亚马逊AWS官方博客
在 Amazon EMR 中利用 Alluxio 的分层存储架构
许多组织已经在利用云计算服务的可扩展性和成本节约来对其本地数据中心扩展,以满足其业务发展过程中数据量不断增加的需求。AWS的EC2和S3等服务现在无处不在,被基础架构团队广泛的应用在各种规模的项目。 同时,数据分析工作负载也越来越多地迁移到云上。Amazon EMR 是一个托管集群平台,可简化在 AWS 上运行大数据框架(如 Apache Hadoop 和 Apache Spark)以处理和分析海量数据的操作。借助这些框架和相关的开源项目 (如 Apache Hive 和 Apache Pig)。您可以处理用于分析目的的数据和商业智能工作负载。此外,您可以使用 Amazon EMR 转换大量数据和将大量数据移入和移出其他 如S3 的AWS 数据存储。在本文中,我们将从架构设计的角度来分享由于HDFS和S3的不同特点带来的挑战,以及如何在EMR中利用Alluxio来实现基于对象存储的智能分层大数据存储架构。
1.EMR典型存储架构概览
集群 (Cluster)是 Amazon EMR 的核心概念。集群是EC2实例的集合。集群中的每个实例称作节点。集群中的每个节点都有一个角色,包括主节点、核心节点和任务节点。Amazon EMR 还在每个节点类型上安装不同的应用组件(例如Spark,Presto和Hive等计算服务以及HDFS本地分布式存储服务),在分布式应用中为每个节点赋予角色。
关于Amazon EMR的存储架构,大多数工作负载通常使用 HDFS 来缓存由任务流程步骤产生的中间结果,并使用 EMRFS 保存最终计算结果。
| 文件系统 | 特性及应用方式 |
| HDFS | HDFS 是适用于 Hadoop 的一种可扩展的分布式便携文件系统。HDFS 的一项优势是管理集群的 Hadoop 集群节点与管理单一步骤的 Hadoop 集群节点之间的数据感知。通过主节点和核心节点使用 HDFS。优势是快;劣势是它是短暂存储,会在集群终止时回收。它最适合用于缓存由中间任务流程步骤产生的结果。 |
| EMRFS | EMRFS 是 Hadoop 文件系统的一种实现方式,用于从 Amazon EMR 读取常规文件并将其直接写入到 Amazon S3。通过 EMRFS 可以方便地将持久性数据存储在 Amazon S3 中以便用于 Hadoop,同时它还提供诸如 Amazon S3 服务器端加密、先写后读一致性和列表一致性等功能。 |
1)使用 HDFS 作为 AWS EMR 数据存储
当计算框架使用HDFS作为 AWS EMR 数据存储时,数据将存储在每个计算实例中。虽然 HDFS 可用于缓存 MapReduce 和 Spark 等工作负载的中间结果,但当群集终止时,存储卷往往会被收回,所以需要在不同的 EMR 群集运行中保留数据,一个解决方案是从 HDFS 将数据复制到 S3(通常使用Hadoop 的 distCp 或 AWS 扩展 S3DistCp)。另外,虽然HDFS的工作负载 I/O 具有低延迟,但是在数据管道的每个关键阶段后将结果集复制到持久存储(如 S3)时,需要考虑到数据复制所需要的时间开销。

2)使用 EMRFS 在 AWS EMR 中存储数据
S3 已经成为各种工作负载中非常受欢迎的对象存储。它提供可扩展性、弹性、低廉的成本和简单的 API。EMR 文件系统 (EMRFS) 是 一种HDFS 的实现,所有 Amazon EMR 集群将其用于直接从 Amazon EMR 读取常规文件并将其写入 Amazon S3。EMRFS 使您能够方便地将持久性数据存储在 Amazon S3 中以便用于 Hadoop,同时它还提供了一致视图和数据加密等功能。通过一致视图可以为 Amazon S3 中对象的列表和先写后读 (对于新放置请求) 提供一致性检查。数据加密可让您对由 EMRFS 写入 Amazon S3 的对象进行加密,并且还允许 EMRFS 处理 Amazon S3 中的加密对象。
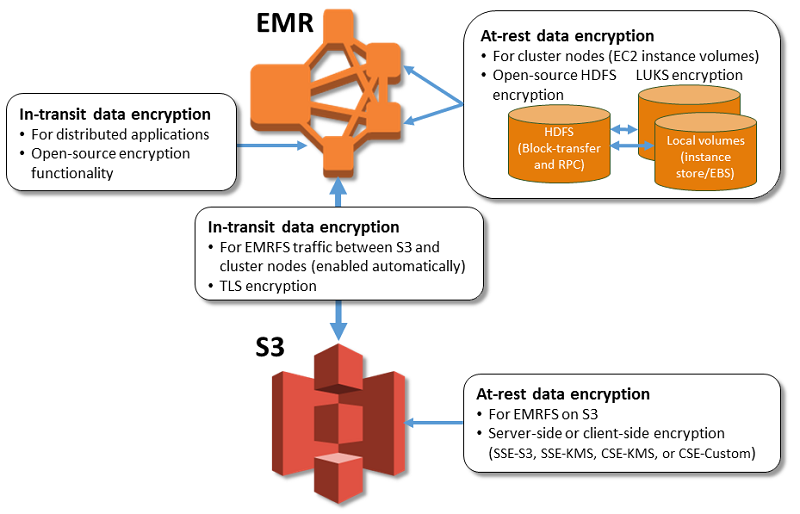
与直接在 HDFS 上存储数据相比, 由于数据不是本地缓存,所以需要读取的每个数据必须通过 EMRFS 从 S3 获取。另外,大多数 Hadoop 应用程序都依赖于强一致的存储系统。EMRFS 需要通过缓存 到AWS DynamoDB 中的对象元数据来部分解决强一致性问题。但元数据仍仅当对象在 Amazon EMR 作业过程中由 EMRFS 写入或对象使用 EMRFS CLI 同步或导入到 EMRFS 元数据时,元数据才会添加到 EMRFS。
2.在EMR上使用 Alluxio 实现分层数据存储
1)在 AWS EMR 中使用Alluxio的架构
针对上述讨论的存储架构各自优势,一个新的问题就是如何引入一个数据编排层,使用户既能够使用 S3 作为存储,又提高在EMR上运行的分析工作负载的性能和范围。Alluxio 通过使用内存、SSD 和/或磁盘提供分层缓存层,从而提高性能,从而解决了上述难题。Alluxio是一个开源的虚拟分布式文件系统,它最初起源于一个来自加州大学伯克利分校AMPLab实验室的叫做Tachyon的研究项目。Alluxio位于大数据栈中的计算和存储之间,为计算框架提供了数据抽象层,使得应用能够通过一个共同的接口连接底层不同的存储系统。它为运行于其之上的计算框架和之下的存储系统都提供 HDFS 和 S3 API 兼容性,并提供了跨多个存储系统的统一命名空间,实现了对计算和存储进行分离。

