Migration & Modernization
Agentic AI Meets PL/I: Modernizing Mainframes with AWS Transform
Introduction
Many enterprises worldwide depend on PL/I mainframe applications to run critical operations like banking, insurance claims, and government services. PL/I accounts for roughly 5% of all applications, (Leverage Compilation Technology to Optimize Investment on System z) primarily in financial services, insurance, and public sector, proving remarkably resilient over decades. However, organizations face growing challenges including a shrinking pool of PL/I expertise, rising operational costs, and the need for greater agility to respond quickly to changing market conditions.
PL/I language support in AWS Transform for mainframe helps customers accelerate their mainframe modernization journey. This new capability provides AI-assisted code transformation that helps reduce operational risk, preserves business logic, and enables cloud-native architecture. This technical blog post describes the reimagine pattern that can be applied to PL/I applications.
Background
The PL/I Modernization Challenge
Organizations modernizing PL/I-based mainframe systems typically encounter challenges in four key areas:
Talent Scarcity: The mainframe talent landscape presents a significant strategic consideration for organizations. With experienced PL/I developers approaching retirement age, and very few new computer science graduates familiar with mainframe languages, the knowledge gap threatens operational continuity.
Manual Conversion Complexity: Traditional rewrite approaches prove time-consuming, expensive, and error prone. Manual conversion to Java typically requires 24–30 months for large applications, with costs often exceeding $15 million and significant business disruption risks. Complex business logic buried deep within PL/I code, often lacking clear documentation, makes the modernization process inherently challenging to implement effectively.
Business Risk Management: Mission-critical applications processing millions of transactions daily cannot afford extended downtime or functional regressions. A single day of system unavailability can affect tens of thousands of users, delay critical processing, and cost organizations millions in lost revenue and regulatory penalties.
Technical Debt: Decades of accumulated code changes, patches, and undocumented business rules make it difficult to comprehend application logic before modernization. In many cases, over 40% of business rules are embedded solely in code with no supporting documentation, creating significant barriers to successful transformation.
PL/I Language at a Glance
PL/I is a versatile, general-purpose procedural language commonly used in IBM mainframe environments. Designed as a hybrid combining features of COBOL and FORTRAN, PL/I offers advanced capabilities including pointers, dynamic storage allocation, and sophisticated data structures. This versatility made PL/I ideal for complex business applications requiring both computational power and data processing, explaining its continued prevalence in finance, insurance, and government. However, its pointer arithmetic and dynamic storage allocation capabilities make automated translation more complex than for COBOL.
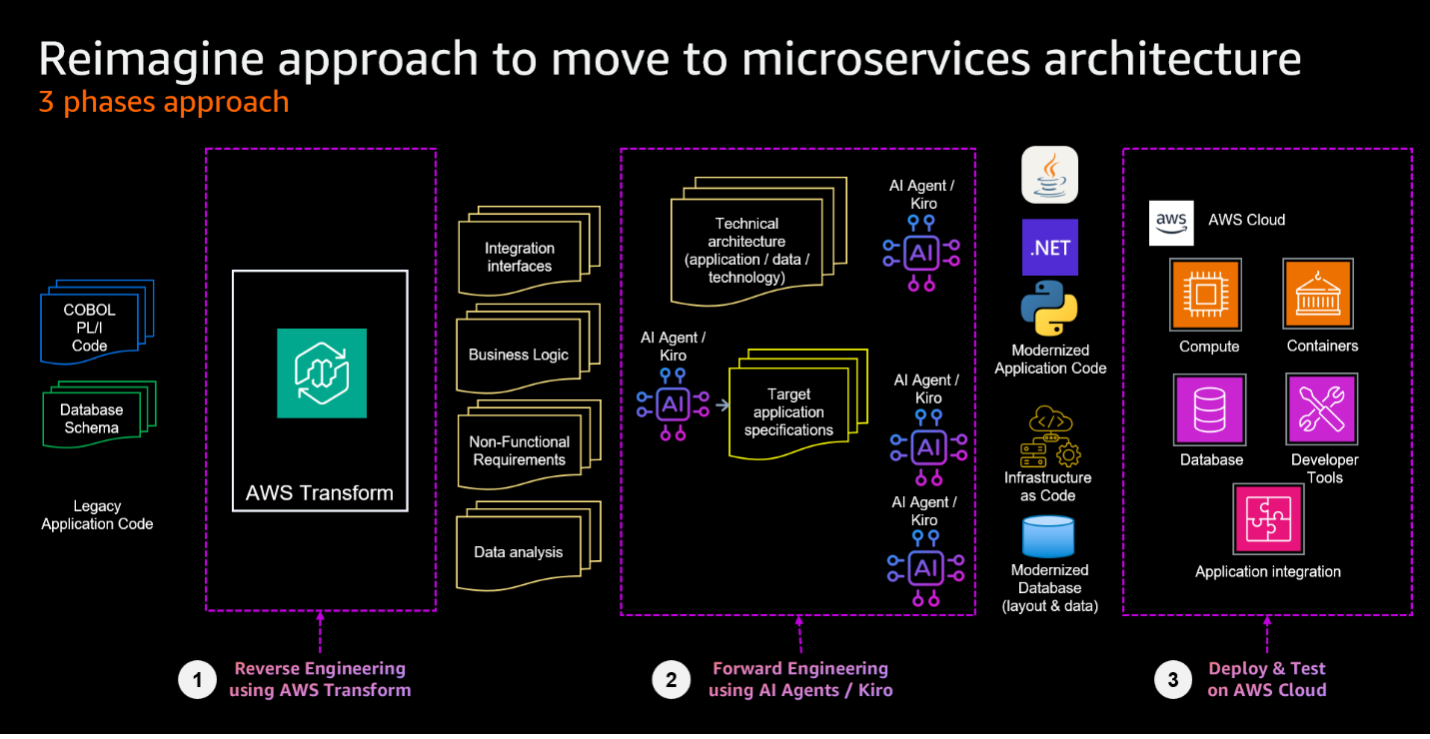
Applying the Reimagine Pattern to PL/I
The reimagine pattern transforms existing mainframe applications into cloud-native microservices through a three-phase methodology. This approach is detailed in our companion post, Reimagine your mainframe applications with Agentic AI and AWS Transform, with this section focusing on PL/I-specific implementation:
- Reverse Engineering to extract business logic and rules from existing PL/I code using AWS Transform for mainframe.
