¿Qué le pareció este contenido?
Generación aumentada de recuperación (RAG) sin servidor en AWS
En el panorama cambiante de la IA generativa, la integración de información externa y actualizada en modelos de lenguaje grandes (LLM) representa un avance significativo. En esta publicación, se desarrollará una solución de generación aumentada de recuperación (RAG) verdaderamente sin servidor, que facilite la creación de aplicaciones que produzcan respuestas más precisas y pertinentes desde el punto de vista del contexto. Nuestro objetivo es ayudarlo a crear su aplicación impulsada por IA generativa lo más rápido posible, sin dejar de controlar sus costos y de asegurarse de no pagar por la computación que no está utilizando.
RAG sin servidor: información general
La RAG sin servidor combina las capacidades avanzadas de procesamiento del lenguaje de los modelos de base con la agilidad y la rentabilidad de la arquitectura sin servidor. Esta integración permite la recuperación dinámica de información de orígenes externos, ya sean bases de datos, Internet o bases de conocimiento personalizadas, lo que permite generar contenido que no solo sea preciso y rico en contexto, sino que también esté actualizado con la información más reciente.
Amazon Bedrock simplifica la implementación de aplicaciones de RAG sin servidor y ofrece a los desarrolladores las herramientas para crear, administrar y escalar sus proyectos de IA generativa sin la necesidad de una administración exhaustiva de la infraestructura. Además, los desarrolladores pueden aprovechar la potencia de los servicios de AWS, como Lambda y S3, junto con las innovadoras bases de datos vectoriales de código abierto, como LanceDB, para crear soluciones impulsadas por la IA rentables y con capacidad de respuesta.
Ingesta de documentos
El camino hacia su solución de RAG sin servidor está conformado por varios pasos clave. Cada uno está diseñado para garantizar la integración perfecta de los modelos de base con el conocimiento externo.
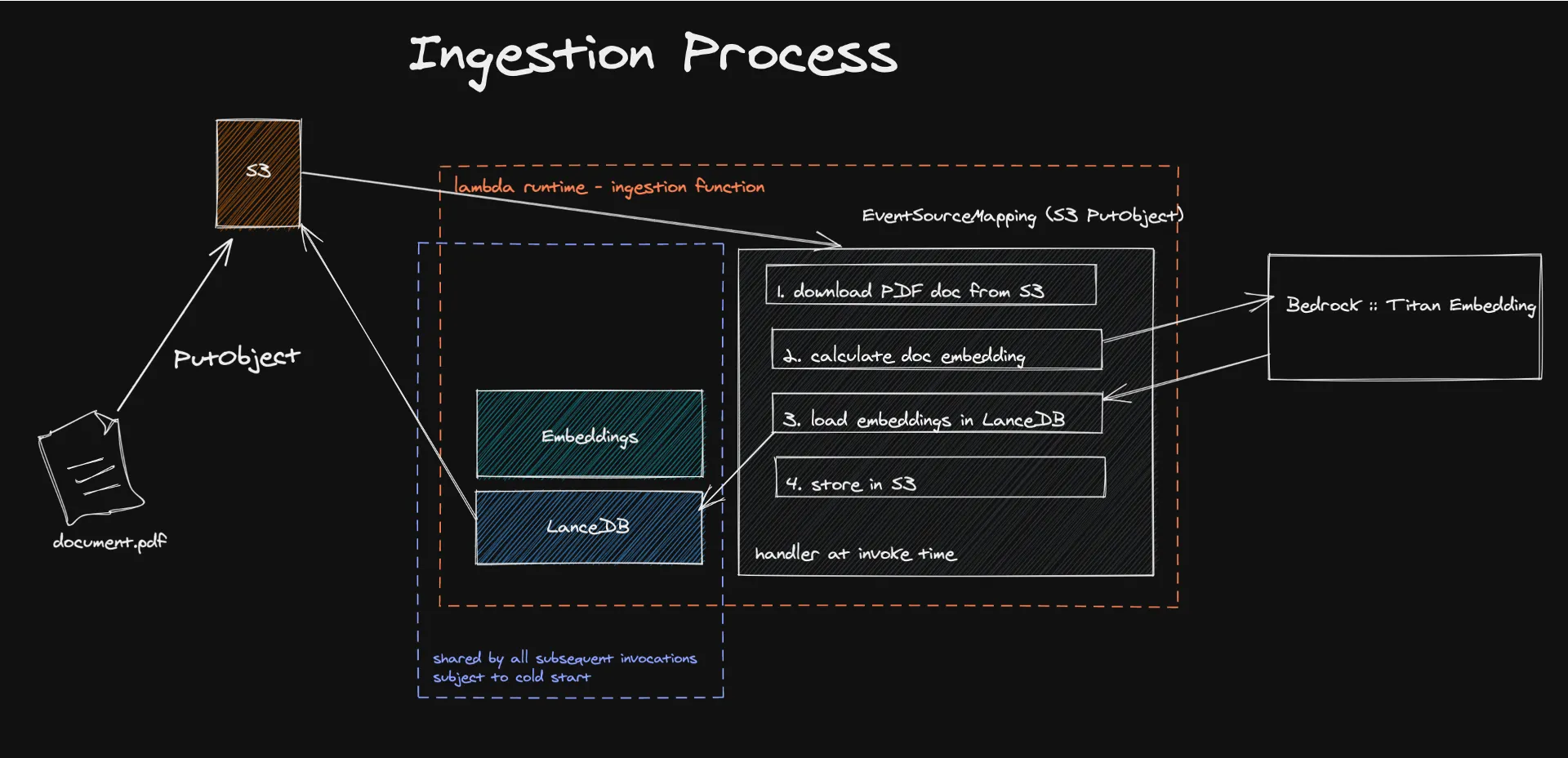
El proceso comienza con la ingesta de documentos en una arquitectura sin servidor, donde los mecanismos impulsados por eventos desencadenan la extracción y el procesamiento del contenido textual para generar incrustaciones. Estas incrustaciones, creadas con modelos como Amazon Titan, transforman el contenido en vectores numéricos que las máquinas pueden entender y procesar fácilmente.
El almacenamiento de estos vectores en LanceDB, una base de datos vectorial sin servidor respaldada por Amazon S3, facilita la recuperación y la administración eficientes y garantiza que solo se utilice la información pertinente para aumentar las respuestas del LLM. Este enfoque no solo mejora la precisión y la pertinencia del contenido generado, sino que también reduce significativamente los costos operativos al aprovechar un modelo de pago por uso.
