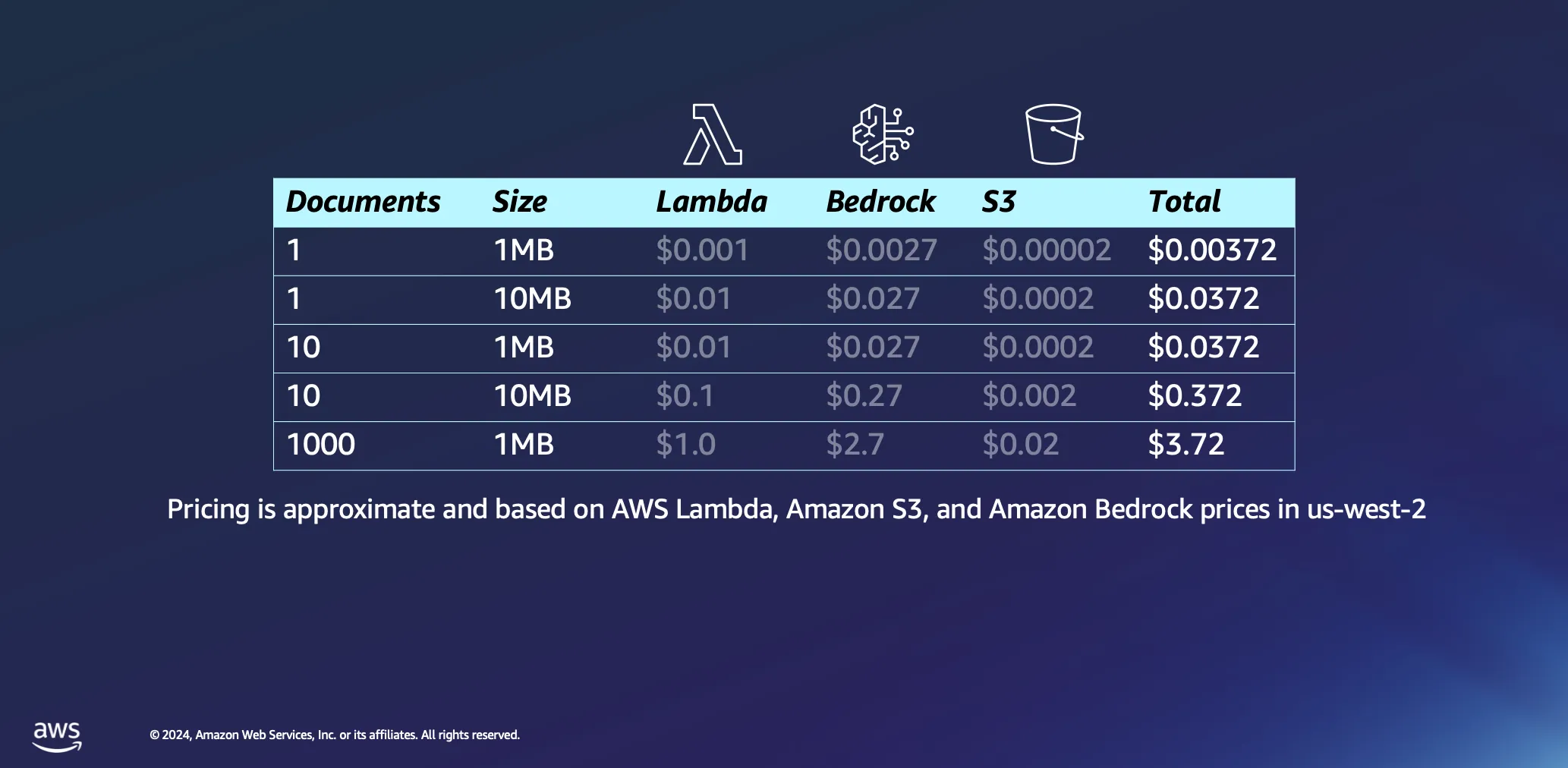
Lassen Sie uns ein wenig tiefer in die Wirtschaftlichkeit der Verwendung von Serverless-Architekturen für die Dokumentenverarbeitung eintauchen. Wir gehen bei unseren Berechnungen von einigen Annahmen aus: Die Verarbeitungszeit wird grob auf 1 Minute pro Megabyte Daten geschätzt, und ein Dokument dieser Größe enthält in der Regel knapp 30.000 Token. Auch wenn diese Zahlen einen Richtwert darstellen, ist die Realität oft günstiger, da viele Dokumente deutlich schneller verarbeitet werden.