- Forward Engineering to generate both service specifications and source code using AI Agents / Kiro.
- Deploy and test to deploy the generated artifacts to AWS using Infrastructure as Code and to test the functionality of the modernized application.
Reverse Engineering with AWS Transform: Understanding the current System
Reverse Engineering with AWS Transform: Understanding the current System
AWS Transform’s PL/I support enables automated analysis of mainframe codebases at scale. When AWS Transform is applied to an application, it produces:
- Business rule extraction — identifying validation logic, processing conditions, and data routing rules embedded in the source code
- Dependency mapping — tracing all programs, copybook, and file dependencies across the application
- Documentation generation — producing structured, human-readable descriptions of Inputs and outputs, record layouts, and processing flows
The output is a structured artifact describing what the system does, independent of PL/I syntax, serving as the primary input for the implementation phase.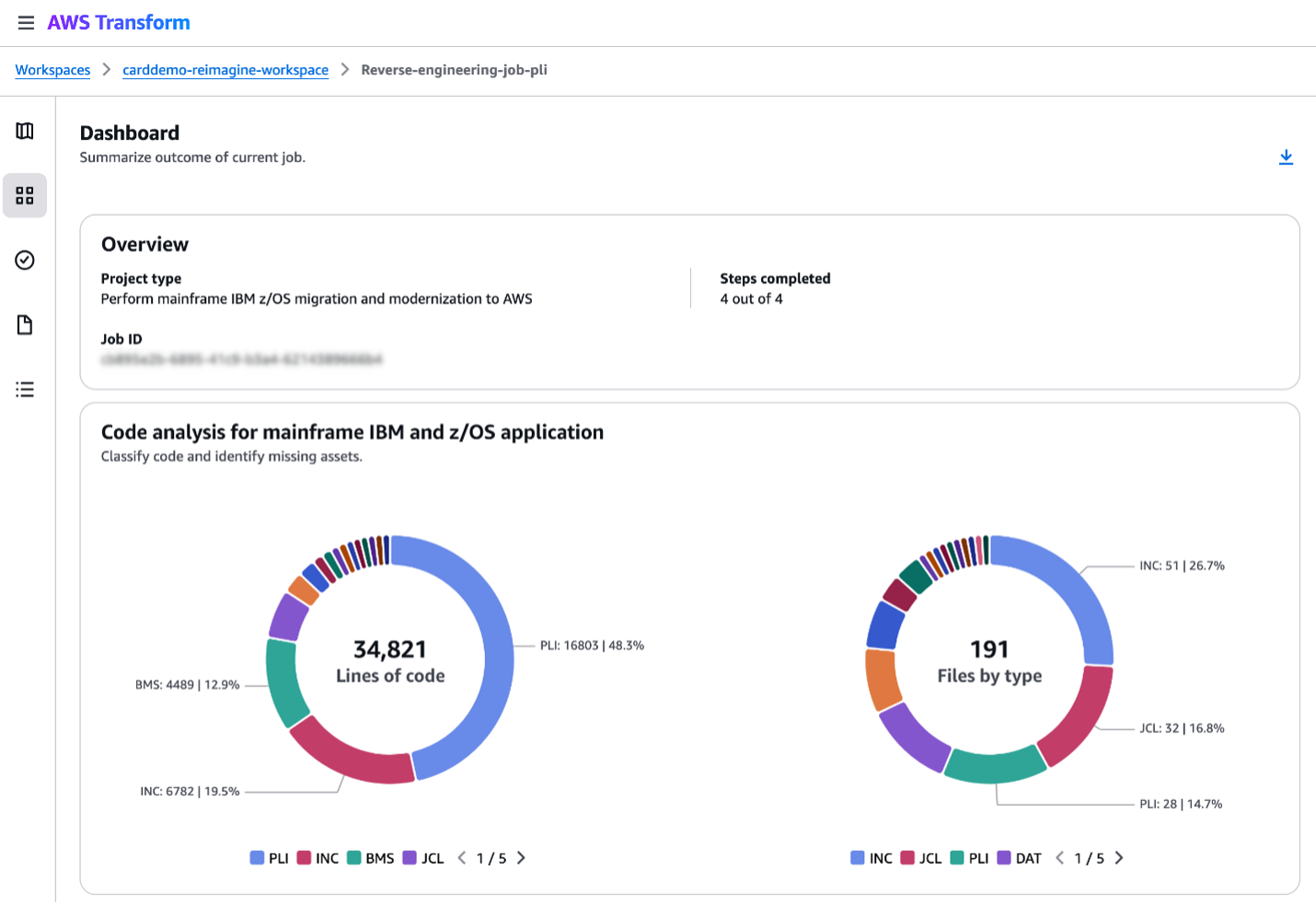
Forward Engineering with Kiro: Implementing in a Modern Architecture
The output is a structured, syntax-independent artifact that captures what the system does, serving as the primary input for the implementation phase. By defining natural language specifications that describe the desired behavior and target architecture, teams create solutions tailored to the new language from the ground up. Kiro then autonomously generates code, infrastructure templates, and deployment scripts aligned with those specifications.
