介绍
企业组织通常需要持续处理和分析海量数据,以获得具有指导意义的数据洞察。在日志分析、应用程序搜索和企业搜索等使用场景中,有效的数据摄取和搜索功能至关重要。在这些使用场景中,需要一个能够处理大量数据并能高效探索数据的高性能管道。
Apache Spark 是一个用于大规模数据处理的强大开源工具。它具有出色的速度、可扩展性和易用性,因而广受认可。它能够处理和转换海量数据集,是现代数据工程中不可或缺的工具。Amazon OpenSearch Service 是一种社区驱动型搜索及分析解决方案。通过 Amazon OpenSearch Service 可以做到无缝搜索、聚合、可视化和分析数据。将 Spark 和 OpenSearch Service 结合使用,可以实现用于构建高效数据管道的有效解决方案。然而,难点在于如何将 Spark 中的数据摄取到 OpenSearch Service,尤其是在有多种数据源的情况下。
本文介绍如何使用 AWS Glue 中的 Spark 功能将数据无缝摄取到 OpenSearch Service 中。我们将介绍批量摄取数据的方法、展示实践操作示例并讨论最佳实践,从而帮助你基于 AWS 构建优化的且可扩展的数据管道。
难度:中级
时间:30 分钟
相关产品:AWS Glue | Amazon OpenSearch Service
上次更新时间:2025 年 1 月 13 日
解决方案概述
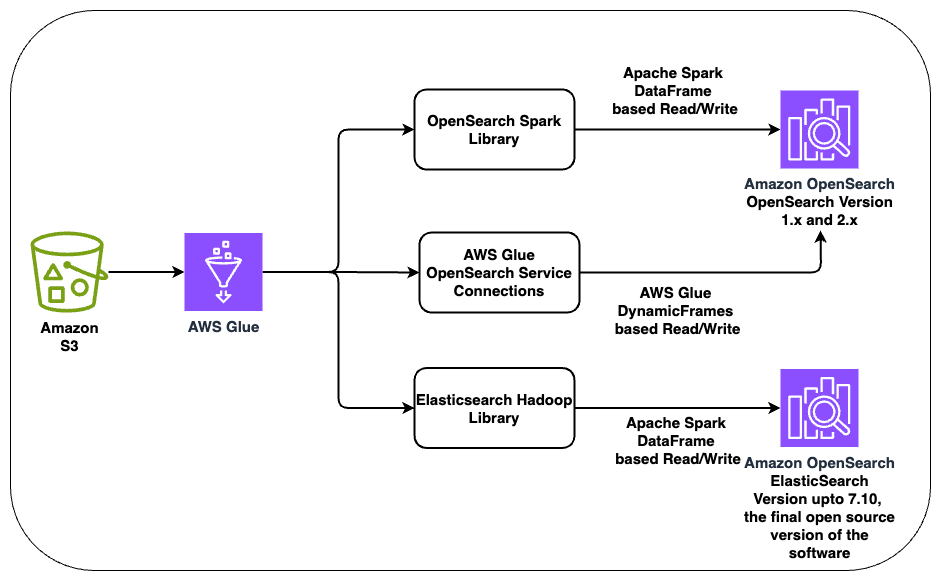
AWS Glue 是一种无服务器式数据集成服务,可以简化数据分析、机器学习和应用程序开发过程中的数据准备和数据集成任务。在本文中,我们将重点介绍如何使用 AWS Glue 上的 Spark 将批量数据摄取到 OpenSearch Service 中。
AWS Glue 支持通过多种开源库和 AWS 托管库与 OpenSearch Service 集成:
在下面的章节中,我们将详细探讨每种集成方法,并介绍设置及实现过程。在我们的示例实验过程中,我们将按照下图中所示的架构逐步构建,完整地介绍如何基于 AWS 创建强大数据管道的清晰方法。这几个实现方法都是独立的解决方案。我们将分别介绍这些集成方法,因为在实际场景中,可能只会使用这三种集成方法中的其中一种。
你可以在配套 GitHub 存储库中找到对应的代码库。在下面的章节中,我们将逐步介绍解决方案的实现步骤。
将代码库克隆到本地计算机
全部打开git clone git@github.com:aws-samples/opensearch-glue-integration-patterns.git cd opensearch-glue-integration-patterns export BLOG_DIR=$(pwd)将代码库克隆到本地计算机,并设置 BLOG_DIR 环境变量。这样,所有的相对路径都通过 BLOG_DIR 设置为你本地计算机上的代码库位置。如果不使用 BLOG_DIR,请根据实际情况调整路径。
部署 AWS CloudFormation 模板,用于创建必要的基础设施
全部打开-
运行以下命令,根据指定模板部署资源
-
在 AWS CloudFormation 控制台上,找到 GlueOpenSearchStack 堆栈,并确认其状态为 CREATE_COMPLETE。