Eche un vistazo al código aquí.
¿Qué son las incrustaciones?
En el ámbito del procesamiento de lenguaje natural (NLP), las incrustaciones son un concepto fundamental que permite la traducción de la información textual a un formato numérico que las máquinas puedan entender y procesar. Es una forma de traducir las relaciones semánticas en relaciones geométricas, algo que los equipos pueden entender mucho mejor que el lenguaje humano. Básicamente, mediante la incrustación, se transformará el contenido de un documento en vectores en un espacio de alta dimensión. De esta manera, la distancia geométrica en este espacio adquiere un significado semántico. En este espacio, los vectores que representan diferentes conceptos estarán alejados unos de otros y los conceptos similares se agruparán.
Esto se logra con modelos como Amazon Titan Embedding, que usa redes neuronales entrenadas en enormes corpus de texto para calcular la probabilidad de que grupos de palabras aparezcan juntas en varios contextos.
Por suerte, no es necesario crear este sistema desde cero. Bedrock es de gran utilidad para proporcionar acceso a los modelos de incrustación, así como a otros modelos de base.
La base de conocimientos está incrustada, ¿y ahora qué?
Tiene que guardarlos en algún sitio. Una base de datos vectorial, para ser precisos. Y aquí es donde ocurre la verdadera magia sin servidores.
LanceDB es una base de datos vectorial de código abierto diseñada para la búsqueda vectorial con almacenamiento persistente, lo que simplifica la recuperación, el filtrado y la administración de las incrustaciones. La característica más destacada para nosotros fue la capacidad de conectar LanceDB directamente a S3. De esta forma, no necesitamos computación inactiva. Se usará la base de datos solo mientras se esté ejecutando la función de Lambda. Nuestras pruebas de carga han demostrado que podemos ingerir documentos de hasta 500 MB sin que LanceDB, Bedrock o Lambda hagan un esfuerzo significativo.
Una limitación conocida de este sistema son los arranques en frío de Lambda. Sin embargo, hemos determinado que el proceso que lleva más tiempo es, en realidad, el cálculo de las incrustaciones que ocurre fuera de Lambda. Hemos podido descubrir que nuestra base de usuarios se ve afectada por el arranque en frío solo en el 10 % de los casos. Para paliar este problema, puede crear trabajos por lotes en la siguiente fase de un MVP y, posiblemente, utilizar otros servicios de AWS sin servidor, como Batch o ECS Fargate, y aprovechar también los precios de las instancias de spot para ahorrar aún más.