Development teams create project-specific steering documents that give Kiro a persistent understanding of the target technology stack, architecture patterns, naming conventions, and migration philosophy. Kiro applies consistent architectural decisions across the entire project, whether generating a Python parser, C# validation service, AWS CloudFormation template, or Amazon Redshift SQL query.
Kiro structures the implementation across three phases:
- Requirements definition — translating the AWS Transform output into formal, traceable specifications for each target microservice or component
- Design — generating architectural blueprints, data models, and interface contracts aligned with the target AWS architecture
- Implementation — autonomously generating code and infrastructure, with developers reviewing outputs and validating them against the defined specifications
This workflow is designed to provide full traceability of business logic from AWS Transform through to final implementation, critical for mission-critical workloads demanding verified functional correctness. Throughout all three phases, human validation remains essential.
Transforming credit card transaction lifecycle from CardDemo
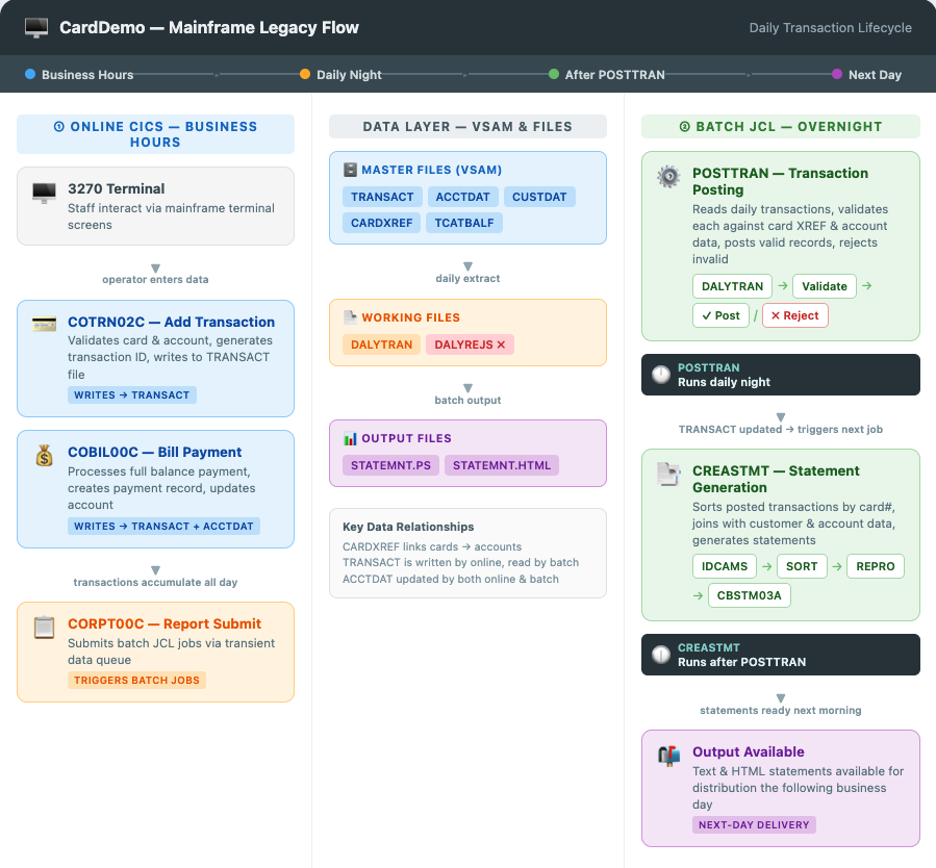
This blog post uses AWS CardDemo, which simulates a credit card management system encompassing account management, transaction processing, and statement generation, for this modernization effort. To demonstrate the reimagine pattern, we selected a complete business flow spanning both online and batch processing: the daily transaction lifecycle. The details of the targeted components are described in the following section.
Online: Transaction origination
During business hours, two CICS online programs feed the batch pipeline. COTRN02C provides an interactive 3270 screen for entering credit card transactions, validating each against card cross-reference and account master files before writing to the TRANSACT VSAM file. COBIL00C enables bill payments, creating payment transaction records and updating account balances. Both programs write to the same TRANSACT VSAM file, accumulating the daily volume for overnight processing.
Batch: End-of-day processing
Two batch jobs process the accumulated transactions:
POSTTRAN runs nightly and reads the daily transaction file. It validates each record against card cross-reference and account data — checking card validity, credit limits, and expiration dates. Valid transactions are posted to master files with updated category balances, while invalid transactions are routed to a reject file. This represents a classic mainframe pattern: sequential file processing with conditional routing.
CREASTMT runs nightly after POSTTRAN and follows four sequential steps. It initializes a temporary VSAM cluster, sorts transactions by card number, loads the sorted data, and generates account statements in text and HTML by joining transactions with additional data.
This illustrates a multi-step batch pipeline with intermediate staging, a common pattern in mainframe reporting workloads.