Alluxio 的实现包括一个缓存缓冲区,其中包括多层存储,例如用户通常会指定内存层(MEM)、固态硬盘层(SSD)和磁盘层(HDD )。启用分层存储后,会智能地考虑各层的顺序,根据 I/O 性能从上到下排序。这样的实现带来的主要优势之一是应用程序具有统一的命名空间。通过这个抽象,使得应用程序能够通过相同的命名空间和接口访问多个独立的存储系统,由Alluxio来处理与不同的底层存储系统的连通细节。例如,我们可以实现将来自不同帐户的多个 S3 存储桶装载到 Alluxio 中,并且可以通过 Spark、Presto 或 Hive 访问它们,而无需知道他们来自不同的帐户,甚至来自不同的区域。
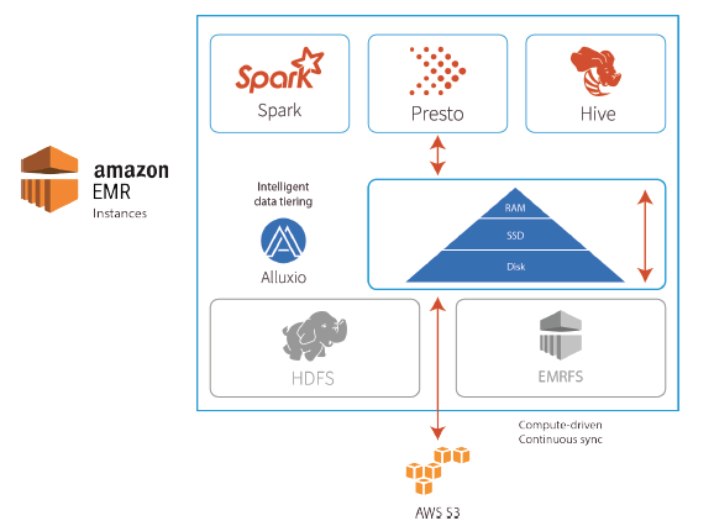
将S3配置为Alluxio下层存储的过程也非常简单,只要创建一个S3存储桶和文件夹,然后通过创建配置文件alluxio-site.properties,并在其中将S3配置为底层存储即可。虽然可以在配置文件中指定AK/SK赋予S3的访问权限,但作为最佳实践,我们建议通过IAM角色来实现权限管控。在《5分钟快速上手 – 通过EMR引导脚本部署Alluxio并运行Spark任务》的文章中,介绍了如何快速在AWS EMR上手Alluxio并运行Spark任务。通过上述的配置,Alluxio将作为一个新的数据访问层,配置在持久性存储系统S3和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间。Alluxio的架构包含master、worker和client三个部分。其中,lending master用于管理全局的元数据,包含文件系统元数据(文件系统节点树)、数据块元数据(数据块位置)、以及worker的容量元数据(空闲或已占用空间)。Alluxio clients用于通过Spark或MapReduce作业、Alluxio命令行或FUSE层等应用程序与lending master通信,实现读取或修改元数据。Alluxio的worker用于管理用户为Alluxio定义的本地资源(内存、SSD、HDD)。Alluxio的worker将数据存储为块,并通过在其本地资源上读或者创建新的数据块来响应client请求。Workers只用于管理数据块,文件到数据块的映射存储在master中,所以worker会定期的向lending master发送心跳信号。lending master会在一个分布式的持久化系统上记录所有的文件系统事务,这样能够实现容错,当lending master失效时,standby master会zookeeper被选为新的lending master。
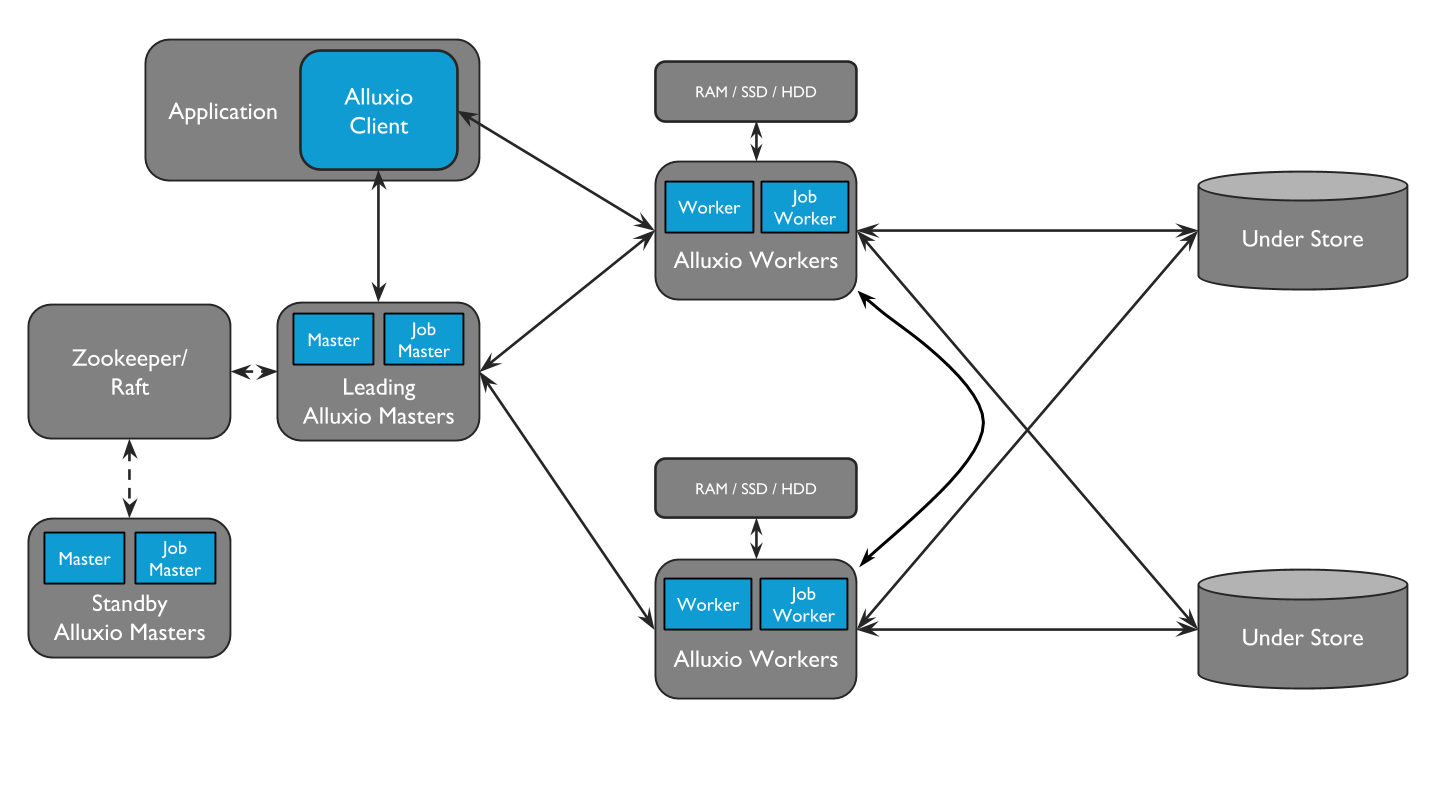
2)读场景下的数据流
举例说明,如果一个应用通过Alluxio client请求数据,client向Alluxio master请求数据所在的worker。
- 如果数据在本地可用,Alluxio client使用“短路”读取来绕过Alluxio worker,并直接通过本地文件系统读取文件。短路读取避免通过TCP套接字传输数据,并提供数据的直接访问。
- 当请求的数据存储在Alluxio中,而不是存储在client的本地worker上时,client将对具有数据的worker进行远程读取。client完成读取后,会要求本地的worker创建一个copy,这样下次读取的时候就可以在本地读取相同的数据。远程缓存命中提供了网络级别速度的数据读取。Alluxio优先从远程worker读取数据,因为Alluxio worker间的速度通常会快过从S3读取的速度。
- 如果数据在Alluxio中找不到,应用将从S3读取数据。Alluxio client会将数据读取请求委托给worker,这个worker会从S3读取数据并缓存。当client只读取块的一部分或不按照顺序读取块时,client将指示worker异步缓存整个块。异步缓存不会阻塞client。
3)写场景下的数据流
用户可以通过选择不同的写类型来配置应该如何写数据。写类型可以通过Alluxio API设置,也可以通过在客户机中配置属性Alluxio.user.file.writetype.default来设置。
- 当写类型设置为MUST_CACHE,Alluxio client将数据写入本地Alluxio worker,而不会写入到底层存储。如果“短路”写可用,Alluxio client直接写入到本地RAM的文件,绕过Alluxio worker,避免网络传输。由于数据没有持久存储在S3中,因此如果机器崩溃或需要释放数据以进行更新的写操作,数据可能会丢失。当可以容忍数据丢失时,MUST_CACHE设置对于写临时数据非常有用。
- 使用CACHE_THROUGH写类型,数据被同步地写到一个Alluxio worker和S3。Alluxio client将写操作委托给本地worker,而worker同时将对本地内存和S3进行写操作。由于S3的写入速度通常比本地存储慢,所以client的写入速度将与S3的速度相匹配。当需要数据持久化时,建议使用CACHE_THROUGH写类型。在本地还存了一份副本,以便可以直接从本地内存中读取数据。
- Alluxio还提供了一个叫做ASYNC_THROUGH的写类型。数据被同步地写入到一个Alluxio worker,并异步地写入到S3。ASYNC_THROUGH可以在持久化数据的同时以内存速度提供数据写入。
4) 典型的应用场景
很多企业已经在生产系统中开始在EMR中使用Alluxio,并且从中获得数据价值。下面,我们将介绍一些典型的应用场景。
- 对象存储的数据加速