Consultas
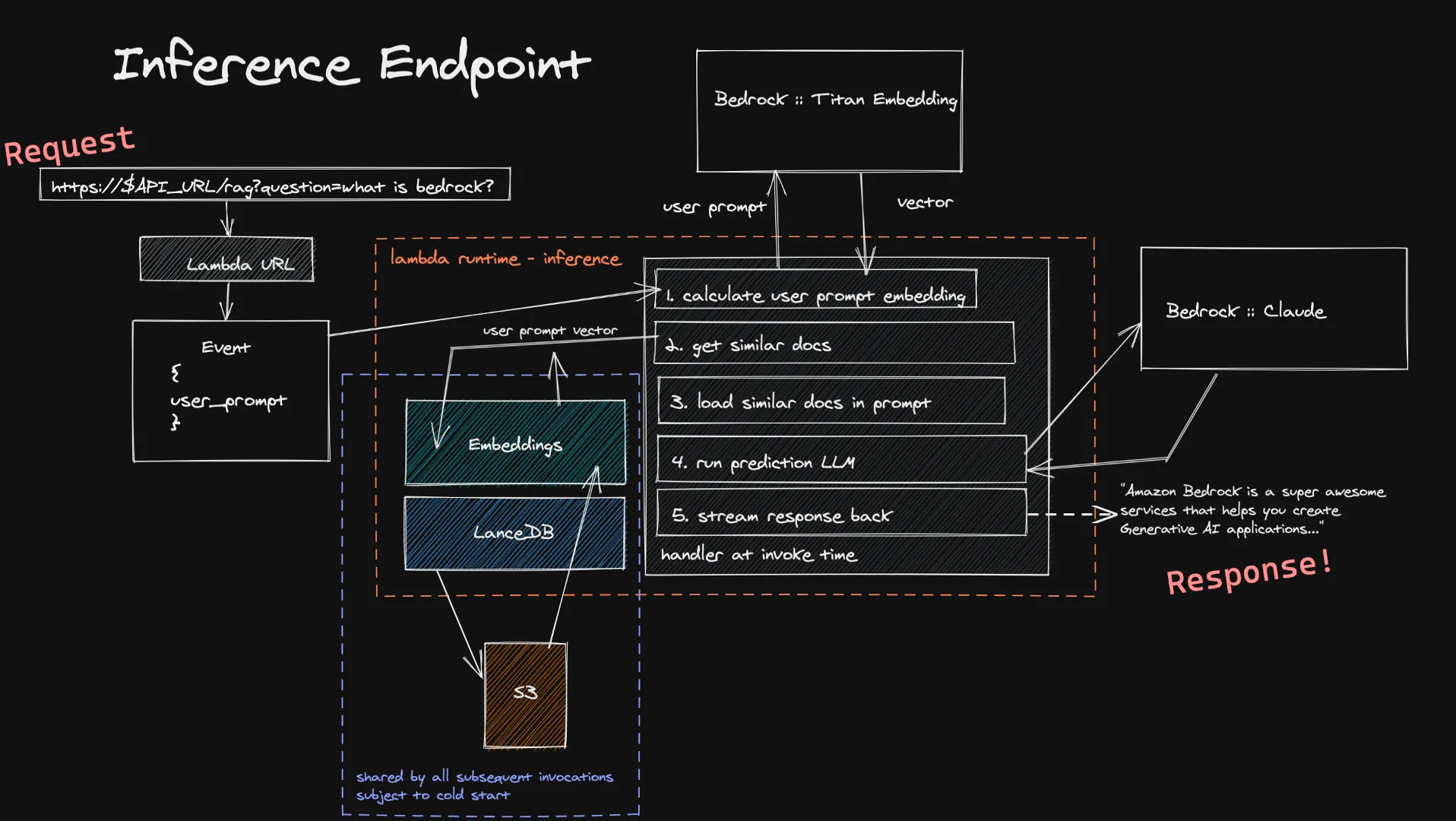
Los usuarios pueden reenviar sus datos a nuestra función de inferencia a través de la URL de Lambda. Esto se introduce en el modelo Titan Embedding a través de Bedrock, que calcula un vector. Luego se usa este vector para obtener un grupo de documentos similares en las bases de datos vectoriales y se agregan al mensaje final. Se envía la última solicitud al LLM que el usuario eligió y, si admite la transmisión, la respuesta se transmite en tiempo real al usuario. Una vez más, no se trata de cálculos inactivos que duren mucho tiempo y, dado que los datos que ingresa el usuario suelen ser más pequeños que los documentos que ingerimos, es posible calcular su incrustación en menos tiempo.