The following diagram illustrates the flow across online, data, and batch layers:
CardDemo: Transaction Flow
Phase 1: Reverse Engineering — Business Logic Extraction with AWS Transform
Before any modern code can be written, the existing PL/I codebase must be fully understood. AWS Transform performed the following analysis across the batch chain:
- Business rule extraction — Identifying the validation logic embedded in the PL/I source: credit limit checks, account expiration validation, card cross-reference lookups, and the conditional routing that determines whether a transaction is posted or rejected.
- Dependency mapping — tracing all files, copybooks, and program dependencies. For POSTTRAN, this revealed dependencies on five VSAM files and the reject output. For CREASTMT, it mapped the four-step pipeline and cross-file dependencies on transaction, cross-reference, account, and customer data.
- Record layout documentation — capturing the fixed-length record formats (350-byte transactions, 300-byte accounts, 430-byte rejects with embedded error codes) is critical for accurate data migration to cloud-native storage.
The output captured the “what” of the system — structured descriptions of business behavior, data structures, and processing logic, independent of PL/I syntax, serving as the primary input to the forward engineering phase.
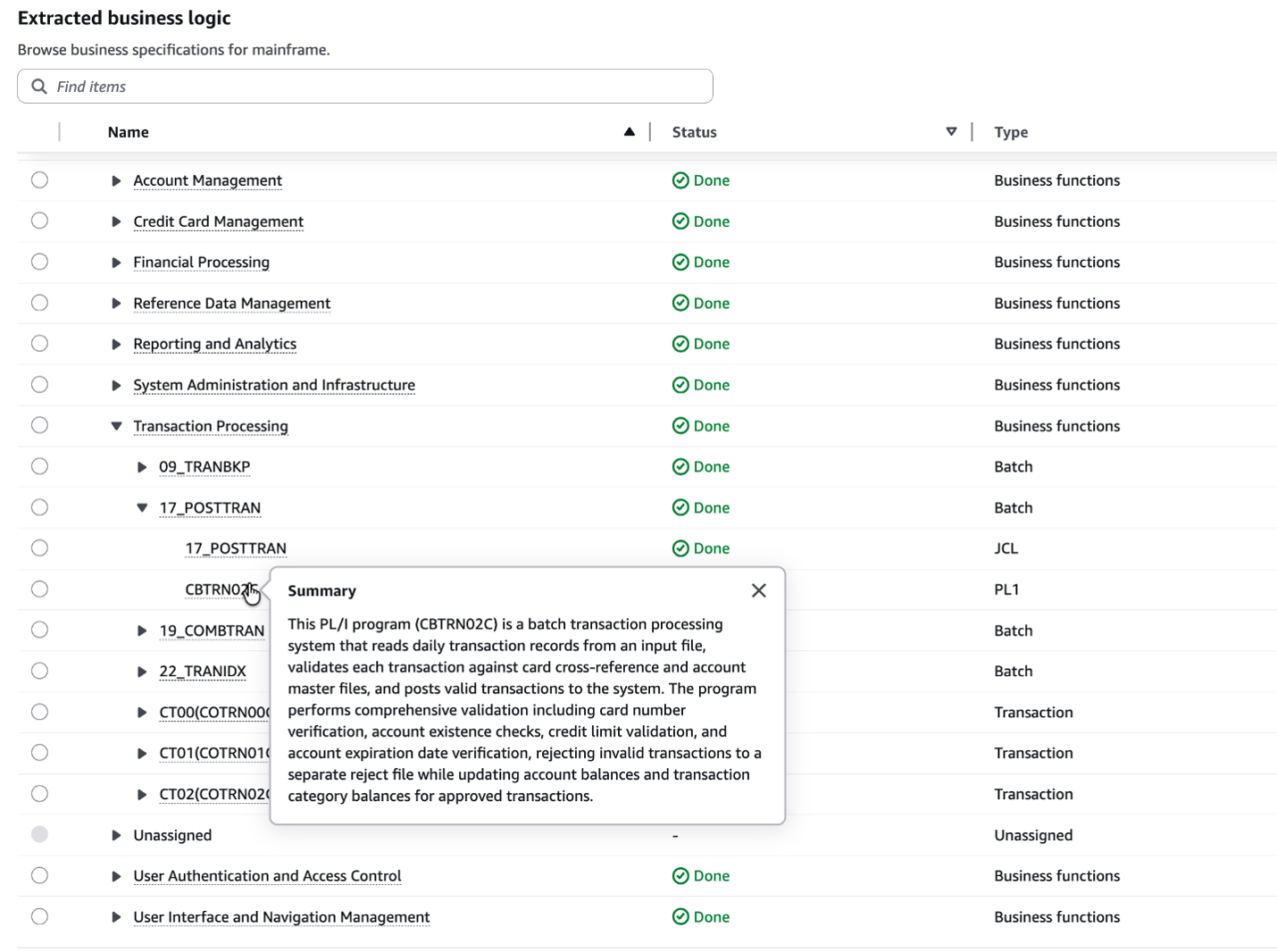
AWS Transform: Extracted PL/I business logic
Phase 2: Forward Engineering — From Business Rules into Service Specifications
While AWS Transform extracts granular business rules across the PL/I codebase, potentially spanning hundreds of programs, copybooks, and file definitions, Kiro synthesizes these into cohesive domain models. This forward engineering step consolidates scattered logic into unified service specifications that capture essential business capabilities, independent of both the PL/I implementation and any target architecture.