Die Verarbeitung eines einzigen 1 MB großen Dokuments verursacht nur minimale Kosten, in den meisten Fällen weniger als einen halben Cent. Bei einer Skalierung auf tausend Dokumente mit einer Größe von jeweils 1 MB bleiben die Gesamtkosten bemerkenswert niedrig, nämlich unter 4 USD. Dieses Beispiel zeigt nicht nur die Kosteneffizienz von Serverless-Architekturen für die Dokumentenverarbeitung, sondern verdeutlicht auch die Effizienz des Token-basierten Preismodells, das in Plattformen wie Amazon Bedrock verwendet wird. Auch dies ist ein einmaliger Vorgang: Sobald Sie Ihre Dokumente verarbeitet haben, verbleiben sie in Ihrer Vektordatenbank, bis Sie sich entscheiden, sie zu löschen.
Die Wirtschaftlichkeit des Abfragens
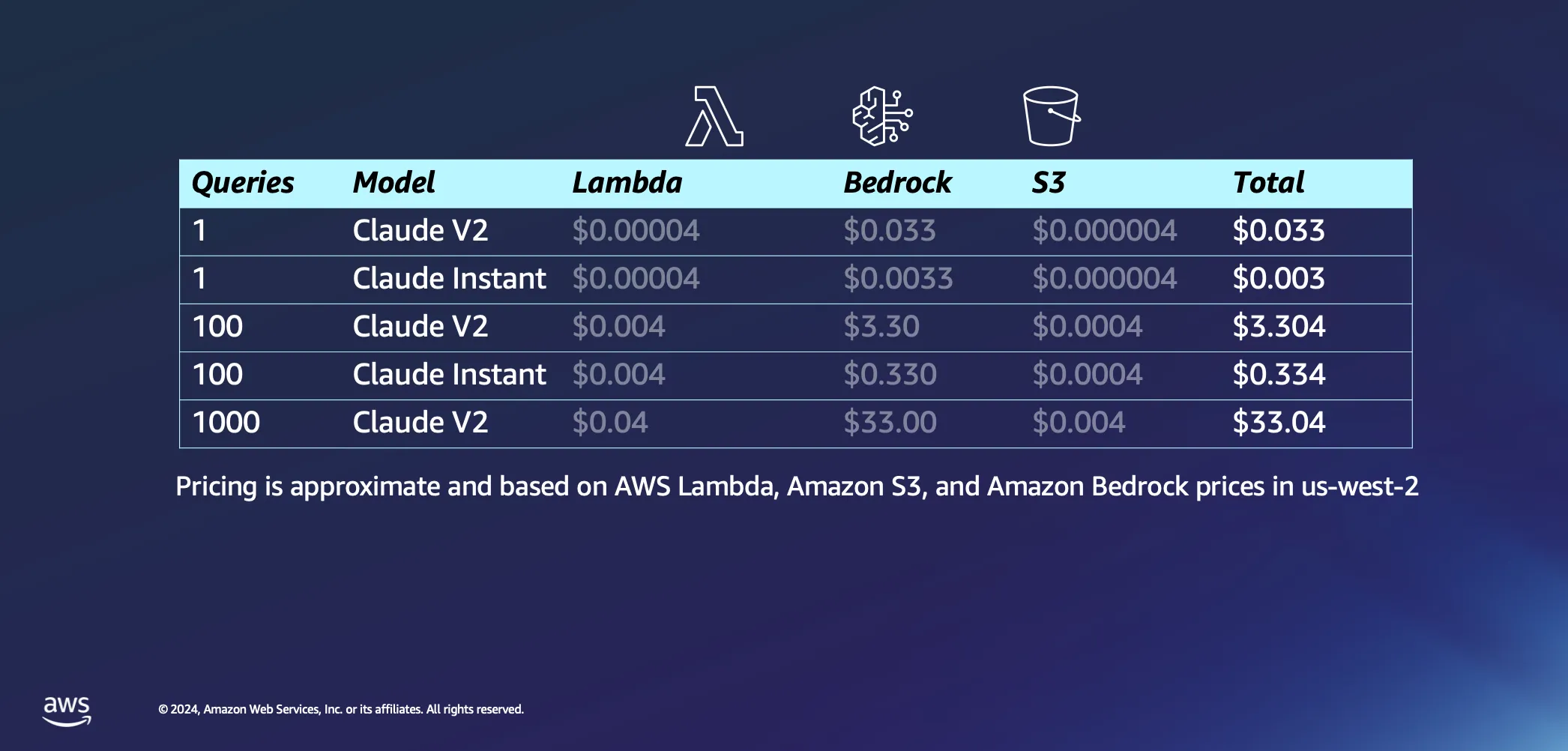
Kommen wir nun zum interaktiven Teil unseres Setups. Lassen Sie uns darüber sprechen, was passiert, wenn Sie Ihrer KI tatsächlich einige Fragen stellen. Hier sind einige unserer Annahmen: Wir gehen davon aus, dass es etwa 20 Sekunden dauert, bis AWS Lambda unseren Prompt mit einer Antwort an Sie zurückschickt, und wir gehen davon aus, dass jede Frage und ihre Antwort jeweils etwa 1000 Token umfasst. Im Vergleich zu den Kosten für die Ableitung sind die mit den Anfragen an S3 verbundenen Gebühren vernachlässigbar.
