亚马逊AWS官方博客
分布式神经网络框架 CaffeOnSpark在AWS上的部署过程
一、介绍
Caffe 是一个高效的神经网络计算框架,可以充分利用系统的GPU资源进行并行计算,是一个强大的工具,在图像识别、语音识别、行为分类等不同领域都得到了广泛应用。有关Caffe的更多内容请参考项目主页:
http://caffe.berkeleyvision.org/
不过Caffe的常用部署方式是单机的,这就意味着它的水平扩展能力受到了限制。使用者可以通过在系统中添加多个GPU的方式提高并发度,不过其并发能力最终受到单系统可支撑的GPU数量的限制。同时,神经网络计算往往又是计算消耗很大的,所以人们在使用Caffe的时候都可能会希望有一种并行计算框架可以支持Caffe。
而我们知道Spark是基于内存的计算框架,基于Yarn, Mesos或者是Standalone模式,它可以充分利用多实例计算资源。因此,如果能够结合Caffe和Spark,Caffe的能力将得到更充分的发挥。 基于这些原因,Yahoo开源的CaffeOnSpark框架受到的极大的关注。
有关CaffeOnSpark的源代码和相关文档,请大家参考:
https://github.com/yahoo/CaffeOnSpark
今天我们要进一步讨论的是如何在AWS EC2上部署CaffeOnSpark, 充分利用AWS服务提供的GPU实例构建强大的分布式神经网络计算框架。
在CaffeOnSpark的文档中有明确指出EC2上部署CaffeOnSpark的步骤,具体请参考:
https://github.com/yahoo/CaffeOnSpark/wiki/GetStarted_EC2
但是文档的一些部分写得比较简单,初步接触的读者可能在执行过程中遇到一些问题,所以在这里将我个人的安装配置过程整理了一下供大家参考。
安装过程大概可以分为四部分:
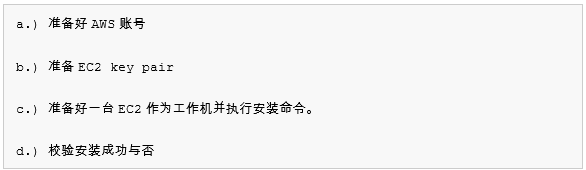
下面会在“环境准备”一节中具体描述这几个步骤的细节。
二、环境准备
首先我们打开文档https://github.com/yahoo/CaffeOnSpark/wiki/GetStarted_EC2, 看看文档中刚开始的部分对于环境准备的要求。
里面首先提到我们需要准备“EC2 Key pair”, 就是要准备EC2启动需要的密钥对。当然,为了创建“EC2 Key pair”,为了启动EC2,你首先需要一个AWS账号。有关AWS账号的申请和基本使用这里就不细述了,请参考其它相关文档。需要注意的是你拿到的AWS账号需要有基本的权限才能完成CaffeOnSpark的安装工作,其中包括创建EC2实例,创建安全组等。
“EC2 Key pair”是你在创建EC2实例时创建的密钥对,创建过程中你有一次机会下载私钥文件,就是文中提到的pem文件。如果你之前没有创建过EC2,你也可以直接在EC2控制台的“网络与安全->密钥对”界面中点击“创建密钥对”按钮进行创建。同样,创建过程中你有一次机会下载pem文件,下载后注意保管好该文件,后面都会依赖这个文件。
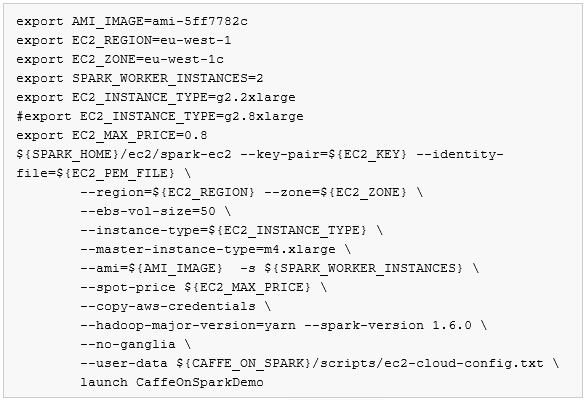