Requirements — Each extracted business rule became a traceable requirement. COTRN02C’s validation chain (card lookup → account verification → credit limit check → expiration check) mapped to explicit requirements for a Transaction Validation Service, each traceable to the original PL/I documentation.
Design — Kiro produced service boundaries, API contracts, and data models that reimagine the existing processing patterns:
- POSTTRAN batch → event-driven processing: The sequential file-based validation was decomposed into an event consumer that validates individual transactions as they arrive via streaming, replacing the overnight bulk processing model.
- CREASTMT batch → on-request reporting: The four-step sort-and-generate pipeline was transformed into a near real-time data synchronization flow. Processed transactions now feed an analytics store for dashboard-based reporting, replacing static file output.
- COTRN02C terminal → containerized API: The 3270 screen-driven transaction entry was redesigned as a REST API backed by a modern web interface, enabling 24/7 access beyond mainframe business hours.
Task breakdown — Each service was decomposed into implementation tasks, creating a structured backlog for developer review and completion.
Phase 3: Forward Engineering — Applying Cloud-Native Architecture Patterns
With the consolidated service specifications from Phase 2 as foundation, Kiro now defines how the modernized system will operate in a cloud-native architecture.
Using Kiro’s Vibe Mode in a spec-driven approach, the service specifications are extended and refined to incorporate the following key architectural principles. This transformation moves away from mainframe batch processing toward an event-driven, service-based architecture built on AWS services.
Key Architectural Transformations:
- Cloud-Native Data Storage: Amazon RDS for PostgreSQL replacing the original VSAM file structures
- Event-Driven Data Ingestion: file processing is transformed into DMS change data capture
- Real-Time Dashboards via Amazon Quick Suite
- Containerized service Architecture: Transformed PL/I transaction processing into containerized .Net microservices on Amazon Elastic Container Service Fargate
Beyond the steering file, which defines the basic architecture to be used, targeted prompts guide Kiro to apply specific patterns for each component. For example, when transforming the reporting subsystem, the prompt used emphasizes the shift from batch file generation to real-time analytics.
After applying these architectural patterns through refinement, Kiro generates the updated specifications ready for code generation in Phase 4.
Phase 4: Forward Engineering – Code Generation and Infrastructure Implementation
Following specification validation, Kiro transitions into the implementation phase where it generates code and infrastructure as code in a project-driven mode. Kiro can autonomously complete implementation tasks while developers focus on reviewing generated code, providing feedback, and validating the implementation against requirements. Critical to this process are steering files, which provide Kiro with persistent project knowledge including conventions, libraries, standards, and infrastructure choices, maintaining consistent architectural adherence.
The outcome of this process is visualized in this architectural diagram, and the main components are highlighted.
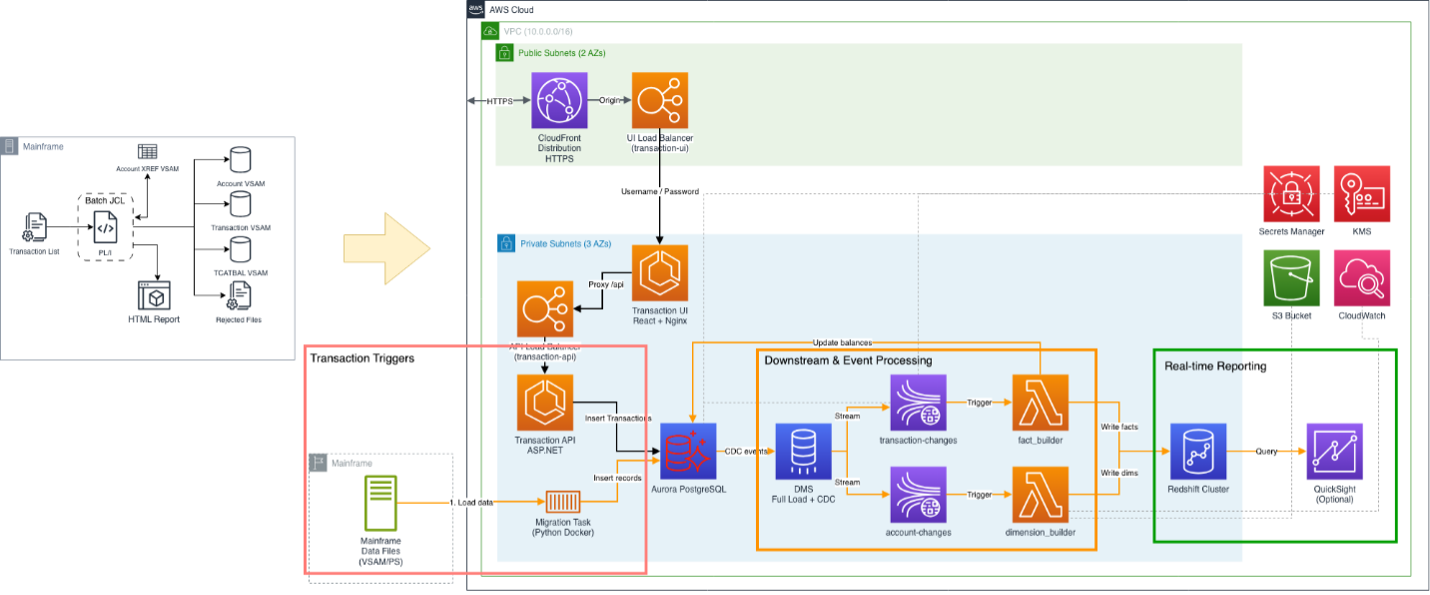
Architecture Diagram: PL/I Batch for transaction handling
Transaction Triggers:
- File-Based/Migration related: VSAM to Cloud-Native Storage: The VSAM files used by POSTTRAN and CREASTMT are migrated to cloud-native storage.