Nachdem wir die Annahmen aus dem Weg geräumt haben, lassen Sie uns zu den Kosten kommen. Eine einzige Anfrage an das Modell Claude V2 von Anthropic kostet etwa 3 Cent. Wenn Sie sich für ein etwas leichteres Modell wie Claude Instant entscheiden, sinken die Kosten drastisch auf einen Bruchteil eines Cents pro Abfrage. Wenn Sie das auf 1000 Abfragen mit Claude V2 erhöhen, kommen Sie auf Gesamtkosten von etwa 33 USD. Das deckt die gesamte Reise ab – das Senden Ihrer Frage an das LLM, das Abrufen ähnlicher Dokumente aus Ihrer Datenbank, um Ihre Anfrage anzureichern und mit kontextbezogenen Dokumenten zu verknüpfen, und das Erhalten einer maßgeschneiderten Antwort.
Das eigentliche Sahnehäubchen an diesem ganzen Setup ist, dass es dank seiner Serverless-Natur so konzipiert ist, dass es auf Anfragebasis funktioniert. Das bedeutet, dass Sie immer nur für das bezahlen, was Sie nutzen.
Erweiterung des Horizonts mit Serverless RAG
Mit Blick auf die Zukunft gehen die potenziellen Anwendungen von Serverless RAG weit über die aktuellen Anwendungsfälle hinaus. Durch die Einbeziehung zusätzlicher Strategien wie die Neueinstufung von Modellen nach Relevanz, die Einbettung von Adaptern für eine verbesserte semantische Suche und die Erforschung der Integration multimodaler Informationen können Entwickler ihre Anwendungen in der generativen KI weiter verfeinern und ausbauen.
Die Unterstützung von Amazon Bedrock für Serverless RAG eröffnet neue Wege für Innovationen auf dem Gebiet der generativen KI. Indem AWS die Einstiegshürden senkt und eine skalierbare, kosteneffiziente Plattform anbietet, ermöglicht es Entwicklern, das volle Potenzial von KI-gesteuerten Anwendungen auszuschöpfen. Während wir die Möglichkeiten von Serverless RAG weiter erforschen und ausbauen, sind die Möglichkeiten für die Entwicklung intelligenter, reaktionsschneller und relevanter KI-Lösungen grenzenlos. Begleiten Sie uns auf dieser Reise und entdecken Sie, wie Serverless RAG auf Amazon Bedrock Ihre KI-Projekte in die Realität umsetzen kann.
Ressourcen

Giuseppe Battista
Giuseppe Battista ist Senior Solutions Architect bei Amazon Web Services. Er leitet die Lösungsarchitektur für Startups in der Frühphase in Großbritannien und Irland. Er moderiert die Twitch-Show „Let's Build a Startup“ auf twitch.tv/aws und leitet den Accelerator von Unicorn‘s Den.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison ist Senior Solutions Architect bei Amazon Web Services. Er hat Hunderten von Startups geholfen, schnell in die Cloud zu starten. Kevin konzentriert sich darauf, Gründern in der frühesten Phase mit Codebeispielen und Twitch-Livestreams zu helfen.
Wie war dieser Inhalt?