按文档的描述,有了以上的资源以后就可以执行以下命令:

为了准备环境,我们需要先理解一下上面的脚本。脚本的刚开始部分是一系列变量的定义,我们先了解这些变量的作用。
第一句比较简单,从变量名可以知道这是指定了要使用的AMI的ID:
![]()
这个镜像是一个已经安装好Spark、CaffeOnSpark,并加载了常用神经网络测试数据的Ubuntu镜像。该镜像由CaffeOnSpark团队提供,已经共享给所有AWS账号。
不过稍有AWS使用经验的同学会意识到,这样的命令是针对特定的区域(Region)的,因为同一个AMI镜像拷贝到不同AWS区域时它们的AMI ID是不一样的。在命令行中如果指定了一个AMI的ID,就意味着这些命令只能在特定的AWS区域正常工作。
所以我们需要继续查看后续命令,看看哪里指定了区域。幸运的是,命令的第二行就是指定区域的命令:
![]()
我们知道区域代码“eu-west-1”指的是欧洲(爱尔兰) 区域,意味着我们运行完这个样例后我们的CaffeOnSpark群集是运行在欧洲(爱尔兰) 区域的。因为EC2 key pair也是按区域分的,所以我们创建的EC2 key pair也应该是在欧洲(爱尔兰) 区域。
为了在欧洲(爱尔兰) 区域创建你的EC2 key pair,你可以点击AWS控制台右上角的区域选择框,选择欧洲(爱尔兰) 区域,然后再按步骤进入EC2的控制台创建EC2 key pair.
同时,你也可以去EC2控制台的“映像->AMI”界面查找镜像ID为ami-5ff7782c的镜像,记得查看时选择“映像类型”为“公有映像”,而不是“我拥有的”。找到这个镜像你还可以仔细查看一下其它相关信息。
如果你发现镜像列表中没有ID为ami-5ff7782c的镜像,有可能你阅读本文的时候相关方已经更新了新的镜像,你可以去CaffeOnSpark的主页
https://github.com/yahoo/CaffeOnSpark 找到更新版本的指导,获得新的镜像ID。
进一步往下看可以看到指定AZ的命令行:
![]()
其中eu-west-1c代表c可用区,有关可用区的相关概念在这里也不细述了,对可用区(AZ)概念有疑惑的同学请参考其它AWS基础文档。
再往下是指定worker数量的命令:
![]()
表示这个群集需要两个工作实例,需要注意的是创建的Spark群集中有一个主实例,多个工作实例,其中主实例会使用一般的实例类型,而工作实例会使用GPU实例。这里的参数就表示希望启动两个GPU实例作为工作实例。
我们知道,AWS上的GPU实例也有类型之分,现在可以使用的GPU类型有g2.2xlarge和g2.8xlarge两种,到底工作实例会使用什么GPU类型呢,下面的参数就是为了指定工作实例的实例类型。可以选择g2.2xlarge或者是g2.8xlarge。注意下面两行中第二行被注释掉了,表示只有第一句生效,就是使用g2.2xlarge实例类型。

接着是指定竞价实例的最高价格,有关竞价实例的细节请参考AWS相关文档,使用竞价实例大概就是设定一个可以接受的价格去参加实例拍卖的竞价,如果你的出价比别人高你就可以拍得实例。下面这句就是设置竞价为0.8美金每小时:
![]()