- Event Based: Transaction UI (Interactive Data Entry): This channel enables real-time, operator-driven transaction entry and account management.
Downstream and Event-Driven Processing:
- From Aurora, the data enters the same downstream pipeline as file-imported data: DMS captures the change events, publishes them to Amazon Kinesis Data Streams, AWS Lambda functions process the events, and the results are written to Amazon Redshift for reporting and analytics.
- Change events are published to Amazon Kinesis Data Streams, providing a durable, high-throughput event channel.
- AWS Lambda functions consume events from Kinesis and perform corresponding data operations, including Load, Insert, Update, and Delete, against Amazon Redshift in near real-time.
- The Fact Lambda function additionally manages statement updates in the PostgreSQL Account table, reflecting post-transaction processing logic from the original POSTTRAN job.
Real-Time Reporting:
- The statement generation output of CREASTMT, previously produced as static text and HTML files, is now served through Amazon Quick Suite connected to the Amazon Redshift data warehouse.
This architecture reduces the traditional overnight lag between transaction processing and reporting, enabling timely analysis, and faster business decisions.
Phase 5: Deploy and test the final Solution — AWS Direct Access and Vibe Mode
Generating an initial version of the code through spec-driven development was only the beginning. Two complementary capabilities within Kiro were essential to reaching a fully deployed, running application.
Direct AWS Service Access
Kiro can run shell commands and interact directly with AWS services via the AWS CLI, removing the manual copy-paste cycle between a terminal and the AI. During this project, Kiro autonomously:
- Queried Amazon Redshift via aws redshift-data execute-statement to inspect table schemas, row counts, and data values.
- Using Amazon CloudWatch for monitoring, Kiro tailed CloudWatch Logs to diagnose Lambda and Amazon ECS task failures.
- Described ECS task definitions to verify environment variable configuration.
- Listed VPC connections and DMS tasks to confirm the infrastructure state.
- Inspected AWS IAM role policies to identify missing permissions.
This direct access enabled end-to-end diagnosis within a single conversational turn — read the error log, query the database, check the IAM policy, fix the code.
Vibe Mode (Autopilot)
Kiro’s vibe mode enabled a fully conversational development workflow where the team described problems in natural language and Kiro resolved them autonomously across multiple files and services. Two representative examples illustrate the depth of this capability:
Data model bug:
“Can you check why the Amazon Redshift query returns no results for the Transaction inserted from Lambda after the DMS Task processing?”
Kiro ran SQL against Amazon Redshift via the Data API, discovered that fact_transaction.account_key contained natural keys while dim_account.account_key contained surrogate keys, identified the bug in the fact_builder Lambda, and corrected the key lookup logic.
IAM permission issue:
“The ECS service returns 500 on POST /api/v1/transactions”
Kiro tailed the Amazon CloudWatch Logs, identified a KMSAccessDeniedException when publishing to Kinesis, traced it to a missing IAM permission in the CloudFormation template, added kms:GenerateDataKey and kms:Decrypt to the ECS task role, and identified that the correct architectural fix was to stop the ECS service from publishing to Kinesis directly — since DMS handles that responsibility.