本文将重点介绍如何使用 AWS Glue Spark 将前面介绍的几种库中的数据摄取到 OpenSearch Service 中。虽然我们的核心主题是数据摄取,但为了实现数据摄取,我们需要为集成示例预先配置几个重要 AWS 组件,包括 Amazon Virtual Private Cloud (Amazon VPC)、多个子网、AWS Key Management Service (AWS KMS) 密钥、Amazon Simple Storage Service (Amazon S3) 存储桶、AWS Glue 角色,以及一个包含 OpenSearch Service 和 Elasticsearch 域的 OpenSearch Service 集群。为了简化设置过程,我们使用 cloudformation/opensearch-glue-infrastructure.yaml 这个 AWS CloudFormation 模板自动配置这些核心基础设施。
AWS CloudFormation 模板将部署必要的网络组件(如 VPC 和子网)、Amazon CloudWatch 日志记录功能、AWS Glue 角色,以及为了实现设计的架构而必需的 OpenSearch Service 和 Elasticsearch 域。在命令中的 ESMasterUserPassword 和 OSMasterUserPassword 参数中输入强密码, 8-128 个字符,且密码必须至少包含小写字母、大写字母、数字或特殊字符中的三种,且不能包含正斜杠 (/)、引号 (") 或空格字符,并严格遵守贵企业的安全标准。
cd ${BLOG_DIR}/cloudformation/ aws cloudformation deploy \ --template-file ${BLOG_DIR}/cloudformation/opensearch-glue-infrastructure.yaml \ --stack-name GlueOpenSearchStack \ --capabilities CAPABILITY_NAMED_IAM \ --region <AWS_REGION> \ --parameter-overrides \ ESMasterUserPassword=<ES_MASTER_USER_PASSWORD> \ OSMasterUserPassword=<OS_MASTER_USER_PASSWORD>成功配置资源后,系统会显示一条成功消息,类似 "Successfully created/updated stack – GlueOpenSearchStack"。配置此 AWS CloudFormation 堆栈的过程通常需要大约 30 分钟时间。
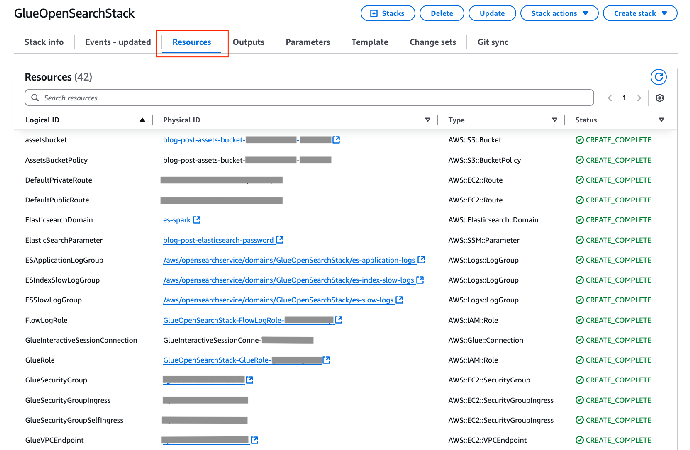
可在 Resources(资源)选项卡上,查看已部署的资源,如下截图所示。(此截图中并未显示所有已创建的资源。)
其他设置步骤
全部打开运行以下 AWS CLI 命令可以从 AWS CloudFormation 堆栈中提取输出值,并将其保存到名为 GlueOpenSearchStack_outputs.txt 的文件中。我们将在接下来的步骤中,使用此文件中的参数值。
aws cloudformation describe-stacks \ --stack-name GlueOpenSearchStack \ --query 'sort_by(Stacks[0].Outputs[], &OutputKey)[].{Key:OutputKey,Value:OutputValue}' \ --output table \ --no-cli-pager \ --region <AWS_REGION> > ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt运本文的主要目的是演示如何使用 AWS Glue 将数据摄取到 OpenSearch Service。除了数据集的数据格式(将在后文章节中介绍 AWS Glue notebook 时讨论)外,我们在这里不详细介绍数据集本身。要了解有关数据集的更多信息,请访问 NYC Taxi and Limousine Commission 网站。
