Com'era questo contenuto?
Retrieval Augmented Generation (RAG) serverless su AWS
Nel panorama in evoluzione dell'IA generativa, l'integrazione di informazioni esterne e aggiornate in modelli linguistici di grandi dimensioni (LLM) rappresenta un progresso significativo. In questo post, svilupperemo una soluzione Retrieval Augmented Generation (RAG) veramente serverless, in grado di semplificare la creazione di applicazioni che producono risposte più accurate e contestualmente pertinenti. Il nostro obiettivo è aiutarti a creare un'applicazione basata sull'IA generativa il più velocemente possibile, tenendo d'occhio i costi e assicurandoti di non pagare per la capacità di calcolo che non stai utilizzando.
RAG serverless: una panoramica
La RAG serverless combina le funzionalità avanzate di elaborazione del linguaggio dei modelli di fondazione con l'agilità e l'economicità dell'architettura serverless. Questa integrazione consente il recupero dinamico di informazioni da fonti esterne, che si tratti di database, Internet o knowledge base personalizzate, consentendo di generare contenuti accurati e ricchi di contesto, e inoltre aggiornati con le informazioni più recenti.
Amazon Bedrock semplifica l'implementazione di applicazioni RAG serverless offrendo agli sviluppatori gli strumenti per creare, gestire e dimensionare i loro progetti di IA generativa senza la necessità di una gestione estesa dell'infrastruttura. Inoltre, gli sviluppatori possono sfruttare la potenza di servizi AWS come Lambda e S3, insieme a innovativi database vettoriali open source come LanceDB, per creare soluzioni basate sull'IA reattive ed economiche.
Acquisizione di documenti
Il percorso verso una soluzione RAG serverless prevede diversi passaggi chiave, ciascuno studiato su misura per garantire la perfetta integrazione dei modelli di fondazione con le conoscenze esterne.
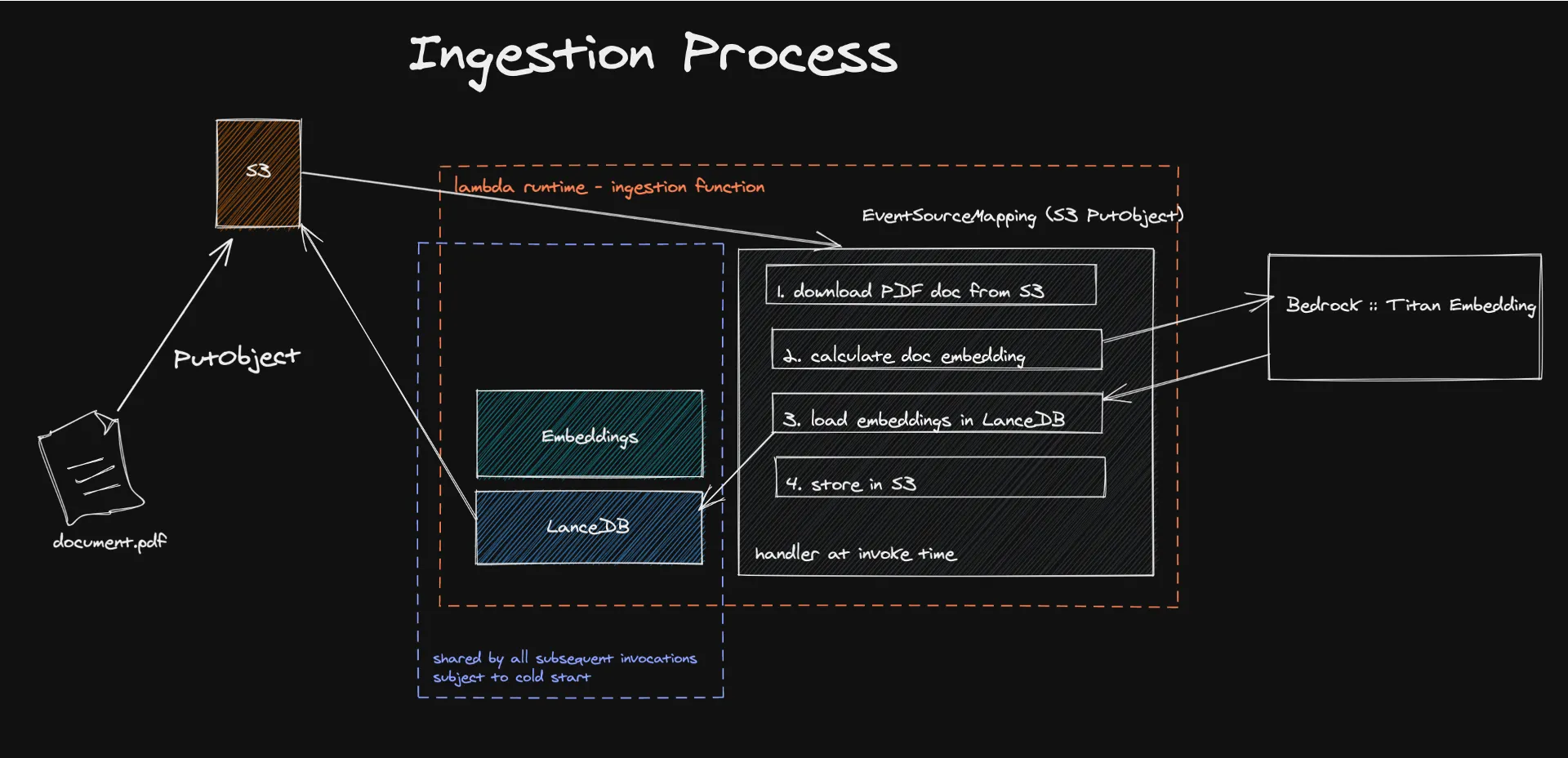
Il processo inizia con l'acquisizione di documenti in un'architettura serverless, dove meccanismi basati sugli eventi attivano l'estrazione e l'elaborazione del contenuto testuale per generare incorporamenti. Questi incorporamenti, creati utilizzando modelli come Amazon Titan, trasformano il contenuto in vettori numerici che le macchine possono facilmente comprendere ed elaborare.
L'archiviazione di questi vettori in LanceDB, un database vettoriale serverless supportato da Amazon S3, semplifica il recupero e l'amministrazione efficiente, garantendo l'uso esclusivo di dati pertinenti per ottimizzare le risposte del modello linguistico di grandi dimensioni (LLM). Tale strategia, incrementando l'accuratezza e la rilevanza dei contenuti creati, permette altresì una notevole riduzione dei costi operativi attraverso l'adozione di un modello di pagamento basato sul consumo effettivo.
Scopri di più sul codice qui.
Cosa sono gli incorporamenti?
Nel campo dell'elaborazione del linguaggio naturale (Natural Language Processing o NLP), gli incorporamenti rappresentano una tecnica fondamentale per convertire testi in formati numerici interpretabili dalle macchine. È un modo per tradurre le relazioni semantiche in relazioni geometriche, qualcosa che i computer possono comprendere molto meglio del linguaggio umano. Essenzialmente, tramite l'incorporamento, il testo di un documento viene trasformato in vettori all'interno di uno spazio multidimensionale, dove la prossimità geometrica acquisisce valore semantico: concetti simili risultano vicini, mentre quelli divergenti si distanziano.
Questo diventa possibile mediante l'impiego di modelli come Amazon Titan Embedding, che sfrutta reti neurali addestrate su vasti insiemi di dati testuali per determinare la probabilità che gruppi di parole compaiano insieme in vari contesti.
Fortunatamente non è necessario creare questo sistema da zero: Bedrock assolve proprio questo compito, fornendo l'accesso ai modelli di incorporamento e ad altri modelli di fondazione.
Ho incorporato la mia knowledge base, ora cosa devo fare?
Devi archiviarla da qualche parte. In un database vettoriale, per essere precisi. Ed è qui che avviene la vera magia serverless.
LanceDB è un database vettoriale open source progettato per la ricerca vettoriale con archiviazione persistente, che semplifica il recupero, il filtraggio e la gestione degli incorporamenti. La funzionalità principale per noi è stata la possibilità di connettere LanceDB direttamente a S3. In questo modo non abbiamo bisogno dell'elaborazione inattiva. Utilizzeremo il database solo mentre la funzione lambda è in esecuzione. I nostri test di carico hanno dimostrato che possiamo acquisire senza problemi documenti di dimensioni fino a 500 MB in LanceDB, Bedrock o Lambda.
Una limitazione nota di questo sistema sono gli avvii a freddo di Lambda, ma abbiamo constatato che il processo che richiede la maggior parte del tempo è in realtà il calcolo degli incorporamenti, che avviene fuori da Lambda. Abbiamo rilevato che la nostra base di utenti è interessata dagli avvii a freddo solo nel 10% dei casi. Per ovviare a questo problema, è possibile creare lavori in batch nella fase successiva di un MVP e potenzialmente utilizzare altri servizi AWS serverless come Batch o ECS Fargate, sfruttando anche i prezzi Spot per risparmiare ulteriormente.
Esecuzione di query
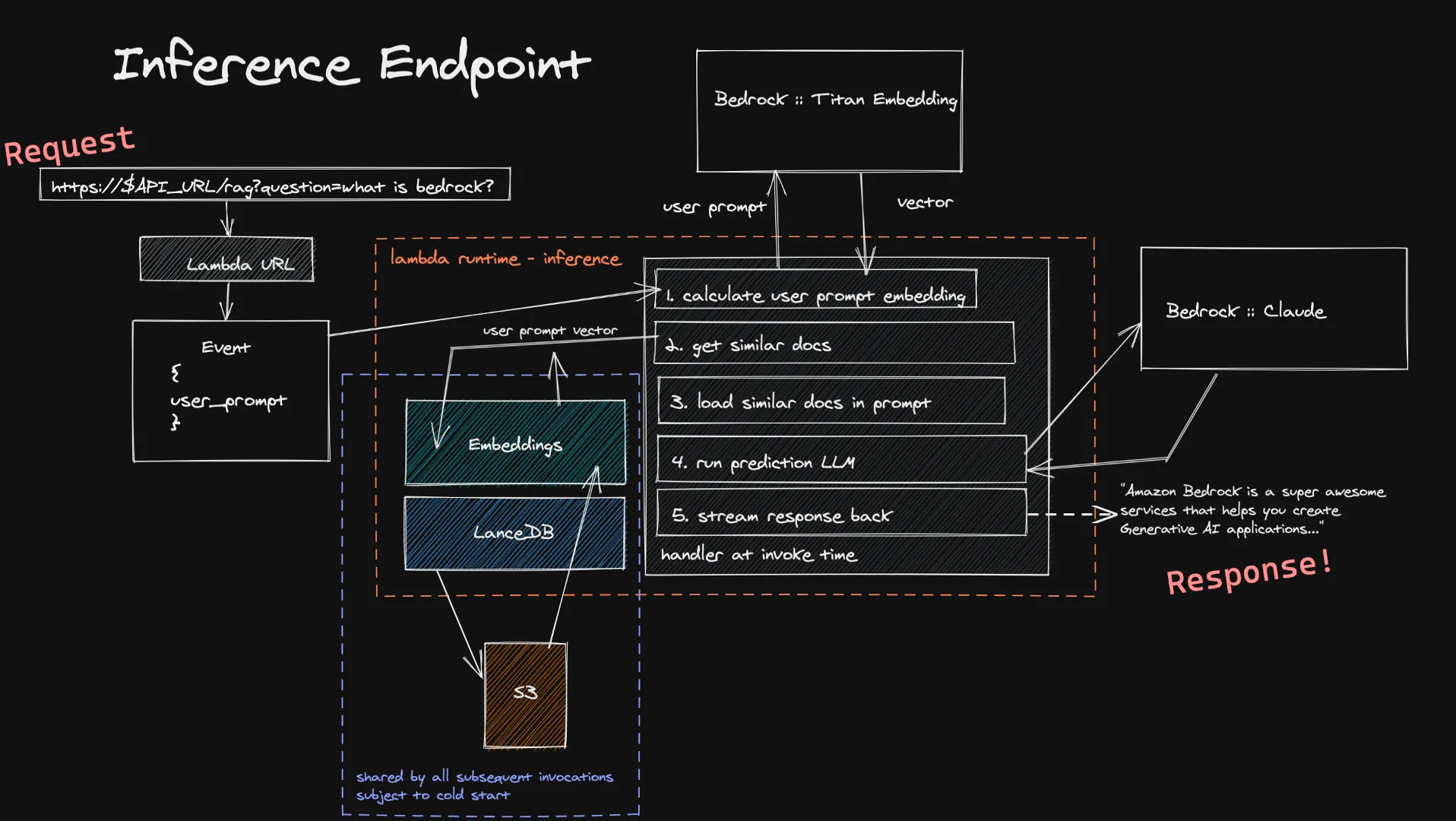
Gli utenti possono inoltrare il loro input alla nostra funzione di inferenza tramite l'URL di Lambda. Questo viene inserito nel modello Titan Embedding tramite Bedrock, che calcola un vettore. Utilizziamo quindi questo vettore per individuare un piccolo numero di documenti simili nei nostri database vettoriali e li aggiungiamo al prompt finale. Inviamo il prompt finale all'LLM scelto dall'utente e, se supporta lo streaming, la risposta viene trasmessa all'utente in tempo reale. Anche in questo caso non abbiamo calcoli inattivi di lunga durata e, poiché l'input dell'utente è generalmente inferiore ai documenti che acquisiamo, è possibile aspettarsi tempi più brevi per il calcolo del relativo incorporamento.
Una limitazione nota di questo sistema di inferenza è l'avvio a freddo del nostro database vettoriale all'interno di una nuova funzione Lambda. Poiché LanceDB fa riferimento a un database archiviato in S3, quando viene creato un nuovo ambiente di esecuzione Lambda, dobbiamo caricare il database per poter effettuare le nostre ricerche vettoriali. Questo scenario si verifica solo in caso di dimensionamento o quando non vi sono state richieste per un certo periodo, rendendolo un compromesso accettabile a fronte dei benefici in termini di costi offerti da un'architettura completamente serverless.
Scopri di più sul codice qui.
Analisi degli aspetti economici del RAG serverless
Capire le dinamiche di costo è cruciale per l'implementazione di RAG serverless. Il sistema tariffario di Amazon Bedrock, che si basa sui token utilizzati e sul consumo delle risorse serverless, consente agli sviluppatori di calcolare i costi in modo accurato. Sia che si tratti dell'elaborazione dei documenti da incorporare o di consultare il modello per ottenere risposte, i prezzi con pagamento in base al consumo assicurano che i costi siano direttamente collegati all'utilizzo, in modo da pagare solo le risorse effettivamente impiegate.

Aspetti economici dell'acquisizione
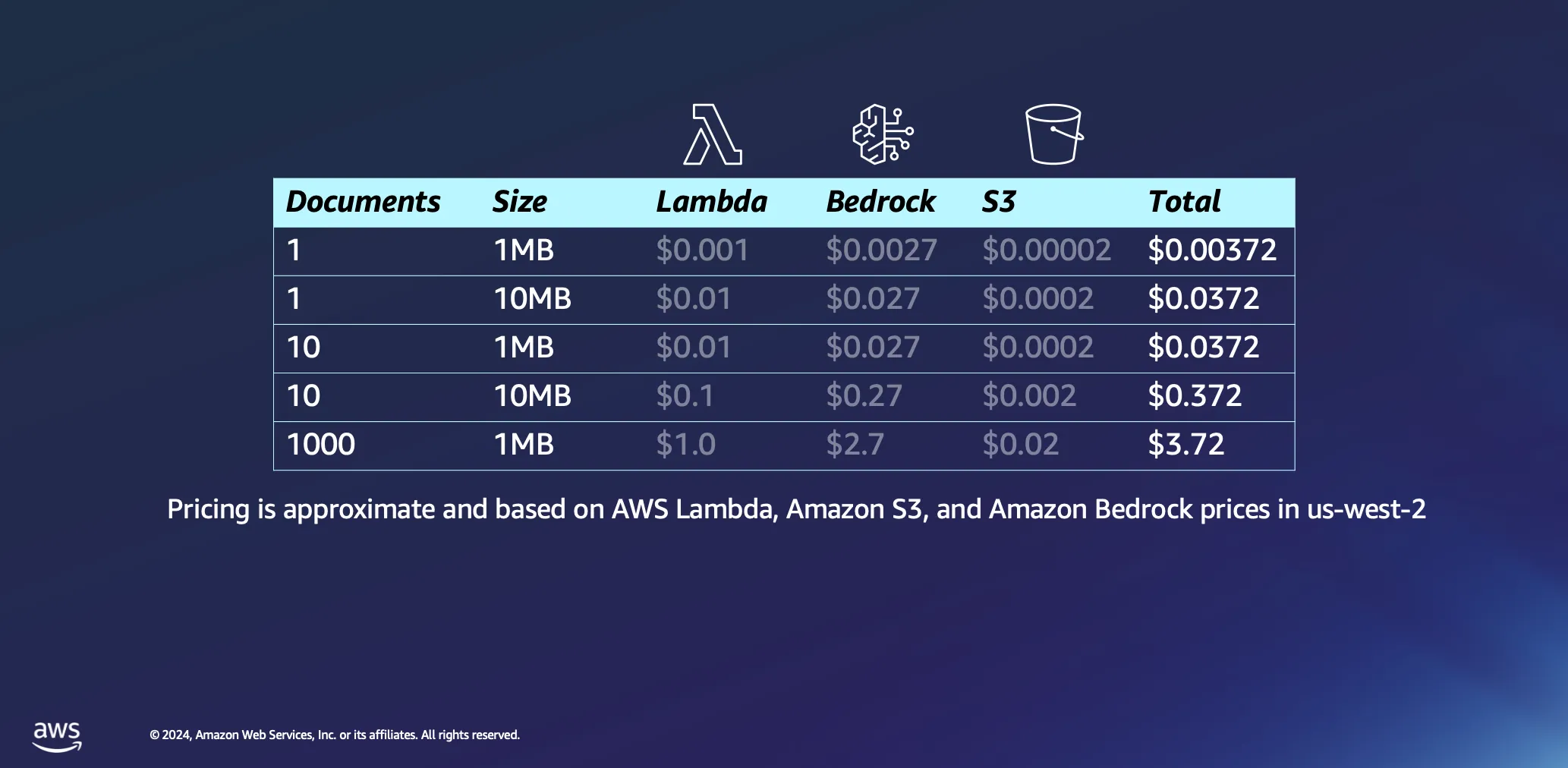
Analizziamo un po' più a fondo gli aspetti economici dell'utilizzo di architetture serverless per l'elaborazione dei documenti. Basiamo i nostri calcoli su un paio di ipotesi: il tempo di elaborazione è stimato all'incirca in 1 minuto per megabyte di dati e un documento di queste dimensioni contiene in genere poco meno di 30.000 token. Anche se queste stime rappresentano una base di riferimento, nella pratica la situazione è spesso più vantaggiosa, con numerosi documenti che vengono processati in tempi notevolmente inferiori.
Nella maggior parte dei casi, l'elaborazione di un singolo documento da 1 MB comporta una spesa minima, inferiore a mezzo centesimo. Quando si sale fino a mille documenti, ciascuno da 1 MB, il costo totale rimane notevolmente basso, inferiore a 4 dollari. Questo esempio non solo dimostra l'economicità delle architetture serverless per l'elaborazione dei documenti, ma evidenzia anche l'efficienza del modello di prezzo basato su token utilizzato in piattaforme come Amazon Bedrock. Anche questo è un processo una tantum: una volta elaborati, i documenti rimarranno nel database vettoriale fino a quando non si deciderà di eliminarli.
Aspetti economici dell'esecuzione di query
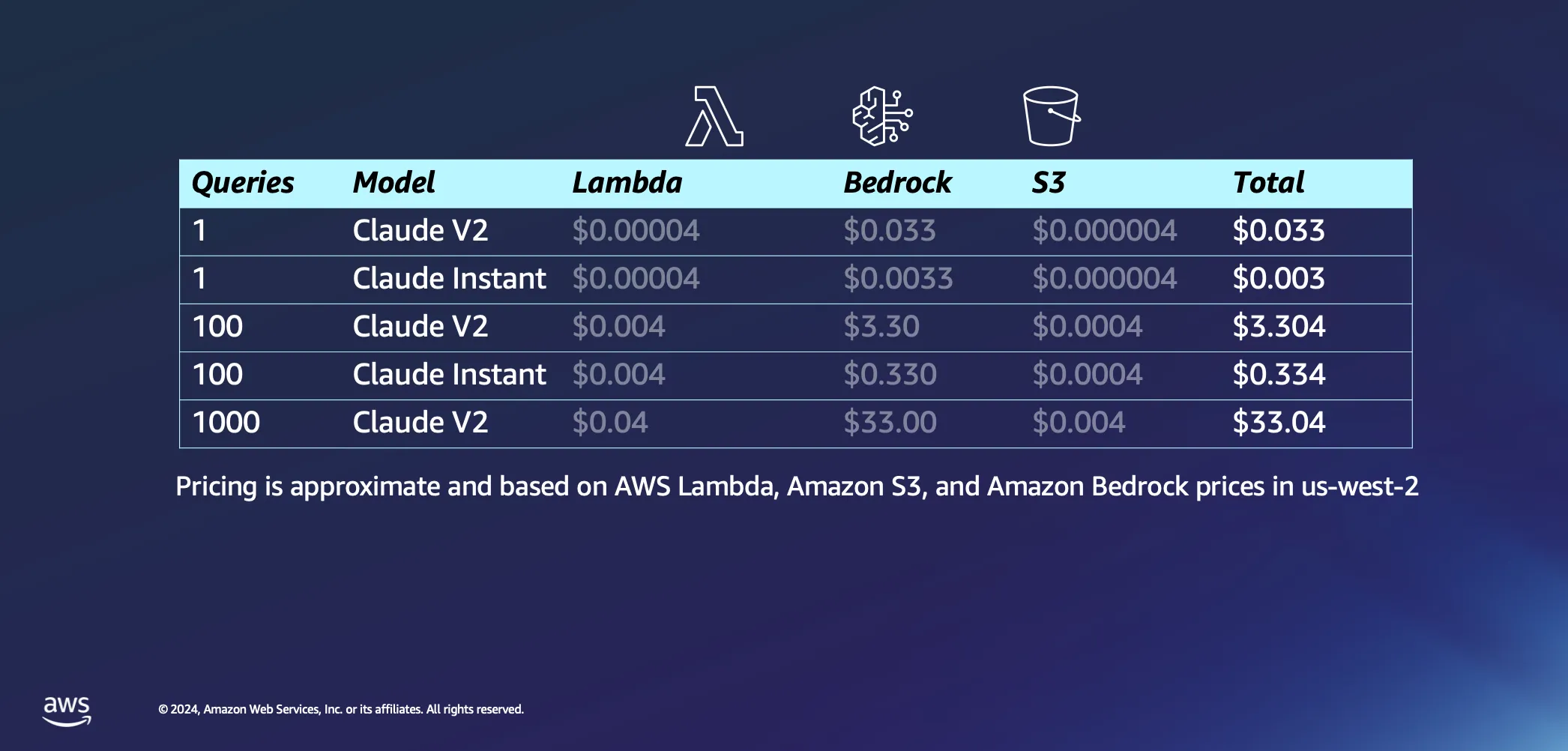
Passando alla parte interattiva della nostra configurazione, parliamo di cosa succede quando si inizia effettivamente a porre alcune domande all'intelligenza artificiale. Ecco alcune delle nostre ipotesi: pensiamo che AWS Lambda impiegherà circa 20 secondi per incorporare il nostro prompt e restituire una risposta, e supponiamo che ogni domanda e la relativa risposta siano di circa 1.000 token ciascuna. Rispetto al costo dell'inferenza, i costi associati alle richieste a S3 sono trascurabili.
Fatte salve le ipotesi, passiamo ai costi. Inviare una singola query al modello Claude V2 di Anthropic costerà circa 3 centesimi. Se si opta per qualcosa di un po' più leggero, come Claude Instant, il costo scende drasticamente fino a una frazione di centesimo per query. Se si aumentano fino a 1.000 query con Claude V2, si otterrà una spesa complessiva di circa 33 dollari. Questo copre l'intero percorso: invio della domanda all'LLM, estrazione di documenti simili dal database per arricchire e associare la domanda a documenti contestuali e ottenere una risposta personalizzata.
Il vero punto di forza di tutta questa configurazione è la sua progettazione orientata al funzionamento su richiesta, grazie alla sua natura serverless. Questo implica che si paga esclusivamente per le risorse effettivamente utilizzate, senza costi fissi.
Gli orizzonti si ampliano con la RAG serverless
In ottica futura, le potenziali applicazioni della RAG serverless vanno ben oltre i casi d'uso attuali. Incorporando strategie aggiuntive, come la riclassificazione dei modelli in base alla pertinenza, l'integrazione di adattatori per una ricerca semantica avanzata e l'esplorazione dell'integrazione multimodale delle informazioni, gli sviluppatori possono perfezionare ed espandere ulteriormente le loro applicazioni di IA generativa.
Il supporto di Amazon Bedrock per RAG serverless apre nuove strade per l'innovazione nel campo dell'IA generativa. Abbattendo le barriere all'accesso e offrendo una piattaforma scalabile e conveniente, AWS consente agli sviluppatori di esplorare il pieno potenziale delle applicazioni basate sull'intelligenza artificiale. Mentre continuiamo a scoprire ed espandere le funzionalità del RAG serverless, le possibilità di creare soluzioni di intelligenza artificiale più sofisticate, reattive e funzionali sono illimitate. Unisciti a noi in questo viaggio e scopri come RAG serverless su Amazon Bedrock può trasformare in realtà i tuoi progetti di intelligenza artificiale.
Risorse

Giuseppe Battista
Giuseppe Battista è Senior Solutions Architect presso Amazon Web Services. Dirige l'architettura delle soluzioni per le startup in fase iniziale nel Regno Unito e in Irlanda. Conduce il Twitch Show "Let's Build a Startup" su twitch.tv/aws ed è a capo dell'acceleratore Unicorn's Den.

Kevin Shaffer-Morrison
Kevin Shaffer-Morrison è Senior Solutions Architect presso Amazon Web Services. Ha aiutato centinaia di startup a decollare rapidamente e a passare al cloud. Kevin si concentra sull'aiutare i fondatori nella fase iniziale con esempi di codice e streaming in diretta su Twitch.
Com'era questo contenuto?