Una limitación conocida de este sistema de inferencia es la puesta en marcha en frío de nuestra base de datos vectorial dentro de una nueva función de Lambda. Dado que LanceDB hace referencia a una base de datos almacenada en S3, cuando se crea un nuevo entorno de ejecución de Lambda, tenemos que cargar la base de datos para poder realizar nuestras búsquedas vectoriales. Esto solo ocurre cuando se está escalando verticalmente o cuando nadie ha hecho una pregunta durante mucho tiempo, lo que significa que es una pequeña compensación por el ahorro de costos que supone una arquitectura totalmente sin servidores.
Eche un vistazo al código aquí.
Cómo explorar los aspectos económicos de la RAG sin servidor
Comprender las implicaciones financieras es crucial para adoptar la RAG sin servidor. El modelo de precios de Amazon Bedrock, basado en el uso de tokens y el consumo de recursos sin servidor, permite a los desarrolladores estimar los costos con precisión. Ya sea que procesen documentos para incrustarlos o consulten el modelo para obtener respuestas, los precios de pago por uso garantizan que los costos estén directamente relacionados con el uso, de modo que pague solo por lo que utilice.

Aspectos económicos de la ingesta
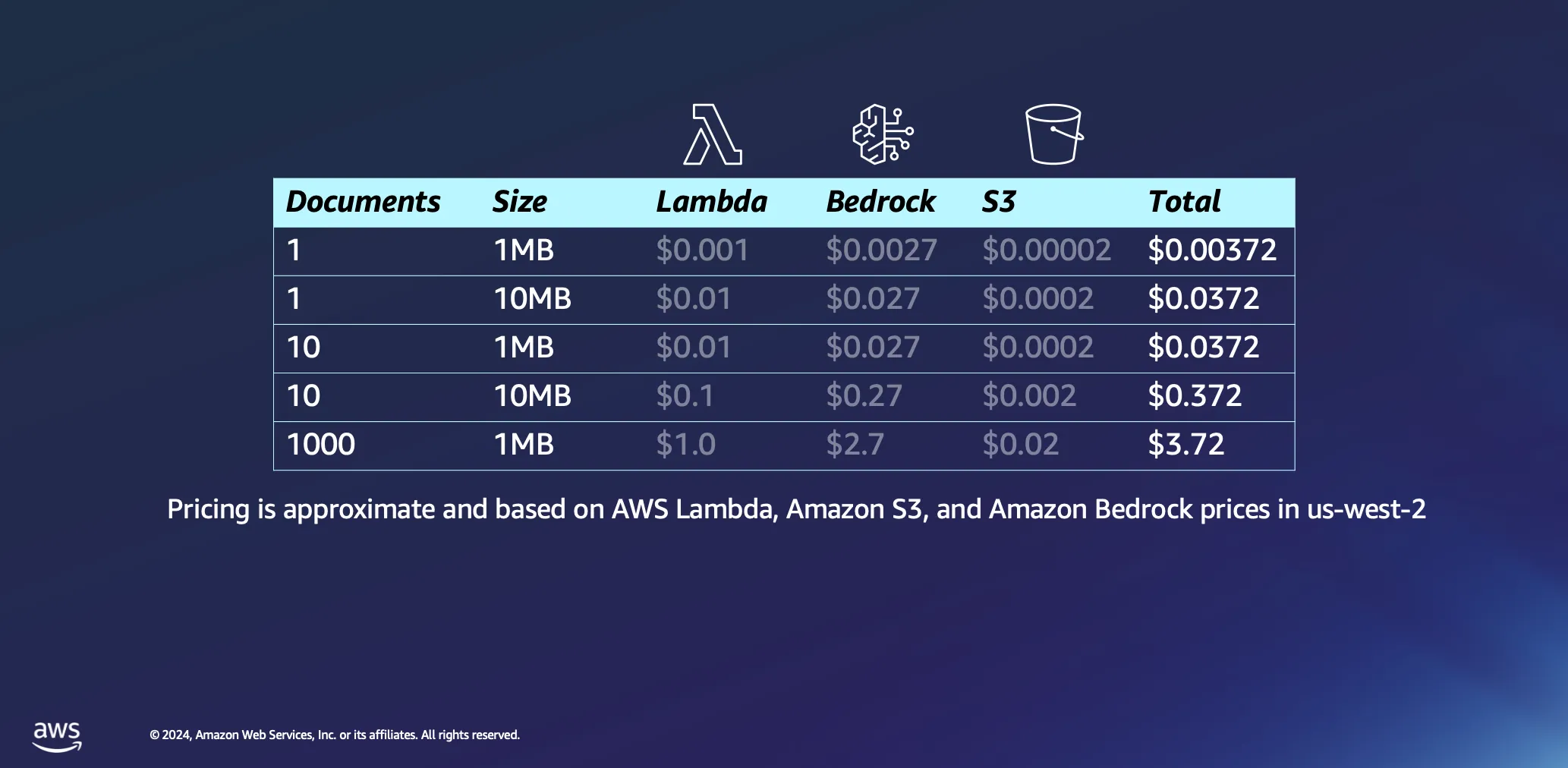
Profundicemos un poco más en los aspectos económicos del uso de arquitecturas sin servidor para el procesamiento de documentos. Basamos nuestros cálculos en un par de suposiciones: el tiempo de procesamiento se estima aproximadamente en 1 minuto por megabyte de datos y un documento de este tamaño normalmente contiene algo menos de 30 000 tokens. Si bien estas cifras proporcionan una línea de base, la realidad suele ser más favorable, ya que muchos documentos se procesan mucho más rápido.
