亚马逊AWS官方博客
规划具有 Hot-Warm 架构的 Amazon Elasticsearch Service 集群
前言
作为一款分布式搜索引擎,Elasticsearch近几年的热度持续增长,无论是在其擅长的全文检索领域,还是在数据库和大数据领域,Elasticsearch都有非常广泛的应用。借助倒排索引以及其分布式架构,Elasticsearch可以提供低延迟的响应和原生的横向缩放能力,使其可以应对海量数据的检索和分析。
而AWS作为云计算的领导者,不可或缺地提供托管的Elasticsearch服务 —- Amazon Elasticsearch Service(简称AES)。在技术上,兼容开源社区的Elasticsearch版本,此外还提供很多企业级的扩展功能,并且还在不断的创新。在今年的5月份,AWS正式上线了创新性的Ultrawarm节点,使得Amazon Elasticsearch Service支持业界流行的Hot-Warm存储架构,Ultrawarm与Amazon S3紧密的集成,让Amazon Elasticsearch Service的整体存储成本大大降低,为用户提供更好的性价比。
如果要将现有的负载迁移到Amazon Elasticsearch Service, 面临的第一个问题就是如何规划集群的资源。在本篇Blog中,我们将全面的阐述规划具有Hot-Warm架构的Amazon Elasticsearch Service集群的要点,以及规划的思路和方法。
Elasticsearch数据存储基础概念
由于Amazon Elasticsearch Service底层技术和开源的Elasticsearch保持一致,所以,首先我们需要了解Elasticsearch数据存储的基本概念。为了更好的理解,我们将Elasticsearch和传统的关系型数据库做了一个对比。
| RDBMS | Elasticsearch |
| 数据库(database) | 索引(index) |
| 表(table) | 类型(type) |
| 行(row) | 文档(document) |
| 列(column) | 字段(field) |
| 表结构(schema) | 映射(mapping) |
| 索引 | 反向索引 |
index可以理解为关系型数据库中的Database,是众多document的集合;而document对应着关系型数据库中的一行记录,由于是NoSQL数据库,所以每个文档可以存储不同的字段。Index和document都是逻辑上的数据存储概念,而数据最终会存储在一个或着多个物理的shard(分片)中。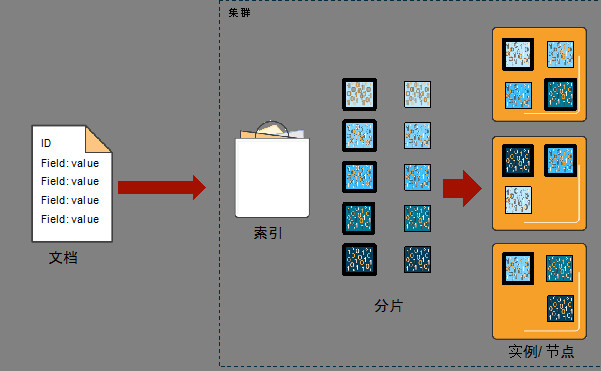
如上图所示,数据实际上是存放在1个或多个Shards中,shard用于数据的存储和索引,实际上一个shard就是对应一个Lucene进程,是最小的计算存储单元。Shard对于Amazon Elasticsearch Service集群资源的规划非常重要,我们应该尽量保证合理的shard总数和单个shard的尺寸,所以我们在需要了解以下几点:
- shard分为主shard和副本shard,主shard负责读写,副本shard为只读,也可以在主shard出问题进行failover。
- 我们在创建index的时候就规划好主shard数量,之后不再改变。如果一旦改变就会涉及到数据的重新allocate,开销非常大。
- 副本shard数可以随时修改,以增加并行读取能力。
- 集群中一个实例上的shard会共享数据节点上的计算资源,所以单个实例上的shard数量越少,理论上性能越高。所以我们应该合理的规划shard,尽量减少集群整体的shard数量。
Amazon Elasticsearch Service架构概览

Amazon Elasticsearch Service作为一个托管服务,和AWS的其他服务有很好的整合,从数据注入、安全管控到运维监控都有丰富的工具,在这里不再赘述。在这里主要介绍Amazon Elasticsearch Service集群中三个最重要的角色:
主节点:
主节点主要存储和维护集群的元数据,随着index和shard的数量的增加,对主节点的性能要求也会提高,在Amazon Elasticsearch Service集群配置中,我们可以选择独立部署的主节点(推荐),也可以选择将主节点和数据节点合并部署。主节点的主要作用如下:
- 跟踪群集中的所有节点
- 跟踪群集中的索引数量
- 跟踪属于每个索引的分片数量
- 维护群集中节点的路由信息
- 在状态更新后更新群集状态
- 在所有节点之间复制群集状态的更改
- 发送心跳信号来监控所有节点的运行状况