Each interaction involved Kiro reading files, running AWS CLI commands, analyzing error output, modifying code across multiple files, and explaining the root cause, all within a single conversational turn.
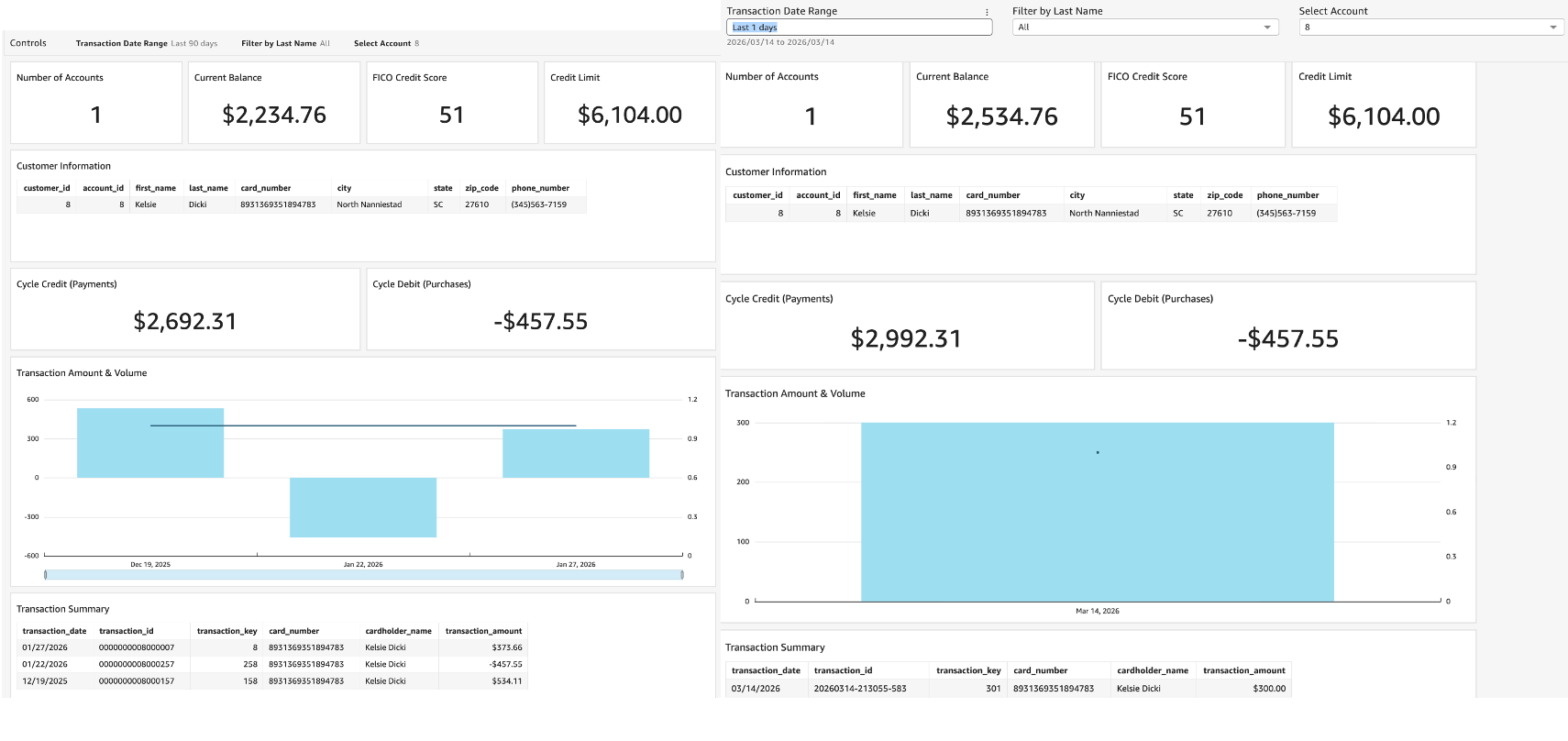
The screenshots capture the complete modernized system. The containerized Transaction UI on the left enables real-time transaction entry through a modern web interface, while the Amazon Quick Suite dashboard on the right displays near real-time analytics and reporting.

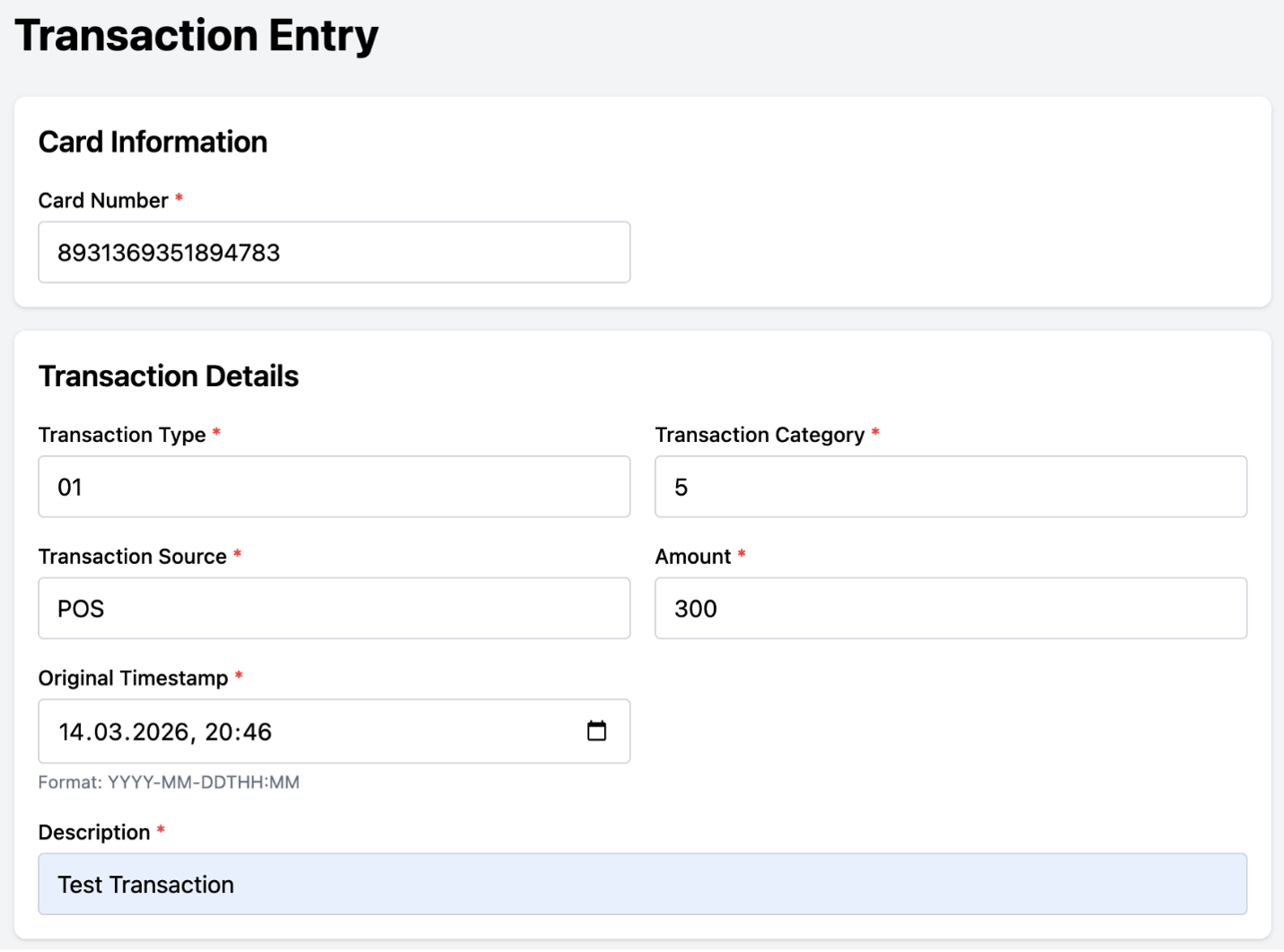
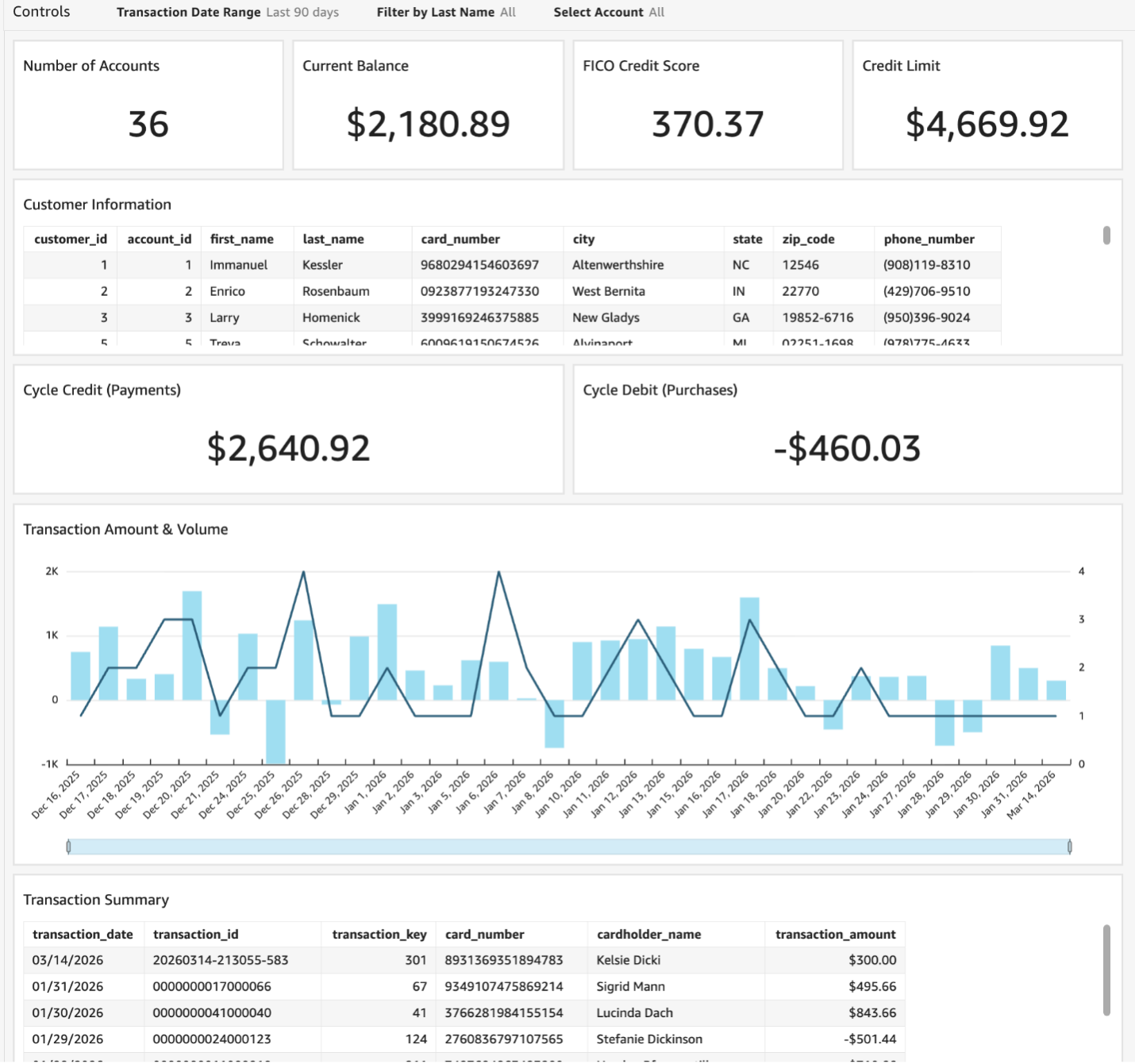
The near real-time nature of the pipeline is illustrated in the dashboard. A transaction entered via the UI is reflected in the account balance within seconds, as shown by the balance update from $2,234.76 to $2,534.76.
Conclusion
The combination of AWS Transform and Kiro provides a structured approach to PL/I modernization. AWS Transform extracts business rules, record layouts, and processing logic from PL/I source code, creating structured documentation of system behavior. Kiro uses this documentation to generate application specifications, application code, and infrastructure configurations across multiple AWS services while maintaining consistency through iterative refinement.
This workflow helps reduce the time and manual effort traditionally required for mainframe modernization projects. The transaction part of CardDemo application migration, completed in approximately 12 hours, illustrates the approach’s viability for transforming batch-oriented PL/I applications into event-driven cloud architectures. Organizations with significant PL/I codebases can use these tools to migrate mission-critical applications to AWS while preserving existing business logic and reducing project risk.
Additional AWS Transform for mainframe and Kiro resources: