亚马逊AWS官方博客
使用 Amazon Glue 来调度 Amazon Redshift 跑 TPC-DS Benchmark
Amazon Redshift是亚马逊云科技的数据仓库产品,可以运用于各种不同的大数据场景中,实际场景中往往有一些复杂的任务依赖和性能的不确定性。本博客提供CDK代码,其中会生成Cloudformation模版搭建一个简单的环境,包括一个Redshift集群,一个Glue Workflow(见下图)包含建立Redshift表、加载TPC-DS数据到表、顺序运行TPC-DS 99个查询和并行运行TPC-DS 99个查询任务。用户需要先自行生成TPC-DS数据到S3以‘|’分隔的CSV文件。然后把S3路径提供给Cloudformation,运行完后会生成测试报告到S3。
本博客可用来:
- 自动化部署Redshift各种测试的环境
- 使用Glue Workflow来调度Redshift SQL的示例

运行CDK部署Cloudformation创建环境
前置要求
- 下载并安装CDK环境,以便运行CDK CLI CDK website
- 使用TPC-DS 生成数据并保存在S3上以 ‘|’ 分隔CSV格式(注意:S3数据和Cloudformation需要在一个区域)
- 由于CDK里面包含S3桶,所以需要CDK boostrap 命令如:cdk bootstrap
运行CDK CLI部署环境
下载CDK代码并在 RedshiftBenchmark 路径下运行CDK CLI列举当前可部署的Stack
$ cdk ls
会返回以下可部署的Stack
使用CDK CLI 部署Cloudformations使用默认参数
$ cdk deploy benchmark-workflow
如果需要部署自定义参数,例子如下
所有可以修改的参数,其中benchmark-workflow:tpcdsDataPath是需要自定义的,其他都可以选择默认:
benchmark-workflow:tpcdsDataPath(Required)存储TPCDS的S3路径,默认是 s3://redshift-downloads/TPC-DS/2.13/3TB/(桶在us-east-1,只有us-east-1能直接部署)redshift-stack:rsInstanceTypeRedshift节点类型,默认ra3.xlplusredshift-stack:rsSizeRedshift 集群大小,默认是 2redshift-stack:usernameRedshift super user 用户名,默认是 adminredshift-stack:passwordRedshift super user 密码,默认是 Admin1234benchmark-workflow:parallel并行测试的并行度,默认是 10benchmark-workflow:numRuns测试的轮次,默认是 2benchmark-workflow:numFiles需要测试的SQL个数,一共有99个但不一定需要全部测试,默认是 99
运行Glue Workflow来运行Redshift任务
到Amazon Glue的控制台的workflow中可以看到名字为redshift-benchmark的workflow如下,可以直接运行整个workflow也可以到Job页面运行单个Job,以下会逐一介绍如何运行单个任务。
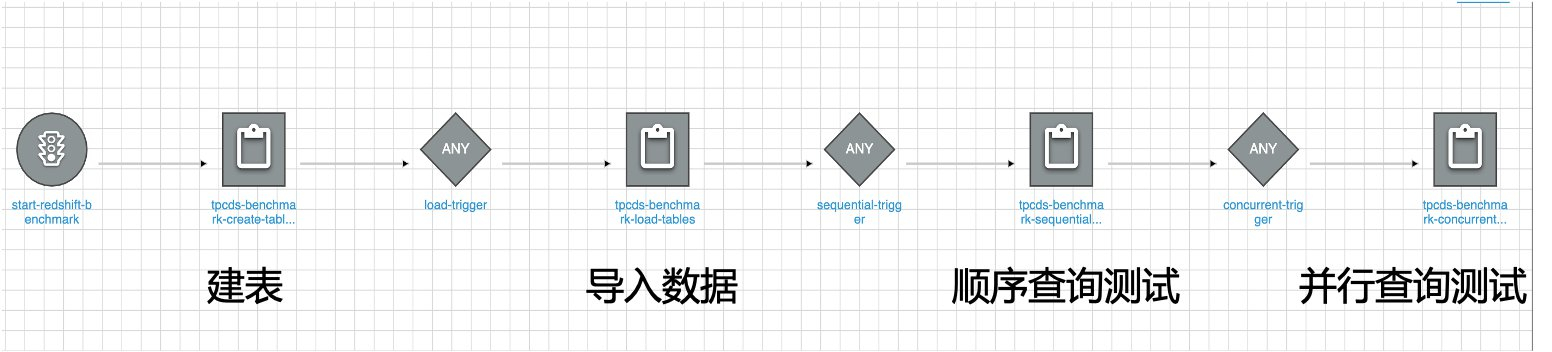
运行Glue建表和导入任务
到Glue的控制台,在Job页面找到名字为tpcds-benchmark-create-tables和tpcds-benchmark-load-tables任务,前者是建表任务,后者是使用copy从S3加载数据(S3需要已经有数据)。之前的CDK已经把TPC-DS的DDL、导入copy命令和99个查询放在S3里面,路径也自动的更新到Glue Job的传入参数上面,可以直接运行。也可以修改传入参数运行自定义的SQL。
运行Glue顺序查询测试
到Glue的控制台,在Job页面找到名字为tpcds-benchmark-sequential-report任务,本任务会使用循环顺序的执行99个TPC-DS查询(可通过修改CDK参数或者Glue Job作业参数来自定义)。执行完成后执行每个语句的运行时间会输出到Glue Job日志和CDK默认生成的S3桶中(prefix为report/)。
可修改的作业参数如下:

运行Glue并行查询测试
到Glue的控制台,在Job页面找到名字为tpcds-benchmark-concurrent-report任务,本任务会使用benchmark-workflow:parallel(或者Glue Job –parallel_level )参数指定的数值来并发的运行查询,顺序的执行每次并发。比如parallel为10,查询个数为99,则本任务会先同时提交1-10查询,运行完后再同时提交11-20查询依次进行。执行完成后执行每个语句的运行时间会输出到Glue Job日志和CDK默认生成的S3桶中(prefix为report/)。也可以通过修改CDK或者Glue Job的参数来自定义,可修改的作业参数参照顺序查询测试截图。
检查测试结果
当Glue测试任务完成后,有两种方式可以拿到测试报告:
- Glue Job控制台里可以看到
tpcds-benchmark-sequential-report,tpcds-benchmark-concurrent-report任务的日志 - CDK创建的S3 路径 例如: s3://repository-s3xxx/report/
自定义或拓展测试
本CDK生成的环境可以作为一个初始环境,基于本环境可以再深入自定义。比如:
- CDK中的redshift_scripts/路径可以替换成自己的DDL或者查询来跑自定义压测
- CDK具有传入参数,可以通过修改传入参数自定义环境
- Glue Job也有独立的参数可以修改,可以用来跑自定义的查询
- CDK有三个不同的Cloudformation Stack,他们之间有依赖关系,但也可以单独部署,可以通过修改CDK中的app.py 来自定义环境