Procesar un único documento de 1 MB supone un gasto mínimo, menos de medio centavo en la mayoría de los casos. Al escalar verticalmente hasta mil documentos, cada uno de 1 MB de tamaño, el costo total sigue siendo notablemente bajo, por debajo de los 4 USD. Este ejemplo no solo demuestra la rentabilidad de las arquitecturas sin servidor para el procesamiento de documentos, sino que también pone en relieve la eficacia del modelo de precios basado en tokens que se utiliza en plataformas como Amazon Bedrock. Este también es un proceso único: una vez que haya procesado sus documentos, permanecerán en su base de datos vectorial hasta que decida eliminarlos.
Aspectos económicos de las consultas
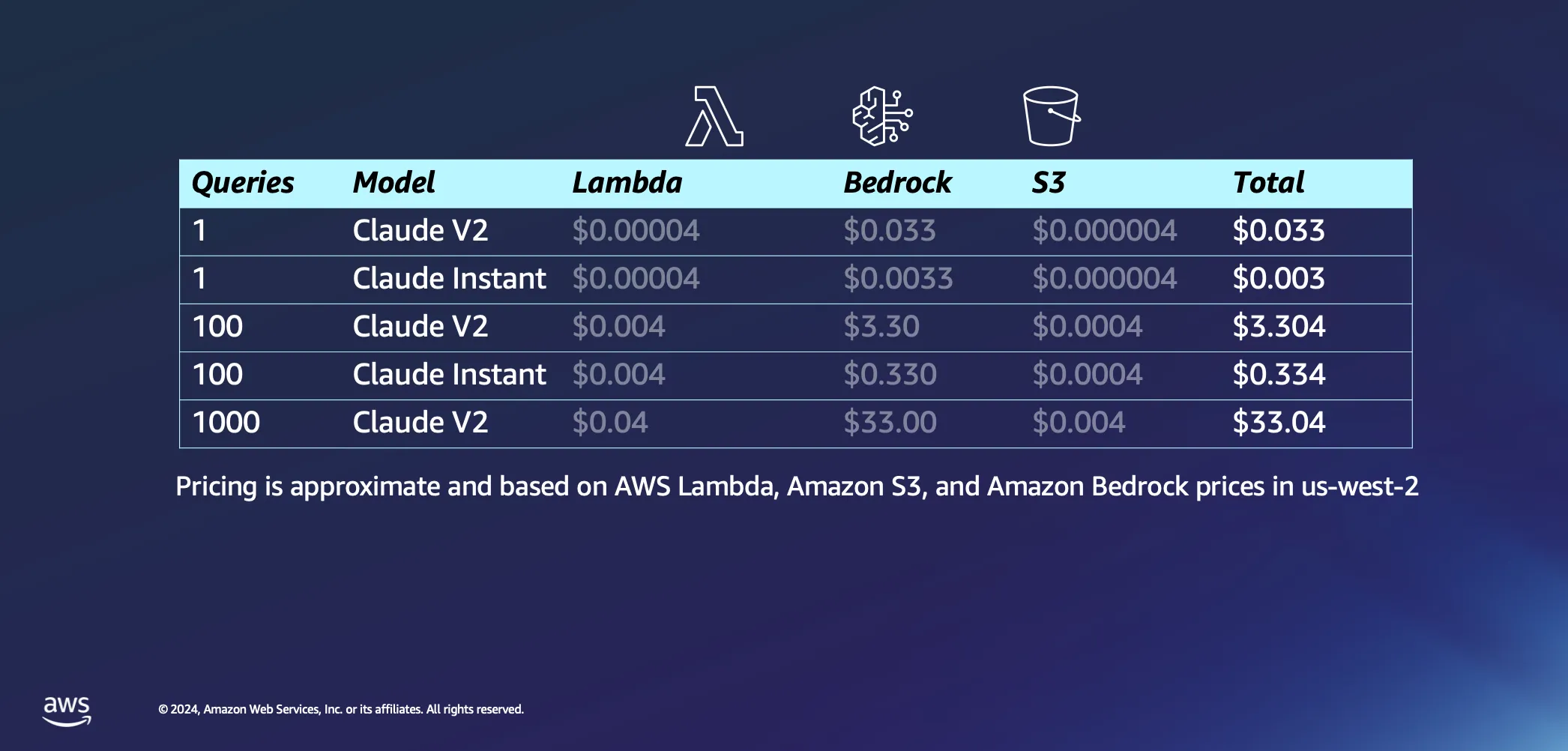
Si se pone el foco en la parte interactiva de nuestra configuración, se puede hablar de lo que ocurre cuando empieza a hacerle algunas preguntas a su IA. Estas son algunas de nuestras suposiciones: pensamos que AWS Lambda tardará unos 20 segundos en incorporar nuestro mensaje para responderle con una respuesta y asumimos que cada pregunta y su respuesta son aproximadamente 1000 tokens cada una. En comparación con el costo de inferencia, los cargos asociados a las solicitudes a S3 son insignificantes.
Dejando las suposiciones a un lado, analicemos los costos. Realizar una sola consulta al modelo Claude V2 de Anthropic va a costar unos 3 centavos. Si opta por algo un poco más ligero, como Claude Instant, el costo se reduce drásticamente a solo una fracción de centavo por consulta. Si aumenta la cantidad hasta 1000 consultas con Claude V2, tendrá un gasto total de alrededor de 33 USD. Esto abarca todo el proceso: enviar la pregunta al LLM, extraer documentos similares de la base de datos para enriquecer la consulta y vincularla a documentos contextuales, y obtener una respuesta personalizada.
El verdadero elemento diferenciador de toda esta configuración es la forma en que está diseñado para funcionar por solicitud, gracias a su naturaleza sin servidores. Esto significa que solo paga por lo que usa.
Ampliación de horizontes con la RAG sin servidor
De cara al futuro, las posibles aplicaciones de la RAG sin servidor van mucho más allá de los casos de uso actuales. Al incorporar estrategias adicionales, como cambiar la clasificación de los modelos según su relevancia, incrustar adaptadores para mejorar la búsqueda semántica y explorar la integración multimodal de la información, los desarrolladores pueden perfeccionar y ampliar aún más sus aplicaciones de IA generativa.
La compatibilidad de Amazon Bedrock con la RAG sin servidor abre nuevas vías para la innovación en el campo de la IA generativa. Al reducir las barreras de entrada y ofrecer una plataforma escalable y rentable, AWS permite a los desarrolladores explorar todo el potencial de las aplicaciones impulsadas por la IA. A medida que se continúa explorando y ampliando las capacidades de la RAG sin servidor, las posibilidades de crear soluciones de IA más inteligentes, con capacidad de respuesta y pertinentes son ilimitadas. Únase a nosotros en este viaje y descubra cómo la RAG sin servidor en Amazon Bedrock puede transformar sus proyectos de IA en realidad.
Recursos

Giuseppe Battista
Giuseppe Battista es Senior Solutions Architect en Amazon Web Services. Dirige la arquitectura de soluciones para startups en fase inicial en el Reino Unido e Irlanda. Presenta el programa de Twitch “Let's Build a Startup” en twitch.tv/aws y dirige la aceleradora Unicorn's Den.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison es Senior Solutions Architect en Amazon Web Services. Ha ayudado a cientos de startups a ponerse en marcha rápidamente y a migrar a la nube. Kevin se centra en ayudar a los fundadores desde sus inicios con muestras de código y retransmisiones en directo en Twitch.
¿Qué le pareció este contenido?