后面我们继续分析命令会知道,后续执行命令的时候会使用下面的参数,表示希望使用竞价实例作为工作实例。但是这不是CaffeOnSpark所必须的,如果你不希望使用竞价实例,可以不使用以下参数,这样就可以使用“按需实例(OnDemand)”了。
![]()
接着就是运行真正的命令了,运行的命令是:
![]()
后面带有许多参数,在具体了解不同参数的作用前,我们先得思考,这个spark-ec2命令从哪里来? 如果你之前曾经安装过Spark,在你的Spark主目录里就可以找到ec2目录,里面有spark-ec2命令。 我自己的环境中曾经安装过Spark 1.5,所以也可以找到这个ec2/spark-ec2命令,不过如果我尝试去执行这里的这些命令的话会报错,报“不可知的Spark版本”错误。原因是这里的脚本指定目标Spark是1.6.0, 但是我们运行的Spark是1.5,所以会报错。所以我重新启动了一个新的实例安装了Spark 1.6,以执行spark-ec2命令。有关Spark 1.6的安装,下面的章节会有介绍部分安装过程,现在我们先看看这里spark-ec2命令的不同参数有什么:
其中–key-pair和–identity-file是用来指定EC2 key pair的,就是EC2要使用的密钥,–key-pair用于指定密钥的名称,–identity-file用于指定密钥的pem文件的路径:

接着 –ebs-vol-size是用于指定EBS卷大小的,这里设置了50G,因为镜像大小的原因,你不能把–ebs-vol-size设置的太小,这里就是用样例中的50G吧:
![]()
接着是通过–instance-type指定工作实例的实例类型,这里是用了前面定义的变量,按前面我们变量的定义,下面的参数会是用g2.2xlarge作为工作实例的实例类型:
![]()
接着是通过–master-instance-type参数指定群集主实例的类型,因为主实例不参与神经网络计算,所以主实例可以不用选择GPU实例,这里是用了m4.xlarge:
![]()
然后是用–ami参数指定实例创建时是用的镜像ID:
![]()
-s参数用于指定工作实例的数量,这里引用了之前定义的参数![]() ,我们把它设置成2,就是会启动两个工作实例:
,我们把它设置成2,就是会启动两个工作实例:
![]()
–spot-price就是前面提到的是用竞价实例的参数,如果你不希望是用竞价实例,直接删除这个参数就好了:
![]()
–copy-aws-credentials用于指定是否拷贝AWS授权证书,这里不用细究它的作用:
![]()
–hadoop-major-version=yarn 和 –spark-version用于指定Hadoop的运行框架信息和Spark的版本:
![]()
–no-ganglia 表示不需要使用ganglia
![]()
–user-data用于指定实例启动时的需要完成的动作,这个参数非常重要,CaffeOnSpark安装过程中的很多设置都是因为设置了这个“User-Data”才完成的。这里设置的user-data指向CaffeOnSpark目录的scripts子目录中的![]() 。这就意味着我们在使用这个命令的时候应该已经拥有CaffeOnSpark的代码了,具体的获取方法在下一节中有详细描述:
。这就意味着我们在使用这个命令的时候应该已经拥有CaffeOnSpark的代码了,具体的获取方法在下一节中有详细描述:
![]()
最后就是真正“启动”的参数了,这里同时指定了群集的名称,本例为“CaffeOnSparkDemo”,注意,这个群集名称需要是区域内唯一的,如果你希望进行多次测试,又不希望受之前测试的干扰,每次启动时需要在这里设置不同的群集名称:
![]()
理解了整个命令,我们再次总结一下我们需要完成的工作:

我们假设你已经做好了a、b两步,下一节会详细讲解步骤c,紧接着第四节会讲解步骤d:测试校验过程
三、安装过程
下面开始详细讲解我的安装过程。
1. 准备工作机
这一步骤就是启动一个EC2,没有什么特别的需要强调。因为平时都习惯使用Amazon Linux,所以我创建工作机时选择了Amazon Linux镜像。另外就是启动这台EC2也需要一个EC2 key pair,这里可以使用上一节提到的准备好的EC2 key pair, 也可以使用其它EC2 key pair。就是说工作机的密钥和CaffeOnSpark群集的密钥没有关系的,你使用同一对密钥可以,使用不同密钥也可以。
2. 安装Spark 1.6
这一步是在工作机上安装Spark 1.6,如果已经有工作机部署好Spark 1.6的就可以跳过这步。当然,如果你很熟悉Spark的安装过程,也可以直接跳过这一小节。
启动EC2工作机后ssh登录到工作机,按习惯先运行了:![]() , 以更新组件。
, 以更新组件。
接着运行了:![]() 来安装git命令,后面获取Spark源代码和CaffeOnSpark源代码都用它呢。
来安装git命令,后面获取Spark源代码和CaffeOnSpark源代码都用它呢。
然后通过以下命令获得Spark 1.6的稳定版本:
![]()
为了编译Spark,你可以使用Maven或者是sbt,我通过以下命令安装了sbt:
![]()
在Spark源代码根目录运行:![]() , 让sbt开始下载需要的组件,运行完进入sbt界面的话先退出来。
, 让sbt开始下载需要的组件,运行完进入sbt界面的话先退出来。
接着运行以下命令编译Spark:
![]()
我编译的是yarn版本,其实在这里参数-Pyarn不是必须的,我只是后续要执行yarn相关的任务,所以选择了带yarn的版本。
另外,你也可以直接运行Spark源代码目录中的![]() 生成可部署的版本,完整命令如下:
生成可部署的版本,完整命令如下:
![]()
为了方便以后使用,我将编译好的Spark移动到以下目录:![]() , 接着,修改一下
, 接着,修改一下![]() 文件,增加Spark路径的设置:
文件,增加Spark路径的设置:

执行命令![]() 让配置项直接生效后,你就可以开始测试一下你的Spark了,比如可以直接运行spark-shell试试。
让配置项直接生效后,你就可以开始测试一下你的Spark了,比如可以直接运行spark-shell试试。