注意,请务必下载 2022 年 12 月的数据集,因为我们使用的是该版本数据集对解决方案进行了测试。
S3_BUCKET_NAME=$(awk -F '|' '$2 ~ /S3Bucket/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt) mkdir -p ${BLOG_DIR}/datasets && cd ${BLOG_DIR}/datasets curl -O https://d37ci6vzurychx.cloudfront.net/trip-data/green_tripdata_2022-12.parquet aws s3 cp green_tripdata_2022-12.parquet s3://${S3_BUCKET_NAME}/datasets/green_tripdata_2022-12.parquet此实验中,为了确保流畅的部署过程体验,我们使用的是指定的 JAR 文件版本。但是,实际使用时,我们建议你务必遵循贵企业的安全最佳实践,并在执行部署前检查 JAR 文件版本中的任何已知漏洞。AWS 并不保证此实验中使用的任何开源代码的安全性。此外,请验证所下载 JAR 文件的校验和 (Checksum) 是否与公布的值一致,确认其完整性和可靠性。
mkdir -p ${BLOG_DIR}/jars && cd ${BLOG_DIR}/jars # OpenSearch Service jar curl -O https://repo1.maven.org/maven2/org/opensearch/client/opensearch-spark-30_2.12/1.0.1/opensearch-spark-30_2.12-1.0.1.jar aws s3 cp opensearch-spark-30_2.12-1.0.1.jar s3://${S3_BUCKET_NAME}/jars/opensearch-spark-30_2.12-1.0.1.jar # Elasticsearch jar curl -O https://repo1.maven.org/maven2/org/elasticsearch/elasticsearch-spark-30_2.12/7.17.23/elasticsearch-spark-30_2.12-7.17.23.jar aws s3 cp elasticsearch-spark-30_2.12-7.17.23.jar s3://${S3_BUCKET_NAME}/jars/elasticsearch-spark-30_2.12-7.17.23.jar在下面的章节中,我们将实现架构图中列出的各种数据摄取方法。
通过 OpenSearch Spark 库将数据摄取到 OpenSearch Service
全部打开-
在 AWS Glue 控制台的导航栏中,选择 ETL jobs(ETL 作业)。
-
在 Create job(创建作业)下,选择 Notebook(笔记本)。
-
在 Notebook 中的步骤 1 中,将 <GLUE-INTERACTIVE-SESSION-CONNECTION-NAME> 占位符替换为你的 AWS Glue 交互式会话连接名称。可以通过执行以下命令来获取交互式会话的名称:
cd ${BLOG_DIR} awk -F '|' '$2 ~ /GlueInteractiveSessionConnectionName/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt -
2. 在 Notebook 中的步骤 1 中,替换 <S3-BUCKET-NAME> 占位符,并存储桶名称填充到 s3_bucket 变量。可以通过执行以下命令来获取 S3 存储桶的名称:
awk -F '|' '$2 ~ /S3Bucket/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt -
3. 在 Notebook 中的步骤 4 中,将 <OPEN-SEARCH-DOMAIN-WITHOUT-HTTPS> 替换为 OpenSearch Service 域名称。可以通过执行以下命令来获取域名称:
awk -F '|' '$2 ~ /OpenSearchDomainEndpoint/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt
在本小节中,我们将介绍如何使用 Spark 和 OpenSearch Spark 库加载 OpenSearch Service 索引。我们将通过 AWS Glue 笔记本 (Notebook) 演示此实现过程。在此过程中,我们将使用用户名和密码进行基本身份验证。
为了演示数据摄取机制,我们提供了含有详细说明信息的 Spark-and-OpenSearch-Code-Steps.ipynb Notebook。执行本小节中所述的步骤时,请参阅此 Notebook 中的说明信息。
设置 AWS Glue Studio Notebook
请按以下步骤操作:

3. 3. 上传位于 ${BLOG_DIR}/glue_jobs/Spark-and-OpenSearch-Code-Steps.ipynb 的 Notebook 文件。
4. 4. 在 IAM 角色字段,选择以 GlueOpenSearchStack-GlueRole-* 开头的 AWS Glue 作业 IAM 角色。
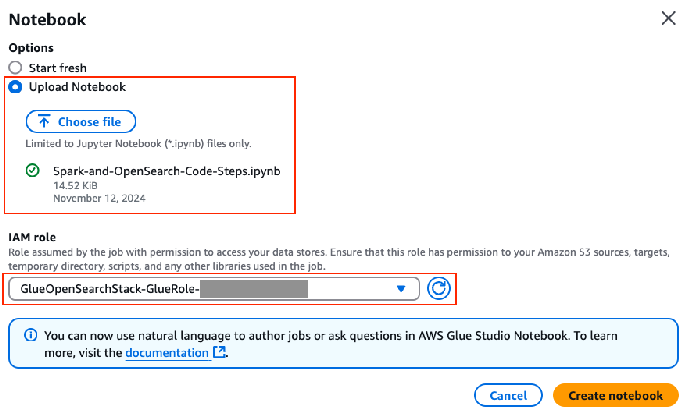
5. 5. 输入 Notebook 名称(例如 Spark-and-OpenSearch-Code-Steps),然后选择 Save(保存)。
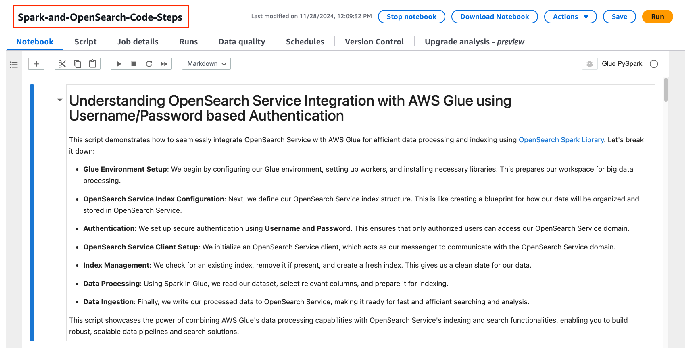
将 Notebook 中的占位符替换为实际值
完成以下步骤,将 Notebook 中的占位符替换为实际值:
运行 Notebook
运行 Notebook 中的每个单元 (Cell),将数据加载到 OpenSearch Service 域,然后读取数据,验证加载操作是否成功。有关具体的执行过程指导,请参阅 Notebook 中的详细说明。
Spark 写模式(append 和 overwrite)
建议使用 append 模式,以增量方式将数据写入 OpenSearch Service 索引,如 Notebook 中的步骤 8 所示。不过,在某些情况下,你可能需要刷新 OpenSearch Service 索引的整个数据集。这种情况下,你可以使用 overwrite 模式,但如果索引规模很大,不推荐这种方法。在使用 overwrite 模式时,Spark 库会逐一删除 OpenSearch Service 索引中的行,然后重写数据,这对于大型数据集来说可能效率不高。为避免这种情况,你可以在 Spark 中实现一个预处理步骤,用于识别插入和更新操作,然后通过 append 模式将数据写入 OpenSearch Service。
