亚马逊AWS官方博客
使用Hue玩转Amazon EMR(SparkSQL, Phoenix)和Amazon Redshift
现状
Apache Hue是一个基于 Web 的交互式SQL助手,通过它可以帮助大数据从业人员(数仓工程师,数据分析师等)与数据仓库进行SQL交互。在Amazon EMR集群启动时,通过勾选Hue进行安装。在Hue启用以后,将原先需要登录主节点进行SQL编写及提交的工作转移到web前端,不仅方便统一管理日常开发需求,而且保证了集群的接入安全性。另一方面Hue有自己独特的优势可以使用SparkSQL进行Spark任务的远程提交,相比于额外为Amazon EMR集群配置Hive on Spark,或者使用代码进行Livy远程提交这两种方式而言,大大的提升了开发和运维效率。本文也介绍了如何通过Hue整合Amazon Redshift数仓, 以及远程提交Phoenix任务同HBase交互,将Hue打造为数据仓库的统一SQL访问平台。
方案架构总览
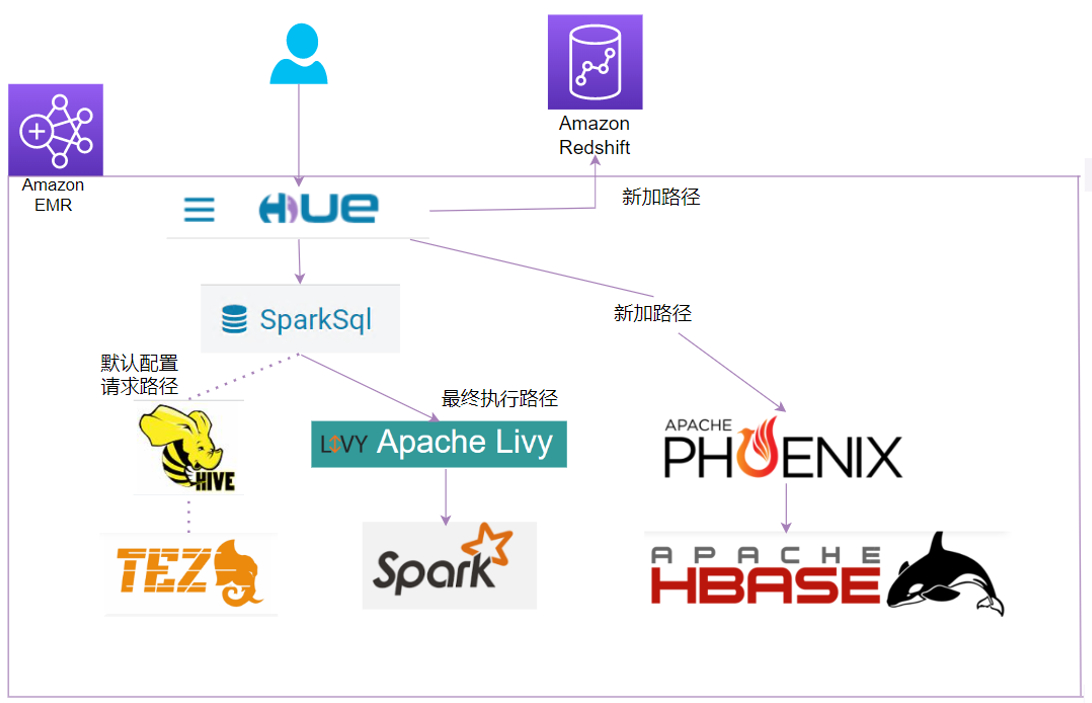
方案介绍
通过Livy提交SparkSQL Job
执行引擎现状
首先,我们简单比对一下几种流行的执行引擎的现状:
- 由于处理客户查询需要高磁盘 IO,Apache MapReduce 是最慢的查询执行引擎。
- 在保持磁盘 IO 不变的情况下,Apache Tez 明显快于 Apache MapReduce。
- Apache Spark 比没有 IO 阻塞的 Apache Tez 稍快,和Apache Tez一样以DAG方式处理数据,Spark更加通用,提供内存计算,实时流处理,机器学习等多种计算方式,适合迭代计算。
Apache Livy简介
Apache Livy 是一项服务,可通过 REST API与 Spark 集群轻松交互。此方案中的配置方式可将Hue页面编写的SparkSQL通过Livy接口提交到EMR集群。
EMR Hue处理SparkSQL默认行为
当在Hue的面板上Editor选择SparkSQL并提交SQL任务时,我们根据application_id((Executing on YARN cluster with App id application_1656071365605_0006))去Resource Manager控制台上查询到对应的Application Type是Tez:


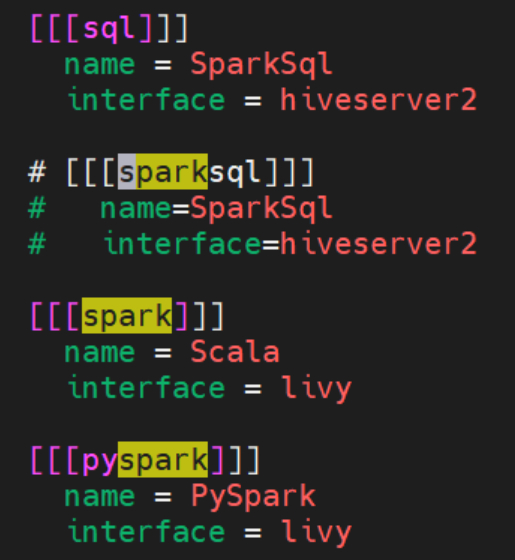
当我们打开hue的配置文件(/etc/hue/conf/hue.ini)看到[[[sql]]]处配置如下图,interface配置的是hiveserver2便知道了此时的SparkSQL走的仍是hiveserver2,因此使用的是Tez引擎(EMR上的Hive执行引擎默认是Tez),这代表着并未真的使用Spark执行引擎在运行上述的Query。
 |
在EMR Hue中通过Livy 提交SparkSQL任务
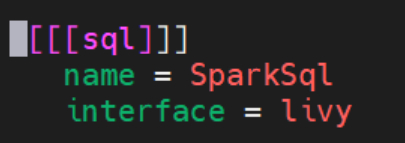
(1)修改Hue配置文件(/etc/hue/conf/hue.ini)中的执行引擎,并重启Hue服务
重新提交SparkSQL任务后,看到该Application的ApplicationType已经为SPARK。

生产场景中的性能调优:
上述Application通过Spark管理界面查看Environment细节:


看到spark.driver.memory和spark.executor.memory均设置为1G

这是因为Hue源码中直接将上述两个参数的值设定为1G:
如果用默认参数值容易在任务执行中触发OOM异常,导致任务运行失败,我们可选择通过以下方法进行调优:
将 ‘driverMemory’和 ‘executorMemory’ 的配置删除,重启Hue服务

再次运行SparkSQL,从Environment 看到两个内存参数已经更新,和/etc/spark/conf/spark-defaults.conf内定义一致:


Hue配置Phoenix提交HBase任务
Apache Phoenix简介
Apache Phoenix是一个开源的,大规模并行的关系数据库引擎,支持使用Apache HBase作为其后备存储的OLTP for Hadoop。Phoenix提供了一个JDBC驱动程序,该驱动程序隐藏了noSQL存储的复杂性,使用户能够创建,删除和更改SQL表,视图,索引和序列。
配置Phoenix
(1)准备Hue Python Virtual Environment
(2)修改Hue配置文件:
在/etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
重启Hue服务
(3) Hue页面提交Phoenix任务:
Hue – Editor 部分因为配置文件的更新,出现了HBase Phoenix的选项, 创建和查询Table:
 |

HBase显示列名乱码修正
(1)当完成上述操作时,回到HBase Shell查看表内容,发现列名为乱码:

使用Phoenix命令行(/usr/lib/phoenix/bin/sqlline.py, 不透过Hue)创建表仍能重现该问题,且乱码不会在Phoenix JDBC连接中出现:

(2)在Phoenix创建表时最后加上COLUMN_ENCODED_BYTES= 0可规避该问题:
HBase Shell查看结果,列名已经显示正常:

Hue连接Redshift提交任务
当数仓平台中涉及Amazon EMR和Amazon Redshift等多种服务时,通过Hue丰富的Connectors扩展种类,可以轻松实现统一交互的功能。
(1)准备Hue Python Virtual Environment
(2)修改Hue配置文件:
在/etc/hue/conf/hue.ini的[notebook] [[interpreters]]部分加入:
重启Hue服务
(3) Hue页面提交Redshift任务:
Hue – Editor 部分因为配置文件的更新,出现了Reshift的选项:
 |
提交SQL查询,轻松获取Amazon Redshift数仓数据:

总结
本文主要帮助使用Amazon EMR的用户,通过Hue实现统一数仓平台开发工具,一方面集中管理数仓SQL开发任务,另一方面为其它部门提供自主分析的平台,对数仓建设有一定的推动作用。