最后,为了确认spark-ec2命令也正常工作,可以去spark安装目录的ec2子目录下执行![]() 命令,不带任何参数,系统会返回spark-ec2命令的帮助文字,你也可以顺便了解以下spark-ec2命令的具体使用方法。
命令,不带任何参数,系统会返回spark-ec2命令的帮助文字,你也可以顺便了解以下spark-ec2命令的具体使用方法。
3. 下载CaffeOnSpark源码
如上所述,在安装CaffeOnSpark过程中,其中一个关键点就是在群集实例创建时传入了特定的User-Data,这份User-Data就是来自CaffeOnSpark项目的“scripts/ec2-cloud-config.txt”文件。 为了获得这份“scripts/ec2-cloud-config.txt”文件,我们需要下载CaffeOnSpark源码包,当然你也可以单独下载这个文件,不过为了以后的代码学习,建议整个将CaffeOnSpark项目clone下来。 具体命令如下:
![]()
下载了CaffeOnSpark源代码后,修改一下~/.bash_profile文件,设置![]() 变量指向CaffeOnSpark的源文件目录,方便后续引用。
变量指向CaffeOnSpark的源文件目录,方便后续引用。
4. 运行安装命令
后面就可以开始运行安装命令了,其实这里还有几个参数需要设置,不过为了加深印象,我们可以直接运行命令,遇到错误提示时再修改相关参数。
为了运行安装命令,我们创建一个shell文件,比如叫install.sh,里面的内容就是从CaffeOnSpark项目的EC2安装指导中拷贝的。 为了方便大家,再次贴上该文档的链接:
https://github.com/yahoo/CaffeOnSpark/wiki/GetStarted_EC2
然后再重复把安装命令都贴上来:
给install.sh赋予正确的权限后开始运行它:![]() ,然后你会看到下面这样的错误:
,然后你会看到下面这样的错误:
![]()
错误的意思是没有设置 ![]() ,相当于没有设置访问AWS的用户名,该命令无法访问AWS。 所以你需要找到你”Access key”和”secret key”。如果你有足够权限,你可以从AWS控制台上为自己创建“Credential”,然后下载”Access key”和”secret key”。或者你的AWS管理员应该给你分配过”Access key”和”secret key”。有关”Access key”和”secret key”就不在这里展开了,如果你对”Access key”和”secret key”的使用还有疑惑,请参考相关文档。
,相当于没有设置访问AWS的用户名,该命令无法访问AWS。 所以你需要找到你”Access key”和”secret key”。如果你有足够权限,你可以从AWS控制台上为自己创建“Credential”,然后下载”Access key”和”secret key”。或者你的AWS管理员应该给你分配过”Access key”和”secret key”。有关”Access key”和”secret key”就不在这里展开了,如果你对”Access key”和”secret key”的使用还有疑惑,请参考相关文档。