通过 Elasticsearch Hadoop 库将数据摄取到 Elasticsearch
全部打开-
在 AWS Glue 控制台的导航栏中,选择 ETL jobs(ETL 作业)。
-
在 Create job(创建作业)下,选择 Notebook(笔记本)。
-
在 Notebook 中的步骤 1 中,将 <GLUE-INTERACTIVE-SESSION-CONNECTION-NAME> 占位符替换为你的 AWS Glue 交互式会话连接名称。可以通过执行以下命令来获取交互式会话的名称:
awk -F '|' '$2 ~ /GlueInteractiveSessionConnectionName/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt -
2.在 Notebook 中的步骤 1 中,替换 <S3-BUCKET-NAME> 占位符,并存储桶名称填充到 s3_bucket 变量。可以通过执行以下命令来获取 S3 存储桶的名称:
awk -F '|' '$2 ~ /S3Bucket/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt -
3.在 Notebook 中的步骤 4 中,将 <ELASTIC-SEARCH-DOMAIN-WITHOUT-HTTPS> 替换为 Elasticsearch 域名。可以通过执行以下命令来获取域名称:
awk -F '|' '$2 ~ /ElasticsearchDomainEndpoint/ {gsub(/^[ \t]+|[ \t]+$/, "", $3); print $3}' ${BLOG_DIR}/GlueOpenSearchStack_outputs.txt
在本小节中,我们将介绍如何通过 Spark 和 Elasticsearch Hadoop 库加载 Elasticsearch 索引。我们将使用 AWS Glue Spark 引擎来演示该实现过程。
设置 AWS Glue Studio Notebook
请完成以下步骤,设置 Notebook:

3. 3. 上传位于 ${BLOG_DIR}/glue_jobs/Spark-and-Elasticsearch-Code-Steps.ipynb 的 Notebook 文件。
4. 4. 在 IAM 角色字段,选择以 GlueOpenSearchStack-GlueRole-* 开头的 AWS Glue 作业 IAM 角色。
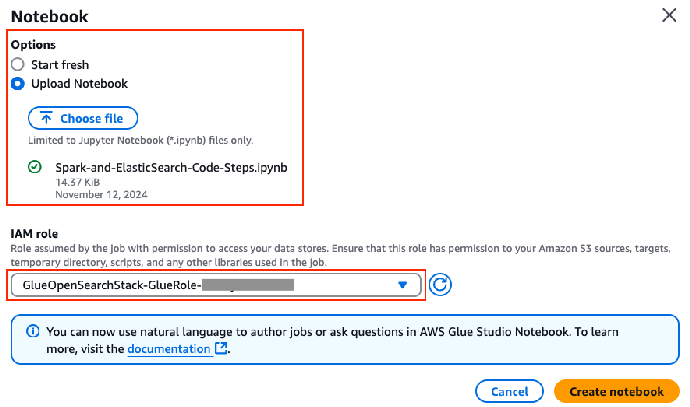
5. 5. 输入 Notebook 名称(例如 Spark-and-ElasticSearch-Code-Steps),然后选择 Save(保存)。
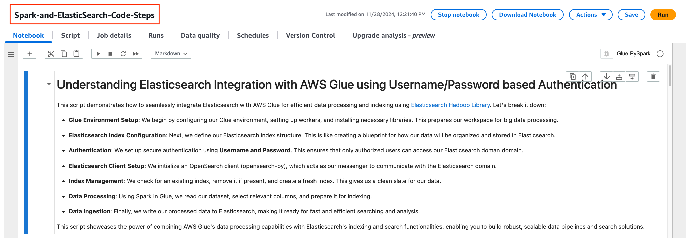
将 Notebook 中的占位符替换为实际值
请按以下步骤操作:
运行 Notebook
运行 Notebook 中的每个单元,将数据加载到 Elasticsearch 域,然后读取数据,验证加载操作是否成功。有关具体的执行过程指导,请参阅 Notebook 中的详细说明。
使用 AWS Glue OpenSearch Service 连接 (connection) 将数据摄取到 OpenSearch Service
全部打开-
在 AWS Glue 控制台的导航栏中,选择 ETL jobs(ETL 作业)。
-
在 Create job(创建作业)下,选择 Visual ETL(可视化 ETL)。
-
在 S3 source type(S3 源类型)字段,选择 S3 location(S3 位置)。
-
在 S3 URL 字段,选择 Browse S3(浏览 S3),然后从指定的 S3 存储桶中选择 green_tripdata_2022-12.parquet 文件。
-
在 Data format(数据格式)字段,选择 Parquet。
-
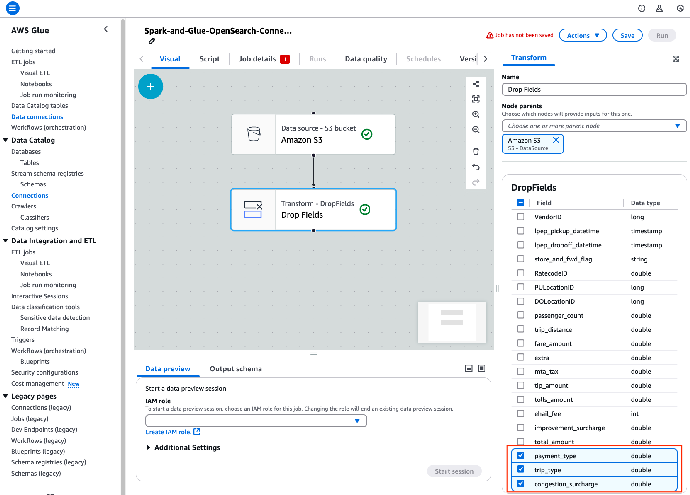
payment_type
-
trip_type
-
congestion_surcharge
-
在 Amazon OpenSearch Service connection(Amazon OpenSearch Service 连接)字段,从下拉列表中选择 GlueOpenSearchServiceConnec-* 连接。
-
在 Index(索引)字段,输入 green_taxi。在“通过 OpenSearch Spark 库将数据摄取到 OpenSearch Service”一节中,我们介绍了如何添加索引。请按照相关方法,创建 green_taxi 索引。
-
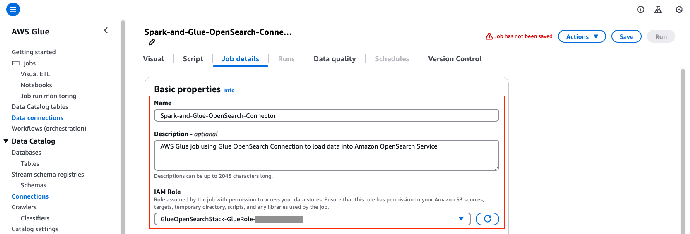
在 Name(名称)字段,输入作业名称(例如 Spark-and-Glue-OpenSearch-Connection)。
-
在 Description(描述)字段,描述该作业信息(例如 AWS Glue job using Glue OpenSearch Connection to load data into Amazon OpenSearch Service)。
-
在 IAM role(IAM 角色)字段,选择一个以 GlueOpenSearchStack-GlueRole-* 开头的角色。
-
在 Glue version(Glue 版本)字段,选择 Glue 4.0 – Supports spark 3.3, Scala 2, Python 3
-
将其余字段保留为默认设置。
-
选择 Save(保存),保存更改。
在本小节中,我们将介绍如何使用 Spark 和 AWS Glue OpenSearch Service 连接来加载 OpenSearch Service 索引。
创建 AWS Glue 作业
按照以下步骤,创建一个 AWS Glue 可视化 ETL 作业:
这将打开 AWS Glue 作业可视化编辑器。

3. 点击加号图标,然后在 Sources(源)下选择 Amazon S3。
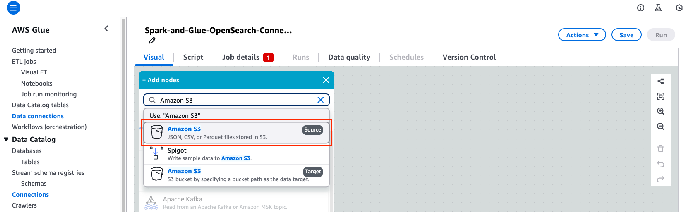
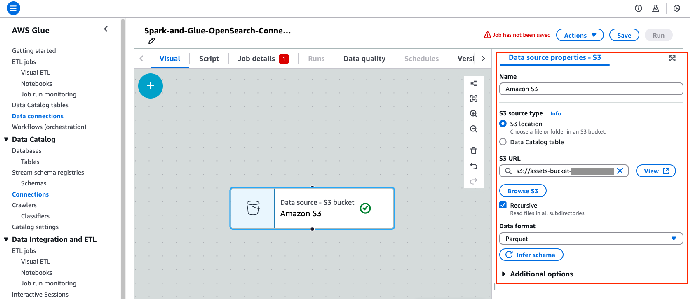
4. 在可视化编辑器中,选择 Data Source – S3 bucket(数据源 - S3 存储桶)节点。
5. 在 Data source properties – S3(数据源属性 - S3)窗格中,对数据源进行如下配置:
6. 选择 Infer schema(识别数据 Schema),让 AWS Glue 检测数据 Schema。
这样就将指定的 S3 存储桶设置为数据源。
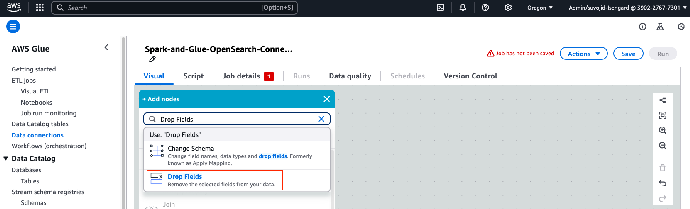
7. 再次点击加号图标,添加新节点。
8. 在 Transforms(转换)字段,选择 Drop Fields(删除字段)。
这样,你就可以在将数据集加载到 OpenSearch Service 前,从该数据集中删除任何非必要字段。
9. 选择 Drop Fields(删除字段)转换节点,然后选择数据集中的以下字段进行删除:
这样,在将数据加载到 OpenSearch Service 之前,从数据中删除这些字段。
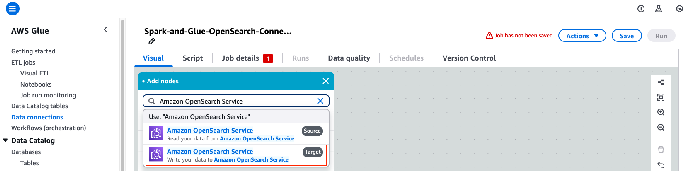
10. 再次点击加号图标,添加新节点。
11. 在 Targets(目标)字段,选择 Amazon OpenSearch Service。
这样,将 OpenSearch Service 配置为要处理的数据的传输目标。
12. 选择 Data target – Amazon OpenSearch Service 节点,并按如下所述配置此节点:
系统会按照这个节点相应地配置 OpenSearch Service,将处理后的数据写入指定的索引。
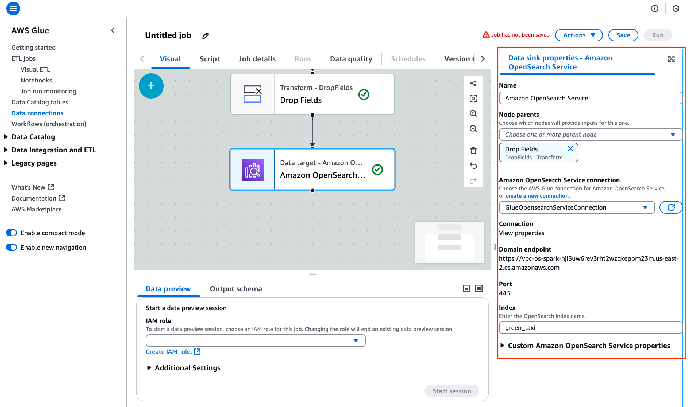
13. 在 Job details(任务详情)选项卡上,按以下所示更新作业详细信息:
14. 单击 Run(运行),运行 AWS Glue 作业 Spark-and-Glue-OpenSearch-Connector。
这将启动作业执行。
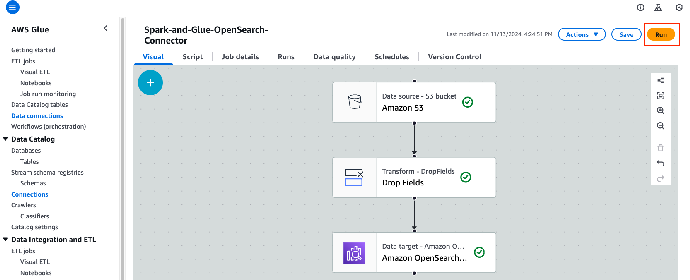
15. 选择 Runs(运行)选项卡,并等待 AWS Glue 作业成功完成。
该作业完成后,你将看到状态更改为 Succeeded(已成功)。

清理资源
实验完成后,按照以下步骤清理实验过程中创建的 AWS 资源:
-
删除 AWS CloudFormation 堆栈:
aws cloudformation delete-stack \--stack-name GlueOpenSearchStack \--region <AWS_REGION>-
删除 AWS Glue 作业:
-
在 AWS Glue 控制台导航栏中的 ETL jobs(ETL 作业)下,选择 Visual ETL(可视化 ETL)。
-
选择实验过程中创建的作业(Spark-and-Glue-OpenSearch-Connector、Spark-and-ElasticSearch-Code-Steps 和 Spark-and-OpenSearch-Code-Steps),然后在 Actions(操作)菜单上选择 Delete(删除)。
总结
在本文中,我们探讨了使用 AWS Glue Spark 将数据摄取到 OpenSearch Service 的几种方法。我们演示了如何通过以下三种数据仓库摄取数据到 OpenSearch Service 的方法:AWS Glue OpenSearch Service 连接、OpenSearch Spark 库和 Elasticsearch Hadoop 库。本文中介绍的方法可以帮助你轻松将数据摄取到 OpenSearch Service。
如果你希望了解更多信息并获得实践经验,可以参见我们提供的演习文档,其内容将详细指导你完成整个过程。你可以了解如何将数据导入 OpenSearch Service、处理批量和实时数据流以及构建仪表板的完整设置过程。请查看 Unified Real-Time Data Processing and Analytics Using Amazon OpenSearch and Apache Spark(使用 Amazon OpenSearch 和 Apache Spark 进行统一的实时数据处理和分析),帮助你加深理解并逐步应用这些技术。