如上文所述,越来越流行的架构是利用对象存储S3作为EMR中Spark,Presto,Hadoop或Tensorflow等机器学习/ AI工作负载等数据分析应用程序的重要数据源。对象存储可以是公共对象存储服务(AWS S3)或本地对象存储(例如Ceph或Swift)。在这样的场景中,将Alluxio部署在计算端(其中数据被配置为从S3持久存储)可以极大地提高应用程序的性能。Alluxio可以在临近EMR上不同的应用程序本地缓存数据,并管理其相应的元数据,以避免对象存储的特定低效元数据操作。
- 多集群的数据支持
出于性能,安全性或资源隔离之类的原因,很多企业使用专用于关键任务应用程序的资源来维护多个独立的EMR计算集群。这些EMR集群通常需要访问共同的数据集。这需要在作业执行期间远程读取数据,或者运行ETL管道以在作业执行之前预加载数据。在这样的场景中,Alluxio可以加快从主数据集读取远程数据的速度,而无需增加额外的ETL步骤。当部署在其中某个EMR群集中的计算节点上并配置为连接到主数据集时,Alluxio充当本地数据代理层,提供与主数据集相同的名称空间。Alluxio将透明地缓存群集本地的经常访问的数据,以减少网络流量。
- 通用数据访问层
在需要讲本地存储资源和云计算资源打通的混合应用场景下,用户可以将Alluxio部署为用于常见数据访问请求的存储抽象层。Alluxio支持各种存储类型的存储连接器,包括云计算资源(例如AWS)以及本地存储服务(例如HDFS或Ceph)。只要EMR应用程序与Alluxio集成,它们就可以访问不同的持久性存储系统,而无需更改应用程序。一旦连接到Alluxio,应用程序将自动与最流行的存储选项集成在一起,而无需实现任何连接器。

- 统一的多数据源访问入口
在客户用有多个不同的数据源需要被访问到的场景下,通过Alluxio提供的挂载API,使EMR应用程序能够通过同一文件系统名称空间访问跨多个数据源访问数据。应用程序不需要为每个数据源单独配置连接细节,例如客户端库版本或不同的安全模型。从应用程序的角度来看,它正在访问一个逻辑文件系统,该文件系统的数据可以由多个不同的持久存储来支持。这极大地简化了应用程序的开发、维护和管理。
3.结论及参考资料
综上所述,对于EMR中的应用程序和计算框架,Alluxio提供了快速存储,促进了作业之间的数据共享,而不管使用的是哪种计算框架。当EMR需要访问的数据位于本地时,可以以内存级的速度访问到数据;当数据位于Alluxio时,可以以计算集群网络的速度获得数据;所以只在第一次访问数据时,从S3上读取一次。从存储系统的角度看,Alluxio弥补了大数据应用与对象存储之间的差距,扩大了EMR可用的数据工作负载集。所以,后续我们也会持续跟进相关的性能评估等方面的内容,同时也会积极探索通过Marketplace等为AWS用户更为便捷的使用方式。如果您希望了解更多关于AWS EMR与Alluxio的资料,可以参考如下链接。