如果你通过export命令设置了 ![]() ,但是没有设置
,但是没有设置![]() ,运行
,运行![]() 命令时会报另一个错误:
命令时会报另一个错误:
![]()
相当于是只设置了用户名,没设置密码。
也就是说你需要将你的![]() 和
和![]() 设置到环境变量里,才能给CaffeOnSpark安装脚本足够的权限。这里再强调一下,你使用的
设置到环境变量里,才能给CaffeOnSpark安装脚本足够的权限。这里再强调一下,你使用的![]() 和
和![]() 对应的账号本身需要有足够的权限,比如创建EC2的权限,创建安全组的权限等。
对应的账号本身需要有足够的权限,比如创建EC2的权限,创建安全组的权限等。
设置完”Access key”和”secret key”后,再次运行![]() ,你可能会遇到如下错误:
,你可能会遇到如下错误:
![]()
因为样例命令中并没有设置![]() 变量和
变量和![]() 变量,相当于是没有设置密钥名和密钥pem文件路径。
变量,相当于是没有设置密钥名和密钥pem文件路径。
所以你需要定义 ![]() 变量和
变量和![]() 变量,一个指向你的密钥名,一个指向你的密钥pem文件路径。
变量,一个指向你的密钥名,一个指向你的密钥pem文件路径。
再次运行![]() 命令,应该就可以正常开始安装了,安装过程时间比较长,建议启动screen命令后再执行。
命令,应该就可以正常开始安装了,安装过程时间比较长,建议启动screen命令后再执行。
运行![]() 命令,其实后台调用的是spark-ec2命令,spark-ec2命令会给AWS发送指令,创建指定的实例并完成相关设置工作。
命令,其实后台调用的是spark-ec2命令,spark-ec2命令会给AWS发送指令,创建指定的实例并完成相关设置工作。
注意,安装过程中有一步会提示是否格式化硬盘之类的提示,需要手工确认后才能继续进行。
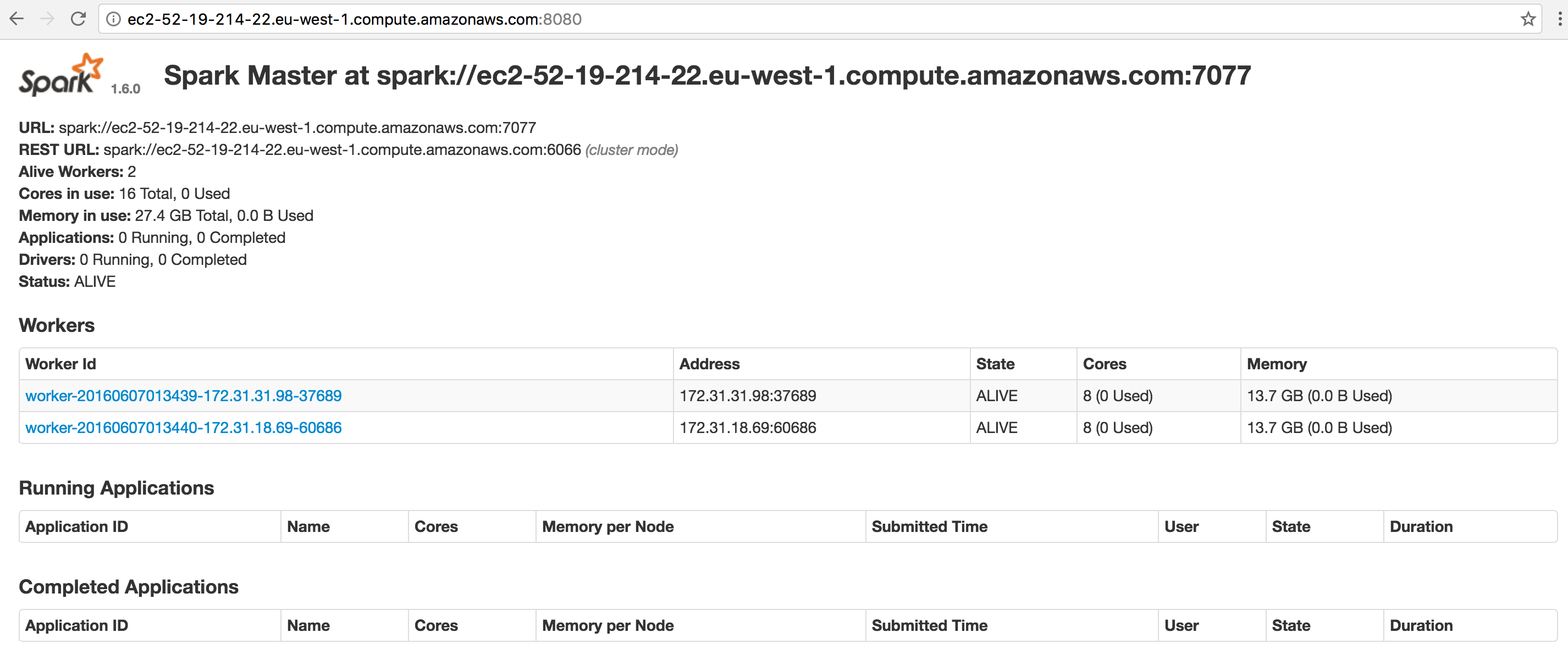
最后,如果一切正常,在一系列的日志输出后,你将看到类似下面这样的提示:

这表明CaffeOnSpark安装成功了,你可以启动一个浏览器,访问以上URL进行验证,打开页面后看到的应该是类似以下页面的Spark主页:
同时,你可以通过ssh连接到Spark的主节点上查看相关文件和日志,具体命令类似于:

要注意,用户名使用的是root
四、校验测试
安装好CaffeOnSpark后,你可以从安装日志里找到Spark群集的主节点DNS名称,接着就可以ssh进去测试了。
如我们平常测试Caffe一样,我们可以使用mnist数据集。CaffeOnSpark的镜像中包括了mnist数据集,在目录CaffeOnSpark主目录的data子目录下。
完整的测试脚本如下,其中关键几部分内容后面有详细解释:
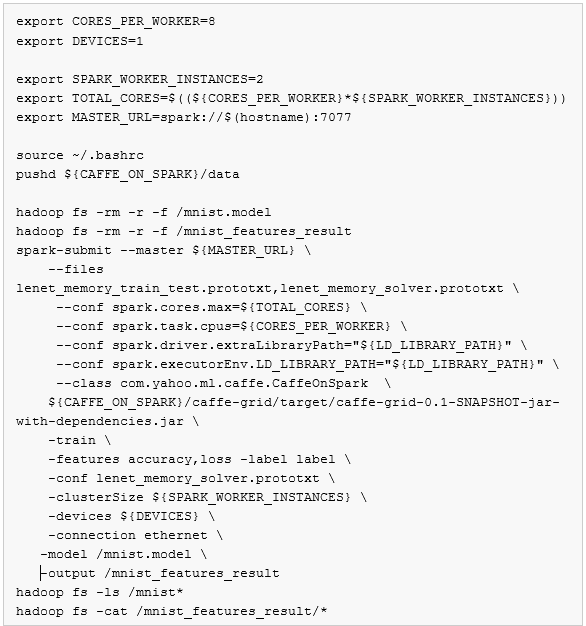
首先我们要留意的是下面这两句:

这两句是针对g2.2xlarge写的,有一个GPU设备,8核。
如果是使用g2.8xlarge的化,需要修改成:

就是有4块GPU,32核。
接着是清除HDFS上测试相关的目录:

然后就是关键部分,通过spark-submit命令向spark群集提交任务,运行的是打包好的Caffe网格计算包中的![]() 。
。
有关这里spark-submit命令中的细节就不详细说明了,有机会我们在分析CaffeOnSpark使用方法的文章中继续讨论。
最后,运行完spark-submit命令后,通过HDFS命令输出![]() 的结果。
的结果。
如果执行上面的完整脚本的话,你会在命令行会看到类似下面的输出:
恭喜,你已经顺利完成了CaffeOnSpark的安装测试,可以开始你的分布式深度神经网络之旅了。
五、其它
在安装结束后,你就可以开始使用分布式的神经网络框架了。不过,考虑到实际的情况,还是有几个地方可以再稍微展开一下的。
1. AMI镜像
文档中使用的镜像是在欧洲(爱尔兰)区域的,在CaffeOnSpark公开的文档中没有看到其它区域的镜像。所以,如果你希望在其它区域使用CaffeOnSpark,你需要把镜像拷贝到对应的区域,或者是在对应的区域创建CaffeOnSpark镜像。
如果是拷贝镜像,你没有权限直接拷贝镜像ami-5ff7782c。你需要使用镜像ami-5ff7782c创建一个实例,然后对该实例执行镜像操作,最后才把新创建的镜像拷贝到指定区域。
如果你希望在对应区域创建CaffeOnSpark镜像,可以参考官方文档里有关创建CaffeOnSpark镜像的指引文档:
https://github.com/yahoo/CaffeOnSpark/wiki/Create_AMI
按照这个指引,你可以从一个基础版本的Ubuntu开始,自己从头开始创建CaffeOnSpark镜像。
2. GPU实例情况
你在搭建自己的CaffeOnSpark框架的时候要提前考察目标区域的是否提供GPU实例。
3. 自动化安装过程
我们这次安装CaffeOnSpark使用了Spark里的spark-ec2命令,spark-ec2命令其实调用了spark-ec.py这个Python脚本,如果你打开脚本spark-ec.py,你可以看到整个spark-ec2命令创建Spark群集的过程。
也就是说,如果你在特殊场景下需要手动安装CaffeOnSpark,或者是在安装过程中有特定的动作要执行,你可以参考spark-ec.py的具体实现。
六、总结
工具最终是为目标服务的,当我们有合适的工具使用时,我们可以更好地思考如何实现目标。本文介绍了CaffeOnSpark的安装过程,希望这篇文章可以帮助你快速设置好CaffeOnSpark这个工具,从而可以更好地实现你的目标。
深度神经网络已经被证明是一个有效的机器学习方法,通过CaffeOnSpark和AWS服务,我们可以建构一个巨大的深度神经网络群集。这时候,海量数据的加载和运算都不再是问题,现在唯一的问题就是你要拿深度神经网络解决做什么。
一切都准备好了,出发吧,祝你好运!
作者:

邓明轩
亚马逊AWS解决方案架构师;拥有15年IT 领域的工作经验,先后在IBM,RIM,Apple 等企业担任工程师、架构师等职位;目前就职于AWS,担任解决方案架构师一职。喜欢编程,喜欢各种编程语言,尤其喜欢Lisp。喜欢新技术,喜欢各种技术 挑战,目前在集中精力学习分布式计算环境下的机器学习算法。