数据节点:
数据节点主要负责存储和管理热数据,同时数据的写入和读取请求会通过负载均衡器转发到任意的数据节点,数据节点会调协这些请求到数据真正存储的节点上,这些对于客户端来说是透明的。以下是数据节点的主要作用:
- 热数据存储
- 热数据shard物理存在的位置
- 存储和维护本地index和shard的元数据
- 处理通过ELB分配的客户端访问请求,可读可写
Ultrawarm节点:
UltraWarm 是一个性能优化的温存储层,底层使用AWS Nitro 系统提供支持的计算实例,采用S3作为存储层,大大降低了存储成本,此外在计算实例本地具有NVME SSD磁盘作为数据缓存,通过预取等技术,使得UltraWarm节点可以达到甚至超过传统HDD温数据节点的性能;此外在不降低性能的前提下,Ultrawarm节点可以降低90%的存储成本。以下是Ultrawarm节点的主要特性:
- 存储不常用的温数据
- 由于底层使用S3,不再需要副本shard,成倍的降低温数据存储容量
- Ultrawarm节点的数据为只读
规划Amazon Elasticsearch Service集群
首先我们假设一个使用场景 – 日志存储,在当下Elasticsearch最普遍的使用场景是日志分析,结合整个Elasticsearch的生态,比如ELK和EFK等,可以快速的构建一套完整的日志分析系统; 在AWS上,还提供更多的托管服务帮助客户构建一套Serverless(如Cloudwatch logs + Kinesis + Lambda + AES)的日志分析系统。在此,我们假设Amazon Elasticsearch Service集群要满足如下的日志存储需求。
| 单日日志数据量 | 热数据保留时间 | 日志保留时间 | 副本数量 |
| 1000G | 1天 | 7天 | 1 |
总体规划

规划Amazon Elasticsearch Service集群为如上图的架构,遵循最佳实践,主节点采用独立部署的方式,以保证主节点的可用性和性能;数据节点中的index存储当日(1天)写入的热数据,当index保留时间超过1天时,自动的迁移到Ultrawarm节点,Amazon Elasticsearch Service支持Index State Manageme功能,可以根据index的存储的时间和尺寸,设置策略自动的转移到Ultrawarm节点或者删除,此功能由Open Distro这个开源项目提供支持;Ultrawarm用于存储温数据,超过1天的index数据将会被转移到此类节点,然后继续存储6天,之后将会借助Index State Manageme功能自动删除。
规划步骤
在规划Amazon Elasticsearch Service集群时,我们需要考虑存储容量、计算资源以及shard数量和尺寸的规划,所以我们按照如下的顺序进行规划:
- 规划数据在Amazon Elasticsearch Service集群上的存储开销
- 规划热数据节点的主shard
- 规划热数据节点的存储空间
- 规划热数据节点的计算资源
- 规划Ultrawarm节点资源
实际单日数据存储需求
当日志数据注入到Elaticsearch后,会被转换为Elaticsearch自己的数据结构,此外还会额外增加一些元数据的存储,一般这些因素叠加到一起会额外带来20%的存储开销,因此我们需要计算出单日在Amazon Elasticsearch Service集群中真实的数据量,可以遵从这个计算公式:
单日数据量 = 单日日志数据量 * (1 + AES索引开销)
= 1000GB * (1+0.2)
= 1200GB
热数据节点主shard规划
就像我们之前提到的那样,每个shard实际上就是一个Lucene进程,因此数据节点上的shard越多,那么每个shard能分配到的节点计算资源就会越少,因此规划shard的主要目标是让shard数量尽量的少,但是也要保证shard的尺寸在一个合理的区间内,一般业界推荐的shard尺寸应该在50GB以下,根据Amazon Elasticsearch Service支持的计算实例的存储容量上限,在这里我们取5GB作为规划的标准。因为我们在热数据节点上存储一天的数据,所以热数据节点的主shard数可以遵从如下计算公式:
热数据节点主shard数 = 单日日志数据量 * 热数据保留时间 / 5GB
= 1200GB * 1天 / 5GB
= 240
热数据节点存储空间需求
在规划存储空间时,我们需要考虑热数据保留的时长,以及只读副本的数量,以及需要分别给Amazon Elasticsearch Service和Linux预留20%和5%的Buffer空间。
热数据节点存储空 = 单日数据量 * 热数据保留时间 * (1 + 副本数量) * / (1 – Linux 预留空间) / (1 – AES 开销)
= 1200GB * 1天 * (1+1) * (1-0.05)* (1-0.2)
= 3158GB
热数据节点的计算资源
内存规划
Elasticsearch是Java语言开发的,每一个shard就是一个Lucene进程,所以每个shard势必会占用JVM对内存,在其中存储一些元数据等。也就是说一台数据节点可以支持的shard数量是有限的,在业内有一些推荐规划原则:
- JVM堆内存可以支持25 shards/GB
- 单台数据节点的JVM堆内存不要超过32GB,参考此链接
- 此外,Amazon Elasticsearch Service会分配50%的内存给JVM,最大到32GB
所以我们可以按照如下的公式计算出热数据节点所需的总内存数:
热数据节点所需的总内存数 = 热数据节点主shard数 * (1 + 副本数量) / 25(shards/GB) / 对内存分配比例
= 240 * (1+1) / 25 / 0.5
= 38.4GB
CPU规划
CPU相对内存来说不太容易规划,总的原则是活跃分片数 < vCPU数量。由于活跃分片数不易统计,所以需要持续的观察CPU利用率等指标,因此建议在满足内存要求的前提下选择M系列的实例作为起步配置;另外如果是大量写入的场景可以考虑C系列;如果是大量分析和聚合的需求可以考虑R系列。在本例中我们选择均衡的m5.xlarge.elasticsearch机型。
机型数量规划
我们可以通过以下公式计算出需要多少台m5.xlarge.elasticsearch实例作为热数据节点:
热数据节点数 = 热数据节点所需的总内存数 / m5.xlarge.elasticsearch的内存数
= 38.4 / 16
= 3
Ultrawarm节点资源
由于Ultrawarm节点用于存储温数据,对性能要求比热数据节点低一些,建议对shard进行合并(Shrink操作)后再存储到Ultrawarm,推荐合并后每个shard的尺寸在25GB左右,在这样的推荐值下,可以保证单个Ultrawarm节点的shard数量在一个合理的范围内。由于Ultrawarm节点的是数据存储在S3上,因此存储容量的需求无需考虑副本数量,Elasticsearch存储开销,以及Linux开销等因素。直接通过如下公式就可以算出需要多少台Ultrawarm实例,这里以ultrawarm1.medium.elasticsearch实例(2vCPU/15.25GB/1.5TB)为例:
Ultrawarm节点数量 = 单日数据量 * (日志保留时间 – 热数据保留时间)/ Ultrawarm节点存储容量
= 1200GB * (7-1)/ 1500GB
= 5
性能监控
初始的规划需要根据我们的实际负载而调整,我们需要持续的监控Amazon Elasticsearch Service的性能指标以确定现有资源是否能满足需求。以下是一些重要的监控指标,我们需要根据指标的变化,对集群进行扩缩容:
- CPU Utilization:CPU使用率,如果CPU利用率持续保持在85%以上,考虑更换实例类型为C系,或增加数据节点。
- JVMMemoryPressure:JVM堆内存的利用率,85%以上需要考虑对集群进行横向扩容,或选择更大内存的机型。
- FreeStorageSpace:存储空间,一旦存储空间不足,尽快增加数据节点
- Threadpool*Queue:Elasticsearch的各种操作都有对应的线程池,每种线程池的大小和数据节点的processor数量相关。以Write Threadpool为例,每个数据节点的线程池的大小等于1 + # of available processors,如果写入的请求并发超过了这个线程池大小,剩下的请求就会排队,并且这个队列长度是200。一旦写入的并发高于1 + # of available processors + 200,写入请求就会被reject。因此如果发现这些线程池指标中有reject的情况,请立即增加节点数量,扩展集群整体的线程池队列长度。
总结
在本文中,我主要讲述了如何规划具有Hot-Warm架构的Amazon Elasticsearch Service集群,这些规划的方法可以帮助您快速的确定集群的规模和配置。但是世界上没有银弹,在真实的使用场景中我们需要基于规划的集群配置不断调整,模拟真实的负载进行压力测试,持续监测重要的性能指标,找到瓶颈,从而找到正确的调优方法。最后,Amazon Elasticsearch Service可以提供平滑的配置修改和扩缩容过程,降低对集群性能的影响,应对不可预期的业务负载变化。